 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplenomegaly Segmentation on Multi-modal MRI using Deep Convolutional Networks
Nov 09, 2018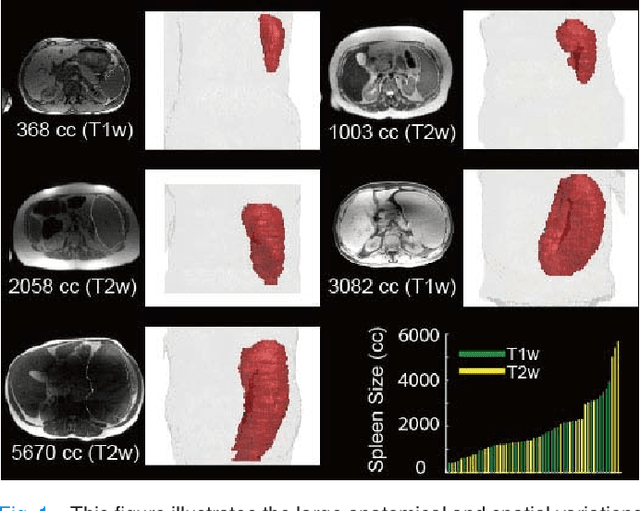
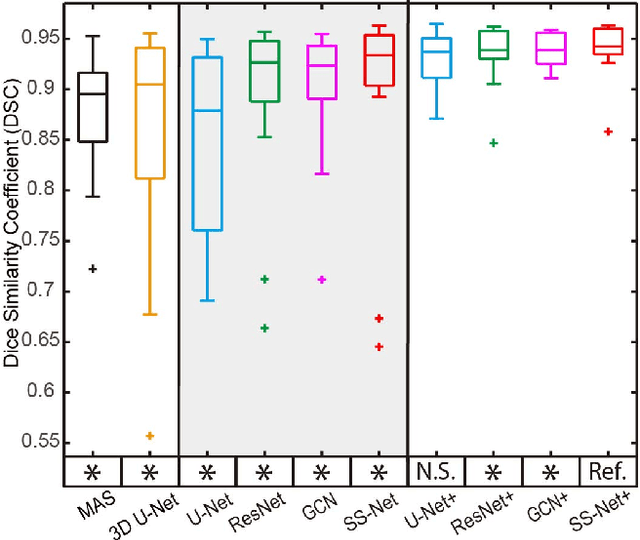
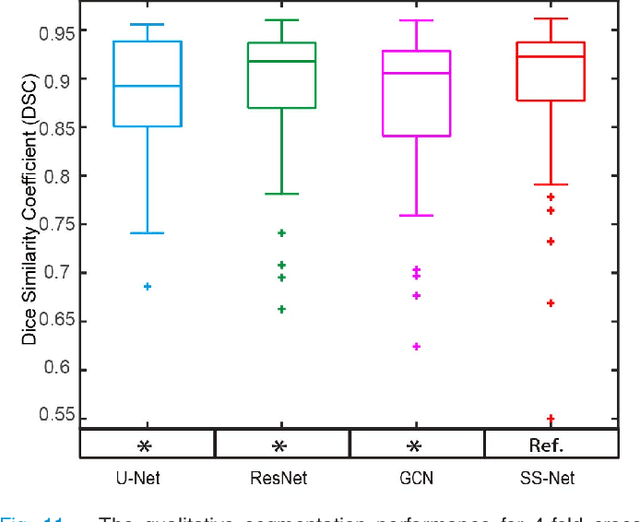
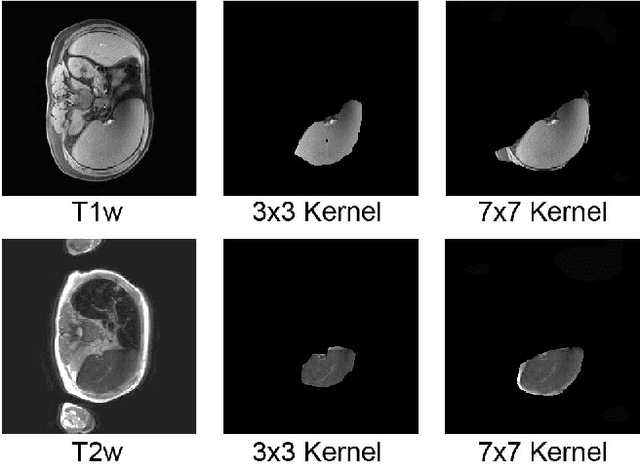
The findings of splenomegaly, abnormal enlargement of the spleen, is a non-invasive clinical biomarker for liver and spleen disease. Automated segmentation methods are essential to efficiently quantify splenomegaly from clinically acquired abdominal magnetic resonance imaging (MRI) scans. However, the task is challenging due to (1) large anatomical and spatial variations of splenomegaly, (2) large inter- and intra-scan intensity variations on multi-modal MRI, and (3) limited numbers of labeled splenomegaly scans. In this paper, we propose the Splenomegaly Segmentation Network (SS-Net) to introduce the deep convolutional neural network (DCNN) approaches in multi-modal MRI splenomegaly segmentation. Large convolutional kernel layers were used to address the spatial and anatomical variations, while the conditional generative adversarial networks (GAN) were employed to leverage the segmentation performance of SS-Net in an end-to-end manner. A clinically acquired cohort containing both T1-weighted (T1w) and T2-weighted (T2w) MRI splenomegaly scans was used to train and evaluate the performance of multi-atlas segmentation (MAS), 2D DCNN networks, and a 3D DCNN network. From the experimental results, the DCNN methods achieved superior performance to the state-of-the-art MAS method. The proposed SS-Net method achieved the highest median and mean Dice scores among investigated baseline DCNN methods.
