 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Drop: Temporal LoRA Decoding for Efficient LLM Inference
Jan 05, 2026Autoregressive large language models (LLMs) are bottlenecked by sequential decoding, where each new token typically requires executing all transformer layers. Existing dynamic-depth and layer-skipping methods reduce this cost, but often rely on auxiliary routing mechanisms or incur accuracy degradation when bypassed layers are left uncompensated. We present \textbf{LoRA-Drop}, a plug-and-play inference framework that accelerates decoding by applying a \emph{temporal compute schedule} to a fixed subset of intermediate layers: on most decoding steps, selected layers reuse the previous-token hidden state and apply a low-rank LoRA correction, while periodic \emph{refresh} steps execute the full model to prevent drift. LoRA-Drop requires no routing network, is compatible with standard KV caching, and can reduce KV-cache footprint by skipping KV updates in droppable layers during LoRA steps and refreshing periodically. Across \textbf{LLaMA2-7B}, \textbf{LLaMA3-8B}, \textbf{Qwen2.5-7B}, and \textbf{Qwen2.5-14B}, LoRA-Drop achieves up to \textbf{2.6$\times$ faster decoding} and \textbf{45--55\% KV-cache reduction} while staying within \textbf{0.5 percentage points (pp)} of baseline accuracy. Evaluations on reasoning (GSM8K, MATH, BBH), code generation (HumanEval, MBPP), and long-context/multilingual benchmarks (LongBench, XNLI, XCOPA) identify a consistent \emph{safe zone} of scheduling configurations that preserves quality while delivering substantial efficiency gains, providing a simple path toward adaptive-capacity inference in LLMs. Codes are available at https://github.com/hosseinbv/LoRA-Drop.git.
No Pose Estimation? No Problem: Pose-Agnostic and Instance-Aware Test-Time Adaptation for Monocular Depth Estimation
Nov 07, 2025Monocular depth estimation (MDE), inferring pixel-level depths in single RGB images from a monocular camera, plays a crucial and pivotal role in a variety of AI applications demanding a three-dimensional (3D) topographical scene. In the real-world scenarios, MDE models often need to be deployed in environments with different conditions from those for training. Test-time (domain) adaptation (TTA) is one of the compelling and practical approaches to address the issue. Although there have been notable advancements in TTA for MDE, particularly in a self-supervised manner, existing methods are still ineffective and problematic when applied to diverse and dynamic environments. To break through this challenge, we propose a novel and high-performing TTA framework for MDE, named PITTA. Our approach incorporates two key innovative strategies: (i) pose-agnostic TTA paradigm for MDE and (ii) instance-aware image masking. Specifically, PITTA enables highly effective TTA on a pretrained MDE network in a pose-agnostic manner without resorting to any camera pose information. Besides, our instance-aware masking strategy extracts instance-wise masks for dynamic objects (e.g., vehicles, pedestrians, etc.) from a segmentation mask produced by a pretrained panoptic segmentation network, by removing static objects including background components. To further boost performance, we also present a simple yet effective edge extraction methodology for the input image (i.e., a single monocular image) and depth map. Extensive experimental evaluations on DrivingStereo and Waymo datasets with varying environmental conditions demonstrate that our proposed framework, PITTA, surpasses the existing state-of-the-art techniques with remarkable performance improvements in MDE during TTA.
Memory- and Latency-Constrained Inference of Large Language Models via Adaptive Split Computing
Nov 06, 2025Large language models (LLMs) have achieved near-human performance across diverse reasoning tasks, yet their deployment on resource-constrained Internet-of-Things (IoT) devices remains impractical due to massive parameter footprints and memory-intensive autoregressive decoding. While split computing offers a promising solution by partitioning model execution between edge devices and cloud servers, existing approaches fail to address the unique challenges of autoregressive inference, particularly the iterative token generation process and expanding key-value (KV) cache requirements. This work introduces the first autoregressive-aware split computing framework designed explicitly for LLM deployment on edge devices. Our approach makes three key contributions. First, we develop one-point split compression (OPSC), a mixed-precision quantization scheme that prevents out-of-memory failures by strategically partitioning models into front-end and back-end segments with different precision levels. Second, we propose a two-stage intermediate compression pipeline that combines threshold splitting (TS) and token-wise adaptive bit quantization (TAB-Q) to preserve accuracy-critical activations while dramatically reducing communication overhead. Third, we formulate a unified optimization framework that jointly selects optimal split points, quantization settings, and sequence lengths to satisfy strict memory and latency constraints. Extensive evaluations across diverse LLMs and hardware platforms demonstrate superior performance compared to state-of-the-art quantization methods, including SmoothQuant, OmniQuant, and Atom. The framework achieves a 1.49 inference speedup and significant communication overhead reduction while maintaining or improving model accuracy.
