 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation
Sep 06, 2018

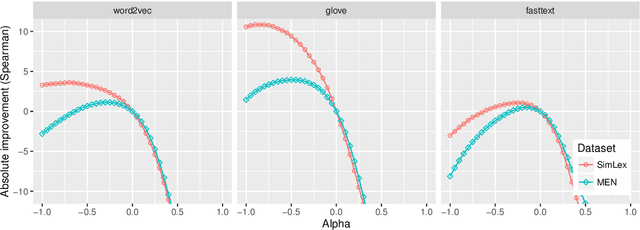
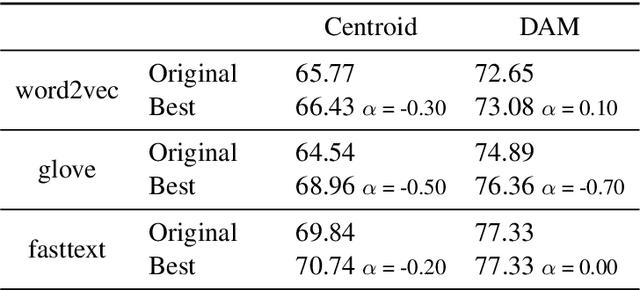
Following the recent success of word embeddings, it has been argued that there is no such thing as an ideal representation for words, as different models tend to capture divergent and often mutually incompatible aspects like semantics/syntax and similarity/relatedness. In this paper, we show that each embedding model captures more information than directly apparent. A linear transformation that adjusts the similarity order of the model without any external resource can tailor it to achieve better results in those aspects, providing a new perspective on how embeddings encode divergent linguistic information. In addition, we explore the relation between intrinsic and extrinsic evaluation, as the effect of our transformations in downstream tasks is higher for unsupervised systems than for supervised ones.
SemEval-2017 Task 1: Semantic Textual Similarity - Multilingual and Cross-lingual Focused Evaluation
Jul 31, 2017
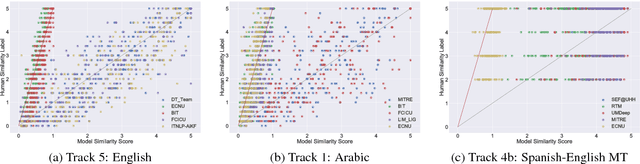
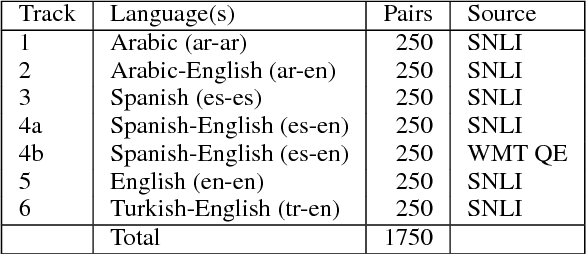

Semantic Textual Similarity (STS) measures the meaning similarity of sentences. Applications include machine translation (MT), summarization, generation, question answering (QA), short answer grading, semantic search, dialog and conversational systems. The STS shared task is a venue for assessing the current state-of-the-art. The 2017 task focuses on multilingual and cross-lingual pairs with one sub-track exploring MT quality estimation (MTQE) data. The task obtained strong participation from 31 teams, with 17 participating in all language tracks. We summarize performance and review a selection of well performing methods. Analysis highlights common errors, providing insight into the limitations of existing models. To support ongoing work on semantic representations, the STS Benchmark is introduced as a new shared training and evaluation set carefully selected from the corpus of English STS shared task data (2012-2017).
Supervised Hierarchical Classification for Student Answer Scoring
Jul 13, 2015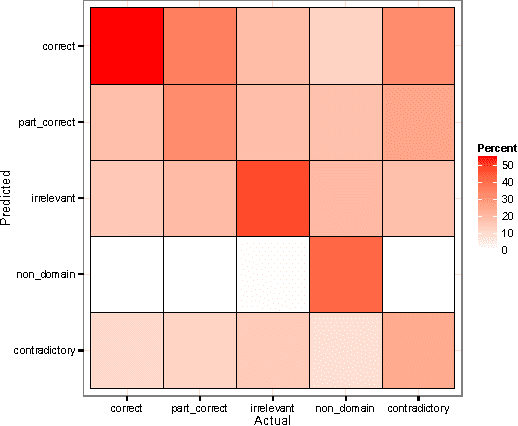
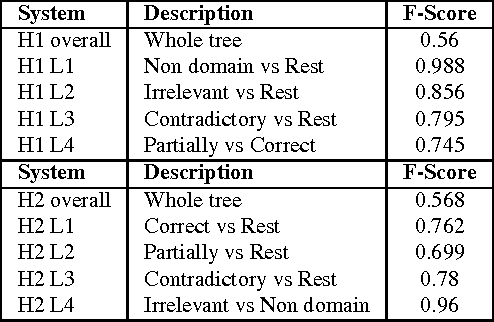
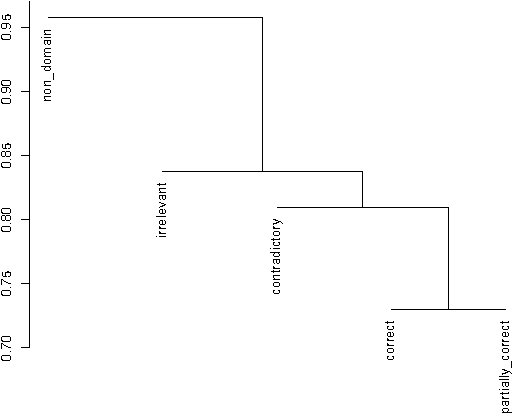
This paper describes a hierarchical system that predicts one label at a time for automated student response analysis. For the task, we build a classification binary tree that delays more easily confused labels to later stages using hierarchical processes. In particular, the paper describes how the hierarchical classifier has been built and how the classification task has been broken down into binary subtasks. It finally discusses the motivations and fundamentals of such an approach.