SynSeg-Net: Synthetic Segmentation Without Target Modality Ground Truth
Oct 15, 2018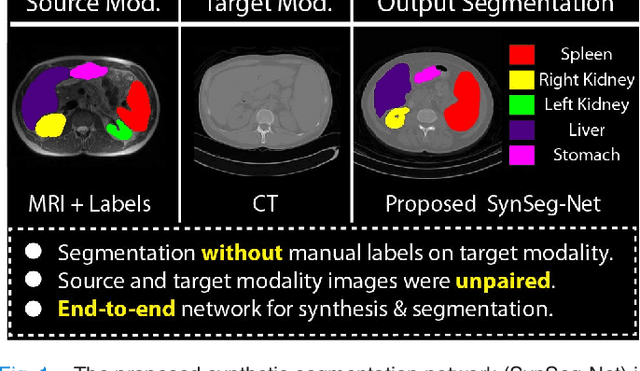
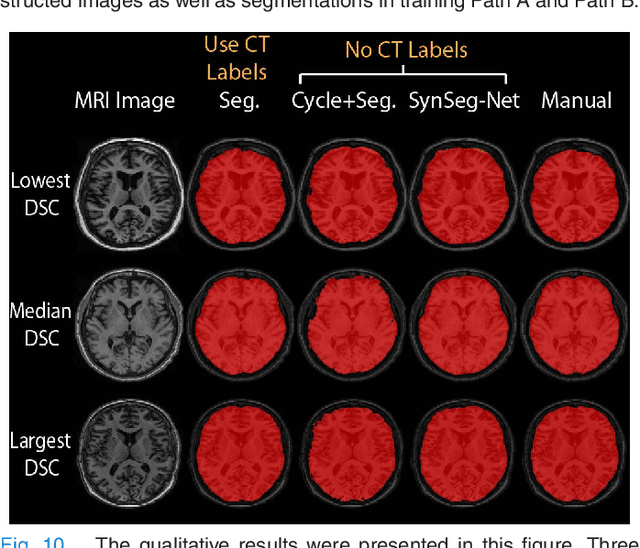
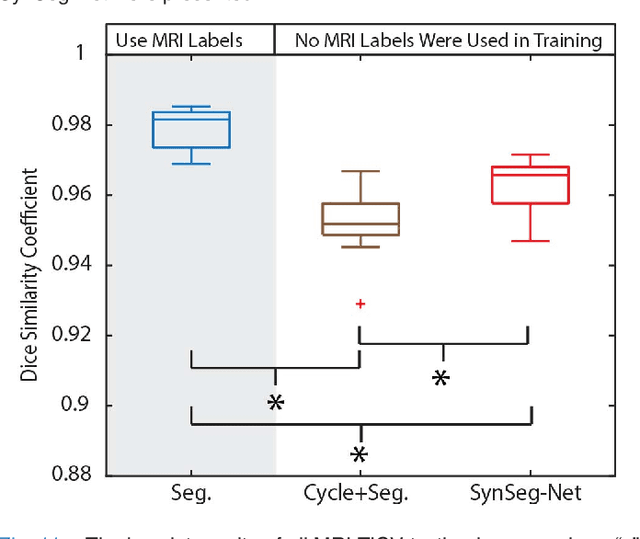
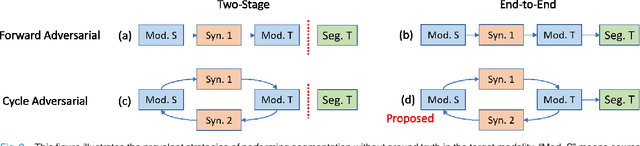
A key limitation of deep convolutional neural networks (DCNN) based image segmentation methods is the lack of generalizability. Manually traced training images are typically required when segmenting organs in a new imaging modality or from distinct disease cohort. The manual efforts can be alleviated if the manually traced images in one imaging modality (e.g., MRI) are able to train a segmentation network for another imaging modality (e.g., CT). In this paper, we propose an end-to-end synthetic segmentation network (SynSeg-Net) to train a segmentation network for a target imaging modality without having manual labels. SynSeg-Net is trained by using (1) unpaired intensity images from source and target modalities, and (2) manual labels only from source modality. SynSeg-Net is enabled by the recent advances of cycle generative adversarial networks (CycleGAN) and DCNN. We evaluate the performance of the SynSeg-Net on two experiments: (1) MRI to CT splenomegaly synthetic segmentation for abdominal images, and (2) CT to MRI total intracranial volume synthetic segmentation (TICV) for brain images. The proposed end-to-end approach achieved superior performance to two stage methods. Moreover, the SynSeg-Net achieved comparable performance to the traditional segmentation network using target modality labels in certain scenarios. The source code of SynSeg-Net is publicly available (https://github.com/MASILab/SynSeg-Net).