H2-Cache: A Novel Hierarchical Dual-Stage Cache for High-Performance Acceleration of Generative Diffusion Models
Oct 31, 2025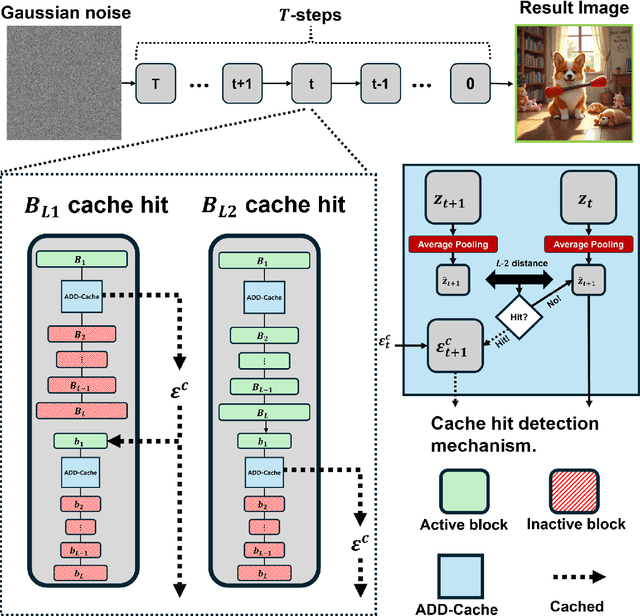



Diffusion models have emerged as state-of-the-art in image generation, but their practical deployment is hindered by the significant computational cost of their iterative denoising process. While existing caching techniques can accelerate inference, they often create a challenging trade-off between speed and fidelity, suffering from quality degradation and high computational overhead. To address these limitations, we introduce H2-Cache, a novel hierarchical caching mechanism designed for modern generative diffusion model architectures. Our method is founded on the key insight that the denoising process can be functionally separated into a structure-defining stage and a detail-refining stage. H2-cache leverages this by employing a dual-threshold system, using independent thresholds to selectively cache each stage. To ensure the efficiency of our dual-check approach, we introduce pooled feature summarization (PFS), a lightweight technique for robust and fast similarity estimation. Extensive experiments on the Flux architecture demonstrate that H2-cache achieves significant acceleration (up to 5.08x) while maintaining image quality nearly identical to the baseline, quantitatively and qualitatively outperforming existing caching methods. Our work presents a robust and practical solution that effectively resolves the speed-quality dilemma, significantly lowering the barrier for the real-world application of high-fidelity diffusion models. Source code is available at https://github.com/Bluear7878/H2-cache-A-Hierarchical-Dual-Stage-Cache.
GLYPH-SR: Can We Achieve Both High-Quality Image Super-Resolution and High-Fidelity Text Recovery via VLM-guided Latent Diffusion Model?
Oct 30, 2025Image super-resolution(SR) is fundamental to many vision system-from surveillance and autonomy to document analysis and retail analytics-because recovering high-frequency details, especially scene-text, enables reliable downstream perception. Scene-text, i.e., text embedded in natural images such as signs, product labels, and storefronts, often carries the most actionable information; when characters are blurred or hallucinated, optical character recognition(OCR) and subsequent decisions fail even if the rest of the image appears sharp. Yet previous SR research has often been tuned to distortion (PSNR/SSIM) or learned perceptual metrics (LIPIS, MANIQA, CLIP-IQA, MUSIQ) that are largely insensitive to character-level errors. Furthermore, studies that do address text SR often focus on simplified benchmarks with isolated characters, overlooking the challenges of text within complex natural scenes. As a result, scene-text is effectively treated as generic texture. For SR to be effective in practical deployments, it is therefore essential to explicitly optimize for both text legibility and perceptual quality. We present GLYPH-SR, a vision-language-guided diffusion framework that aims to achieve both objectives jointly. GLYPH-SR utilizes a Text-SR Fusion ControlNet(TS-ControlNet) guided by OCR data, and a ping-pong scheduler that alternates between text- and scene-centric guidance. To enable targeted text restoration, we train these components on a synthetic corpus while keeping the main SR branch frozen. Across SVT, SCUT-CTW1500, and CUTE80 at x4, and x8, GLYPH-SR improves OCR F1 by up to +15.18 percentage points over diffusion/GAN baseline (SVT x8, OpenOCR) while maintaining competitive MANIQA, CLIP-IQA, and MUSIQ. GLYPH-SR is designed to satisfy both objectives simultaneously-high readability and high visual realism-delivering SR that looks right and reds right.
