 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourierSpecNet: Neural Collision Operator Approximation Inspired by the Fourier Spectral Method for Solving the Boltzmann Equation
Apr 29, 2025The Boltzmann equation, a fundamental model in kinetic theory, describes the evolution of particle distribution functions through a nonlinear, high-dimensional collision operator. However, its numerical solution remains computationally demanding, particularly for inelastic collisions and high-dimensional velocity domains. In this work, we propose the Fourier Neural Spectral Network (FourierSpecNet), a hybrid framework that integrates the Fourier spectral method with deep learning to approximate the collision operator in Fourier space efficiently. FourierSpecNet achieves resolution-invariant learning and supports zero-shot super-resolution, enabling accurate predictions at unseen resolutions without retraining. Beyond empirical validation, we establish a consistency result showing that the trained operator converges to the spectral solution as the discretization is refined. We evaluate our method on several benchmark cases, including Maxwellian and hard-sphere molecular models, as well as inelastic collision scenarios. The results demonstrate that FourierSpecNet offers competitive accuracy while significantly reducing computational cost compared to traditional spectral solvers. Our approach provides a robust and scalable alternative for solving the Boltzmann equation across both elastic and inelastic regimes.
Estimation of System Parameters Including Repeated Cross-Sectional Data through Emulator-Informed Deep Generative Model
Dec 27, 2024Differential equations (DEs) are crucial for modeling the evolution of natural or engineered systems. Traditionally, the parameters in DEs are adjusted to fit data from system observations. However, in fields such as politics, economics, and biology, available data are often independently collected at distinct time points from different subjects (i.e., repeated cross-sectional (RCS) data). Conventional optimization techniques struggle to accurately estimate DE parameters when RCS data exhibit various heterogeneities, leading to a significant loss of information. To address this issue, we propose a new estimation method called the emulator-informed deep-generative model (EIDGM), designed to handle RCS data. Specifically, EIDGM integrates a physics-informed neural network-based emulator that immediately generates DE solutions and a Wasserstein generative adversarial network-based parameter generator that can effectively mimic the RCS data. We evaluated EIDGM on exponential growth, logistic population models, and the Lorenz system, demonstrating its superior ability to accurately capture parameter distributions. Additionally, we applied EIDGM to an experimental dataset of Amyloid beta 40 and beta 42, successfully capturing diverse parameter distribution shapes. This shows that EIDGM can be applied to model a wide range of systems and extended to uncover the operating principles of systems based on limited data.
Estimating the Distribution of Parameters in Differential Equations with Repeated Cross-Sectional Data
Apr 23, 2024Differential equations are pivotal in modeling and understanding the dynamics of various systems, offering insights into their future states through parameter estimation fitted to time series data. In fields such as economy, politics, and biology, the observation data points in the time series are often independently obtained (i.e., Repeated Cross-Sectional (RCS) data). With RCS data, we found that traditional methods for parameter estimation in differential equations, such as using mean values of time trajectories or Gaussian Process-based trajectory generation, have limitations in estimating the shape of parameter distributions, often leading to a significant loss of data information. To address this issue, we introduce a novel method, Estimation of Parameter Distribution (EPD), providing accurate distribution of parameters without loss of data information. EPD operates in three main steps: generating synthetic time trajectories by randomly selecting observed values at each time point, estimating parameters of a differential equation that minimize the discrepancy between these trajectories and the true solution of the equation, and selecting the parameters depending on the scale of discrepancy. We then evaluated the performance of EPD across several models, including exponential growth, logistic population models, and target cell-limited models with delayed virus production, demonstrating its superiority in capturing the shape of parameter distributions. Furthermore, we applied EPD to real-world datasets, capturing various shapes of parameter distributions rather than a normal distribution. These results effectively address the heterogeneity within systems, marking a substantial progression in accurately modeling systems using RCS data.
Sobolev Training for Operator Learning
Feb 14, 2024This study investigates the impact of Sobolev Training on operator learning frameworks for improving model performance. Our research reveals that integrating derivative information into the loss function enhances the training process, and we propose a novel framework to approximate derivatives on irregular meshes in operator learning. Our findings are supported by both experimental evidence and theoretical analysis. This demonstrates the effectiveness of Sobolev Training in approximating the solution operators between infinite-dimensional spaces.
Learning time-dependent PDE via graph neural networks and deep operator network for robust accuracy on irregular grids
Feb 13, 2024Scientific computing using deep learning has seen significant advancements in recent years. There has been growing interest in models that learn the operator from the parameters of a partial differential equation (PDE) to the corresponding solutions. Deep Operator Network (DeepONet) and Fourier Neural operator, among other models, have been designed with structures suitable for handling functions as inputs and outputs, enabling real-time predictions as surrogate models for solution operators. There has also been significant progress in the research on surrogate models based on graph neural networks (GNNs), specifically targeting the dynamics in time-dependent PDEs. In this paper, we propose GraphDeepONet, an autoregressive model based on GNNs, to effectively adapt DeepONet, which is well-known for successful operator learning. GraphDeepONet exhibits robust accuracy in predicting solutions compared to existing GNN-based PDE solver models. It maintains consistent performance even on irregular grids, leveraging the advantages inherited from DeepONet and enabling predictions on arbitrary grids. Additionally, unlike traditional DeepONet and its variants, GraphDeepONet enables time extrapolation for time-dependent PDE solutions. We also provide theoretical analysis of the universal approximation capability of GraphDeepONet in approximating continuous operators across arbitrary time intervals.
HyperDeepONet: learning operator with complex target function space using the limited resources via hypernetwork
Dec 26, 2023Fast and accurate predictions for complex physical dynamics are a significant challenge across various applications. Real-time prediction on resource-constrained hardware is even more crucial in real-world problems. The deep operator network (DeepONet) has recently been proposed as a framework for learning nonlinear mappings between function spaces. However, the DeepONet requires many parameters and has a high computational cost when learning operators, particularly those with complex (discontinuous or non-smooth) target functions. This study proposes HyperDeepONet, which uses the expressive power of the hypernetwork to enable the learning of a complex operator with a smaller set of parameters. The DeepONet and its variant models can be thought of as a method of injecting the input function information into the target function. From this perspective, these models can be viewed as a particular case of HyperDeepONet. We analyze the complexity of DeepONet and conclude that HyperDeepONet needs relatively lower complexity to obtain the desired accuracy for operator learning. HyperDeepONet successfully learned various operators with fewer computational resources compared to other benchmarks.
opPINN: Physics-Informed Neural Network with operator learning to approximate solutions to the Fokker-Planck-Landau equation
Jul 05, 2022

