 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity of Autoregressive Reasoning: Chain-of-Thought vs. End-to-End
Apr 13, 2026Modern large language models generate text autoregressively, producing tokens one at a time. To study the learnability of such systems, Joshi et al. (COLT 2025) introduced a PAC-learning framework for next-token generators, the primitive underlying autoregressive models. In this framework, an unknown next-token generator maps a sequence of tokens to the next token and is iteratively applied for $T$ steps, producing a chain of tokens whose final token constitutes the model's output. The learning task is to learn the input-output mapping induced by this autoregressive process. Depending on the available supervision, training examples may reveal only the final output (End-to-End supervision) or the entire generated chain (Chain-of-Thought supervision). This raises two natural questions: how the sample complexity depends on the generation length $T$, and how much Chain-of-Thought supervision can reduce this dependence. In this work we give a nearly complete answer to both questions by uncovering a taxonomy of how the sample complexity scales with $T$. For End-to-End learning, we show that the landscape is remarkably rich: subject to mild conditions, essentially any growth rate $r(T)$ between constant and linear can arise as the sample complexity, and combined with the linear upper bound of Joshi et al., this yields an essentially complete characterization. In contrast, under Chain-of-Thought supervision we show that the sample complexity is independent of $T$, demonstrating that access to intermediate reasoning steps can eliminate the dependence on the generation length altogether. Our analysis introduces new combinatorial tools, and as corollaries we resolve several open questions posed by Joshi et al. regarding the dependence of learnability on the generation length and the role of Chain-of-Thought supervision.
Online Realizable Regression and Applications for ReLU Networks
Feb 22, 2026Realizable online regression can behave very differently from online classification. Even without any margin or stochastic assumptions, realizability may enforce horizon-free (finite) cumulative loss under metric-like losses, even when the analogous classification problem has an infinite mistake bound. We study realizable online regression in the adversarial model under losses that satisfy an approximate triangle inequality (approximate pseudo-metrics). Recent work of Attias et al. shows that the minimax realizable cumulative loss is characterized by the scaled Littlestone/online dimension $\mathbb{D}_{\mathrm{onl}}$, but this quantity can be difficult to analyze. Our main contribution is a generic potential method that upper bounds $\mathbb{D}_{\mathrm{onl}}$ by a concrete Dudley-type entropy integral that depends only on covering numbers of the hypothesis class under the induced sup pseudo-metric. We define an \emph{entropy potential} $Φ(\mathcal{H})=\int_{0}^{diam(\mathcal{H})} \log N(\mathcal{H},\varepsilon)\,d\varepsilon$, where $N(\mathcal{H},\varepsilon)$ is the $\varepsilon$-covering number of $\mathcal{H}$, and show that for every $c$-approximate pseudo-metric loss, $\mathbb{D}_{\mathrm{onl}}(\mathcal{H})\le O(c)\,Φ(\mathcal{H})$. In particular, polynomial metric entropy implies $Φ(\mathcal{H})<\infty$ and hence a horizon-free realizable cumulative-loss bound with transparent dependence on effective dimension. We illustrate the method on two families. We prove a sharp $q$-vs.-$d$ dichotomy for realizable online learning (finite and efficiently achievable $Θ_{d,q}(L^d)$ total loss for $L$-Lipschitz regression iff $q>d$, otherwise infinite), and for bounded-norm $k$-ReLU networks separate regression (finite loss, even $\widetilde O(k^2)$, and $O(1)$ for one ReLU) from classification (impossible already for $k=2,d=1$).
Most Convolutional Networks Suffer from Small Adversarial Perturbations
Feb 03, 2026The existence of adversarial examples is relatively understood for random fully connected neural networks, but much less so for convolutional neural networks (CNNs). The recent work [Daniely, 2025] establishes that adversarial examples can be found in CNNs, in some non-optimal distance from the input. We extend over this work and prove that adversarial examples in random CNNs with input dimension $d$ can be found already in $\ell_2$-distance of order $\lVert x \rVert /\sqrt{d}$ from the input $x$, which is essentially the nearest possible. We also show that such adversarial small perturbations can be found using a single step of gradient descent. To derive our results we use Fourier decomposition to efficiently bound the singular values of a random linear convolutional operator, which is the main ingredient of a CNN layer. This bound might be of independent interest.