Autoencoder-Based Hybrid Replay for Class-Incremental Learning
May 09, 2025In class-incremental learning (CIL), effective incremental learning strategies are essential to mitigate task confusion and catastrophic forgetting, especially as the number of tasks $t$ increases. Current exemplar replay strategies impose $\mathcal{O}(t)$ memory/compute complexities. We propose an autoencoder-based hybrid replay (AHR) strategy that leverages our new hybrid autoencoder (HAE) to function as a compressor to alleviate the requirement for large memory, achieving $\mathcal{O}(0.1 t)$ at the worst case with the computing complexity of $\mathcal{O}(t)$ while accomplishing state-of-the-art performance. The decoder later recovers the exemplar data stored in the latent space, rather than in raw format. Additionally, HAE is designed for both discriminative and generative modeling, enabling classification and replay capabilities, respectively. HAE adopts the charged particle system energy minimization equations and repulsive force algorithm for the incremental embedding and distribution of new class centroids in its latent space. Our results demonstrate that AHR consistently outperforms recent baselines across multiple benchmarks while operating with the same memory/compute budgets. The source code is included in the supplementary material and will be open-sourced upon publication.
Federated Class-Incremental Learning: A Hybrid Approach Using Latent Exemplars and Data-Free Techniques to Address Local and Global Forgetting
Jan 26, 2025Federated Class-Incremental Learning (FCIL) refers to a scenario where a dynamically changing number of clients collaboratively learn an ever-increasing number of incoming tasks. FCIL is known to suffer from local forgetting due to class imbalance at each client and global forgetting due to class imbalance across clients. We develop a mathematical framework for FCIL that formulates local and global forgetting. Then, we propose an approach called Hybrid Rehearsal (HR), which utilizes latent exemplars and data-free techniques to address local and global forgetting, respectively. HR employs a customized autoencoder designed for both data classification and the generation of synthetic data. To determine the embeddings of new tasks for all clients in the latent space of the encoder, the server uses the Lennard-Jones Potential formulations. Meanwhile, at the clients, the decoder decodes the stored low-dimensional latent space exemplars back to the high-dimensional input space, used to address local forgetting. To overcome global forgetting, the decoder generates synthetic data. Furthermore, our mathematical framework proves that our proposed approach HR can, in principle, tackle the two local and global forgetting challenges. In practice, extensive experiments demonstrate that while preserving privacy, our proposed approach outperforms the state-of-the-art baselines on multiple FCIL benchmarks with low compute and memory footprints.
Task Confusion and Catastrophic Forgetting in Class-Incremental Learning: A Mathematical Framework for Discriminative and Generative Modelings
Oct 28, 2024



In class-incremental learning (class-IL), models must classify all previously seen classes at test time without task-IDs, leading to task confusion. Despite being a key challenge, task confusion lacks a theoretical understanding. We present a novel mathematical framework for class-IL and prove the Infeasibility Theorem, showing optimal class-IL is impossible with discriminative modeling due to task confusion. However, we establish the Feasibility Theorem, demonstrating that generative modeling can achieve optimal class-IL by overcoming task confusion. We then assess popular class-IL strategies, including regularization, bias-correction, replay, and generative classifier, using our framework. Our analysis suggests that adopting generative modeling, either for generative replay or direct classification (generative classifier), is essential for optimal class-IL.
