 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Band-Limited Adversarial Surfaces Using Neural Networks
Nov 14, 2021
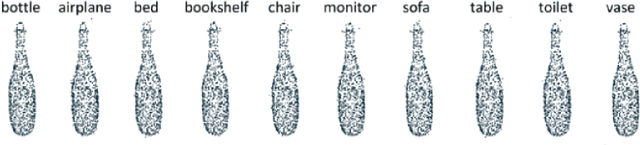
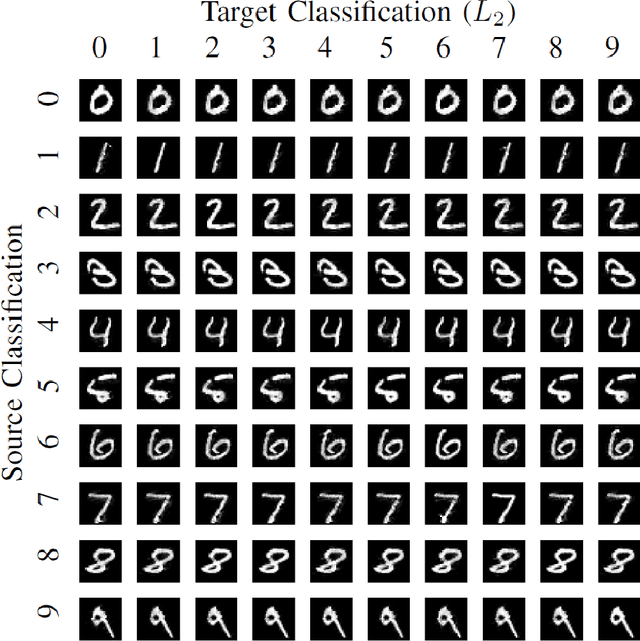
Generating adversarial examples is the art of creating a noise that is added to an input signal of a classifying neural network, and thus changing the network's classification, while keeping the noise as tenuous as possible. While the subject is well-researched in the 2D regime, it is lagging behind in the 3D regime, i.e. attacking a classifying network that works on 3D point-clouds or meshes and, for example, classifies the pose of people's 3D scans. As of now, the vast majority of papers that describe adversarial attacks in this regime work by methods of optimization. In this technical report we suggest a neural network that generates the attacks. This network utilizes PointNet's architecture with some alterations. While the previous articles on which we based our work on have to optimize each shape separately, i.e. tailor an attack from scratch for each individual input without any learning, we attempt to create a unified model that can deduce the needed adversarial example with a single forward run.
The Whole Is Greater Than the Sum of Its Nonrigid Parts
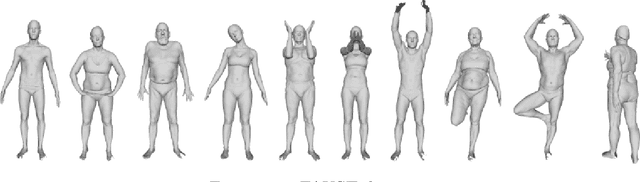
Jan 27, 2020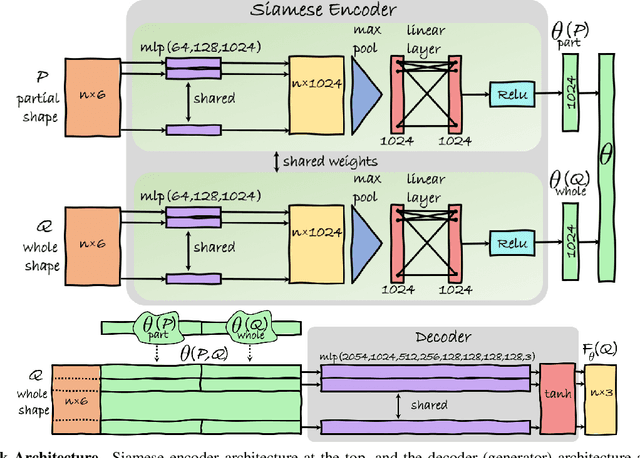

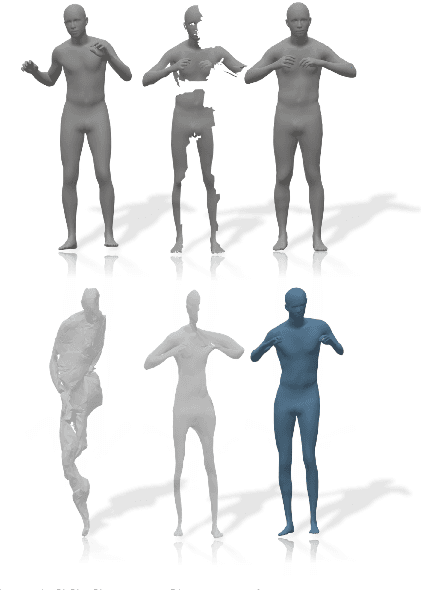

According to Aristotle, a philosopher in Ancient Greece, "the whole is greater than the sum of its parts". This observation was adopted to explain human perception by the Gestalt psychology school of thought in the twentieth century. Here, we claim that observing part of an object which was previously acquired as a whole, one could deal with both partial matching and shape completion in a holistic manner. More specifically, given the geometry of a full, articulated object in a given pose, as well as a partial scan of the same object in a different pose, we address the problem of matching the part to the whole while simultaneously reconstructing the new pose from its partial observation. Our approach is data-driven, and takes the form of a Siamese autoencoder without the requirement of a consistent vertex labeling at inference time; as such, it can be used on unorganized point clouds as well as on triangle meshes. We demonstrate the practical effectiveness of our model in the applications of single-view deformable shape completion and dense shape correspondence, both on synthetic and real-world geometric data, where we outperform prior work on these tasks by a large margin.