Online Learning of Neural Networks
May 14, 2025



We study online learning of feedforward neural networks with the sign activation function that implement functions from the unit ball in $\mathbb{R}^d$ to a finite label set $\{1, \ldots, Y\}$. First, we characterize a margin condition that is sufficient and in some cases necessary for online learnability of a neural network: Every neuron in the first hidden layer classifies all instances with some margin $\gamma$ bounded away from zero. Quantitatively, we prove that for any net, the optimal mistake bound is at most approximately $\mathtt{TS}(d,\gamma)$, which is the $(d,\gamma)$-totally-separable-packing number, a more restricted variation of the standard $(d,\gamma)$-packing number. We complement this result by constructing a net on which any learner makes $\mathtt{TS}(d,\gamma)$ many mistakes. We also give a quantitative lower bound of approximately $\mathtt{TS}(d,\gamma) \geq \max\{1/(\gamma \sqrt{d})^d, d\}$ when $\gamma \geq 1/2$, implying that for some nets and input sequences every learner will err for $\exp(d)$ many times, and that a dimension-free mistake bound is almost always impossible. To remedy this inevitable dependence on $d$, it is natural to seek additional natural restrictions to be placed on the network, so that the dependence on $d$ is removed. We study two such restrictions. The first is the multi-index model, in which the function computed by the net depends only on $k \ll d$ orthonormal directions. We prove a mistake bound of approximately $(1.5/\gamma)^{k + 2}$ in this model. The second is the extended margin assumption. In this setting, we assume that all neurons (in all layers) in the network classify every ingoing input from previous layer with margin $\gamma$ bounded away from zero. In this model, we prove a mistake bound of approximately $(\log Y)/ \gamma^{O(L)}$, where L is the depth of the network.
Deterministic Apple Tasting
Oct 14, 2024
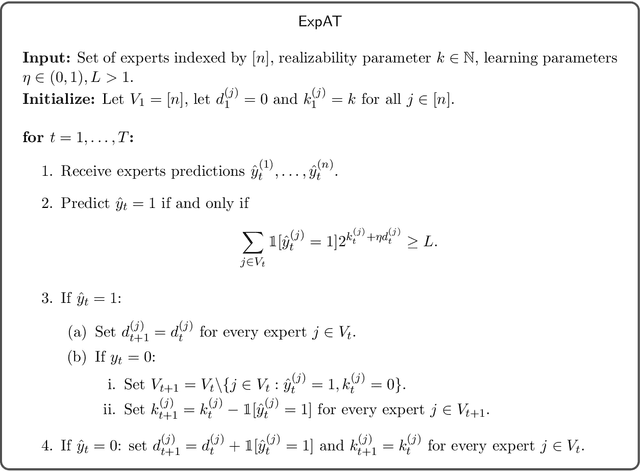


In binary ($0/1$) online classification with apple tasting feedback, the learner receives feedback only when predicting $1$. Besides some degenerate learning tasks, all previously known learning algorithms for this model are randomized. Consequently, prior to this work it was unknown whether deterministic apple tasting is generally feasible. In this work, we provide the first widely-applicable deterministic apple tasting learner, and show that in the realizable case, a hypothesis class is learnable if and only if it is deterministically learnable, confirming a conjecture of [Raman, Subedi, Raman, Tewari-24]. Quantitatively, we show that every class $\mathcal{H}$ is learnable with mistake bound $O \left(\sqrt{\mathtt{L}(\mathcal{H}) T \log T} \right)$ (where $\mathtt{L}(\mathcal{H})$ is the Littlestone dimension of $\mathcal{H}$), and that this is tight for some classes. We further study the agnostic case, in which the best hypothesis makes at most $k$ many mistakes, and prove a trichotomy stating that every class $\mathcal{H}$ must be either easy, hard, or unlearnable. Easy classes have (both randomized and deterministic) mistake bound $\Theta_{\mathcal{H}}(k)$. Hard classes have randomized mistake bound $\tilde{\Theta}_{\mathcal{H}} \left(k + \sqrt{T} \right)$, and deterministic mistake bound $\tilde{\Theta}_{\mathcal{H}} \left(\sqrt{k \cdot T} \right)$, where $T$ is the time horizon. Unlearnable classes have (both randomized and deterministic) mistake bound $\Theta(T)$. Our upper bound is based on a deterministic algorithm for learning from expert advice with apple tasting feedback, a problem interesting in its own right. For this problem, we show that the optimal deterministic mistake bound is $\Theta \left(\sqrt{T (k + \log n)} \right)$ for all $k$ and $T \leq n \leq 2^T$, where $n$ is the number of experts.