SoccerNet 2024 Challenges Results
Sep 16, 2024

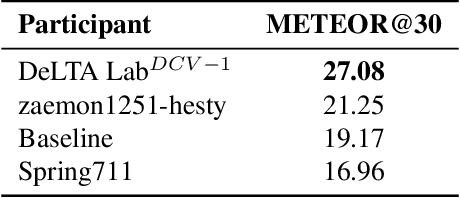
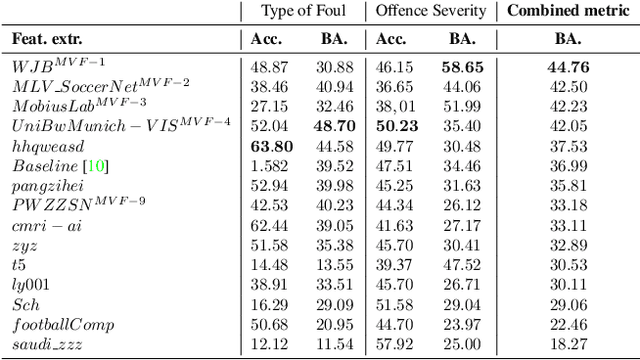
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Deep Learning for Multi-User MIMO Systems: Joint Design of Pilot, Limited Feedback, and Precoding
Sep 21, 2022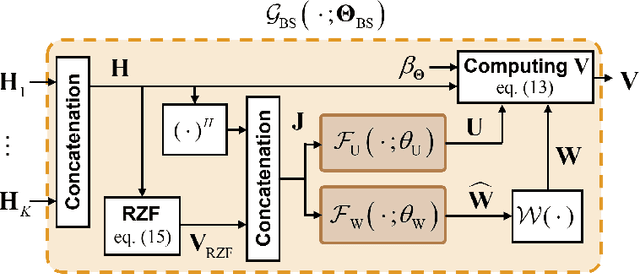
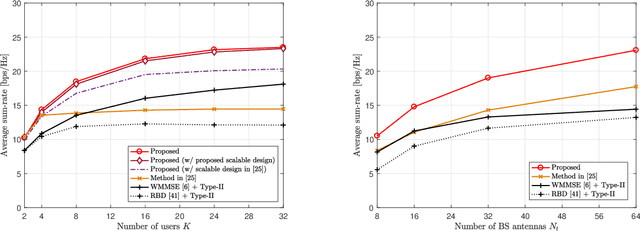
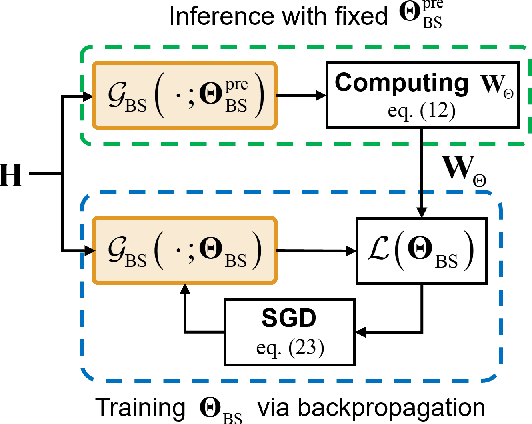
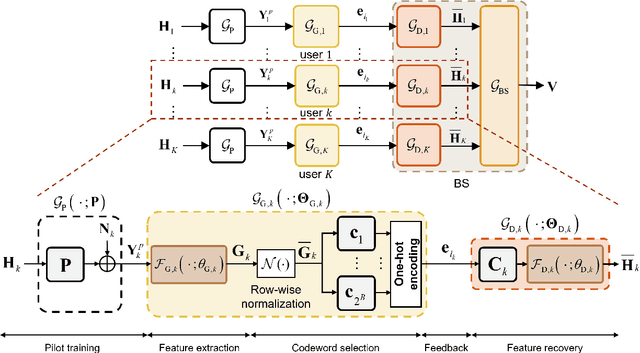
In conventional multi-user multiple-input multiple-output (MU-MIMO) systems with frequency division duplexing (FDD), channel acquisition and precoder optimization processes have been designed separately although they are highly coupled. This paper studies an end-to-end design of downlink MU-MIMO systems which include pilot sequences, limited feedback, and precoding. To address this problem, we propose a novel deep learning (DL) framework which jointly optimizes the feedback information generation at users and the precoder design at a base station (BS). Each procedure in the MU-MIMO systems is replaced by intelligently designed multiple deep neural networks (DNN) units. At the BS, a neural network generates pilot sequences and helps the users obtain accurate channel state information. At each user, the channel feedback operation is carried out in a distributed manner by an individual user DNN. Then, another BS DNN collects feedback information from the users and determines the MIMO precoding matrices. A joint training algorithm is proposed to optimize all DNN units in an end-to-end manner. In addition, a training strategy which can avoid retraining for different network sizes for a scalable design is proposed. Numerical results demonstrate the effectiveness of the proposed DL framework compared to classical optimization techniques and other conventional DNN schemes.