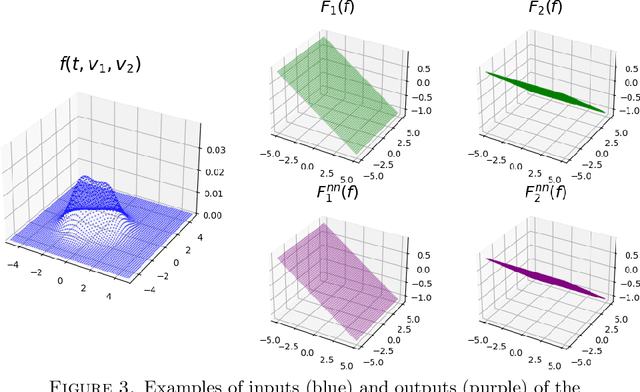
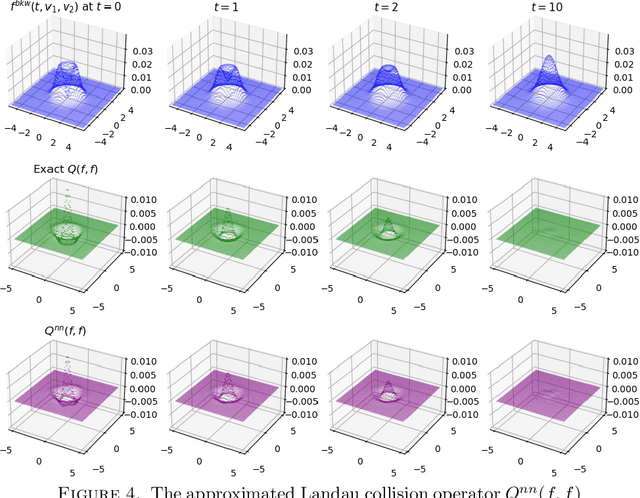
We propose a hybrid framework opPINN: physics-informed neural network (PINN) with operator learning for approximating the solution to the Fokker-Planck-Landau (FPL) equation. The opPINN framework is divided into two steps: Step 1 and Step 2. After the operator surrogate models are trained during Step 1, PINN can effectively approximate the solution to the FPL equation during Step 2 by using the pre-trained surrogate models. The operator surrogate models greatly reduce the computational cost and boost PINN by approximating the complex Landau collision integral in the FPL equation. The operator surrogate models can also be combined with the traditional numerical schemes. It provides a high efficiency in computational time when the number of velocity modes becomes larger. Using the opPINN framework, we provide the neural network solutions for the FPL equation under the various types of initial conditions, and interaction models in two and three dimensions. Furthermore, based on the theoretical properties of the FPL equation, we show that the approximated neural network solution converges to the a priori classical solution of the FPL equation as the pre-defined loss function is reduced.
AL-PINNs: Augmented Lagrangian relaxation method for Physics-Informed Neural Networks
Apr 29, 2022