Bandit-Feedback Online Multiclass Classification: Variants and Tradeoffs
Feb 12, 2024Consider the domain of multiclass classification within the adversarial online setting. What is the price of relying on bandit feedback as opposed to full information? To what extent can an adaptive adversary amplify the loss compared to an oblivious one? To what extent can a randomized learner reduce the loss compared to a deterministic one? We study these questions in the mistake bound model and provide nearly tight answers. We demonstrate that the optimal mistake bound under bandit feedback is at most $O(k)$ times higher than the optimal mistake bound in the full information case, where $k$ represents the number of labels. This bound is tight and provides an answer to an open question previously posed and studied by Daniely and Helbertal ['13] and by Long ['17, '20], who focused on deterministic learners. Moreover, we present nearly optimal bounds of $\tilde{\Theta}(k)$ on the gap between randomized and deterministic learners, as well as between adaptive and oblivious adversaries in the bandit feedback setting. This stands in contrast to the full information scenario, where adaptive and oblivious adversaries are equivalent, and the gap in mistake bounds between randomized and deterministic learners is a constant multiplicative factor of $2$. In addition, our results imply that in some cases the optimal randomized mistake bound is approximately the square-root of its deterministic parallel. Previous results show that this is essentially the smallest it can get.
Optimal Prediction Using Expert Advice and Randomized Littlestone Dimension
Feb 27, 2023A classical result in online learning characterizes the optimal mistake bound achievable by deterministic learners using the Littlestone dimension (Littlestone '88). We prove an analogous result for randomized learners: we show that the optimal expected mistake bound in learning a class $\mathcal{H}$ equals its randomized Littlestone dimension, which is the largest $d$ for which there exists a tree shattered by $\mathcal{H}$ whose average depth is $2d$. We further study optimal mistake bounds in the agnostic case, as a function of the number of mistakes made by the best function in $\mathcal{H}$, denoted by $k$. We show that the optimal randomized mistake bound for learning a class with Littlestone dimension $d$ is $k + \Theta (\sqrt{k d} + d )$. This also implies an optimal deterministic mistake bound of $2k + O (\sqrt{k d} + d )$, thus resolving an open question which was studied by Auer and Long ['99]. As an application of our theory, we revisit the classical problem of prediction using expert advice: about 30 years ago Cesa-Bianchi, Freund, Haussler, Helmbold, Schapire and Warmuth studied prediction using expert advice, provided that the best among the $n$ experts makes at most $k$ mistakes, and asked what are the optimal mistake bounds. Cesa-Bianchi, Freund, Helmbold, and Warmuth ['93, '96] provided a nearly optimal bound for deterministic learners, and left the randomized case as an open problem. We resolve this question by providing an optimal learning rule in the randomized case, and showing that its expected mistake bound equals half of the deterministic bound, up to negligible additive terms. This improves upon previous works by Cesa-Bianchi, Freund, Haussler, Helmbold, Schapire and Warmuth ['93, '97], by Abernethy, Langford, and Warmuth ['06], and by Br\^anzei and Peres ['19], which handled the regimes $k \ll \log n$ or $k \gg \log n$.
On Optimal Learning Under Targeted Data Poisoning
Oct 12, 2022

Consider the task of learning a hypothesis class $\mathcal{H}$ in the presence of an adversary that can replace up to an $\eta$ fraction of the examples in the training set with arbitrary adversarial examples. The adversary aims to fail the learner on a particular target test point $x$ which is known to the adversary but not to the learner. In this work we aim to characterize the smallest achievable error $\epsilon=\epsilon(\eta)$ by the learner in the presence of such an adversary in both realizable and agnostic settings. We fully achieve this in the realizable setting, proving that $\epsilon=\Theta(\mathtt{VC}(\mathcal{H})\cdot \eta)$, where $\mathtt{VC}(\mathcal{H})$ is the VC dimension of $\mathcal{H}$. Remarkably, we show that the upper bound can be attained by a deterministic learner. In the agnostic setting we reveal a more elaborate landscape: we devise a deterministic learner with a multiplicative regret guarantee of $\epsilon \leq C\cdot\mathtt{OPT} + O(\mathtt{VC}(\mathcal{H})\cdot \eta)$, where $C > 1$ is a universal numerical constant. We complement this by showing that for any deterministic learner there is an attack which worsens its error to at least $2\cdot \mathtt{OPT}$. This implies that a multiplicative deterioration in the regret is unavoidable in this case. Finally, the algorithms we develop for achieving the optimal rates are inherently improper. Nevertheless, we show that for a variety of natural concept classes, such as linear classifiers, it is possible to retain the dependence $\epsilon=\Theta_{\mathcal{H}}(\eta)$ by a proper algorithm in the realizable setting. Here $\Theta_{\mathcal{H}}$ conceals a polynomial dependence on $\mathtt{VC}(\mathcal{H})$.
A Resilient Distributed Boosting Algorithm
Jun 13, 2022Given a learning task where the data is distributed among several parties, communication is one of the fundamental resources which the parties would like to minimize. We present a distributed boosting algorithm which is resilient to a limited amount of noise. Our algorithm is similar to classical boosting algorithms, although it is equipped with a new component, inspired by Impagliazzo's hard-core lemma [Impagliazzo95], adding a robustness quality to the algorithm. We also complement this result by showing that resilience to any asymptotically larger noise is not achievable by a communication-efficient algorithm.