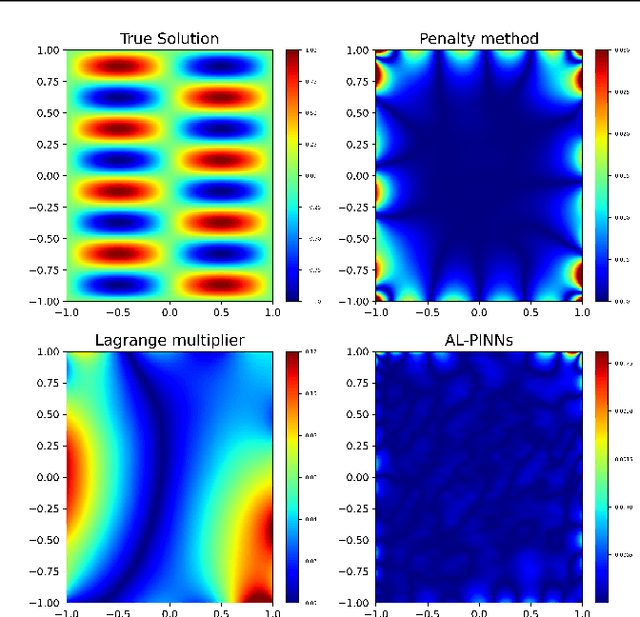

Physics-Informed Neural Networks (PINNs) has become a prominent application of deep learning in scientific computation, as it is a powerful approximator of solutions to nonlinear partial differential equations (PDEs). There have been numerous attempts to facilitate the training process of PINNs by adjusting the weight of each component of the loss function, called adaptive loss balancing algorithms. In this paper, we propose an Augmented Lagrangian relaxation method for PINNs (AL-PINNs). We treat the initial and boundary conditions as constraints for the optimization problem of the PDE residual. By employing Augmented Lagrangian relaxation, the constrained optimization problem becomes a sequential max-min problem so that the learnable parameters $\lambda$'s adaptively balance each loss component. Our theoretical analysis reveals that the sequence of minimizers of the proposed loss functions converges to an actual solution for the Helmholtz, viscous Burgers, and Klein--Gordon equations. We demonstrate through various numerical experiments that AL-PINNs yields a much smaller relative error compared with that of state-of-the-art adaptive loss balancing algorithms.
Pseudo-Differential Integral Operator for Learning Solution Operators of Partial Differential Equations
Feb 16, 2022

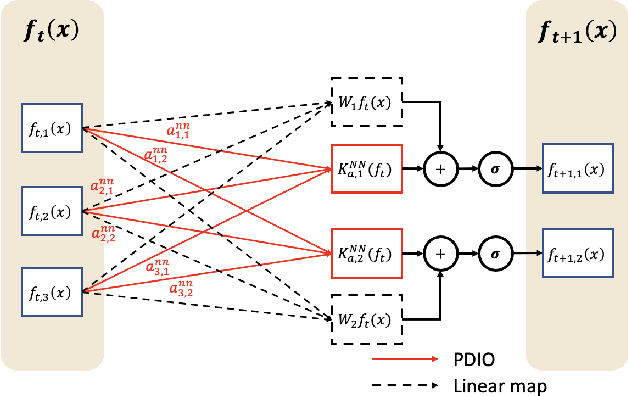

Learning mapping between two function spaces has attracted considerable research attention. However, learning the solution operator of partial differential equations (PDEs) remains a challenge in scientific computing. Therefore, in this study, we propose a novel pseudo-differential integral operator (PDIO) inspired by a pseudo-differential operator, which is a generalization of a differential operator and characterized by a certain symbol. We parameterize the symbol by using a neural network and show that the neural-network-based symbol is contained in a smooth symbol class. Subsequently, we prove that the PDIO is a bounded linear operator, and thus is continuous in the Sobolev space. We combine the PDIO with the neural operator to develop a pseudo-differential neural operator (PDNO) to learn the nonlinear solution operator of PDEs. We experimentally validate the effectiveness of the proposed model by using Burgers' equation, Darcy flow, and the Navier-Stokes equation. The results reveal that the proposed PDNO outperforms the existing neural operator approaches in most experiments.
Solving PDE-constrained Control Problems using Operator Learning
Nov 09, 2021



The modeling and control of complex physical dynamics are essential in real-world problems. We propose a novel framework that is generally applicable to solving PDE-constrained optimal control problems by introducing surrogate models for PDE solution operators with special regularizers. The procedure of the proposed framework is divided into two phases: solution operator learning for PDE constraints (Phase 1) and searching for optimal control (Phase 2). Once the surrogate model is trained in Phase 1, the optimal control can be inferred in Phase 2 without intensive computations. Our framework can be applied to both data-driven and data-free cases. We demonstrate the successful application of our method to various optimal control problems for different control variables with diverse PDE constraints from the Poisson equation to Burgers' equation.