 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Socratic Inquiry: A Framework for Proactive Template-Guided Therapeutic Conversation Generation
Feb 02, 2026Proactive questioning, where therapists deliberately initiate structured, cognition-guiding inquiries, is a cornerstone of cognitive behavioral therapy (CBT). Yet, current psychological large language models (LLMs) remain overwhelmingly reactive, defaulting to empathetic but superficial responses that fail to surface latent beliefs or guide behavioral change. To bridge this gap, we propose the \textbf{Socratic Inquiry Framework (SIF)}, a lightweight, plug-and-play therapeutic intent planner that transforms LLMs from passive listeners into active cognitive guides. SIF decouples \textbf{when to ask} (via Strategy Anchoring) from \textbf{what to ask} (via Template Retrieval), enabling context-aware, theory-grounded questioning without end-to-end retraining. Complementing SIF, we introduce \textbf{Socratic-QA}, a high-quality dataset of strategy-aligned Socratic sequences that provides explicit supervision for proactive reasoning. Experiments show that SIF significantly enhances proactive questioning frequency, conversational depth, and therapeutic alignment, marking a clear shift from reactive comfort to proactive exploration. Our work establishes a new paradigm for psychologically informed LLMs: not just to respond, but to guide.
Generalized Population-Based Training for Hyperparameter Optimization in Reinforcement Learning
Apr 12, 2024Hyperparameter optimization plays a key role in the machine learning domain. Its significance is especially pronounced in reinforcement learning (RL), where agents continuously interact with and adapt to their environments, requiring dynamic adjustments in their learning trajectories. To cater to this dynamicity, the Population-Based Training (PBT) was introduced, leveraging the collective intelligence of a population of agents learning simultaneously. However, PBT tends to favor high-performing agents, potentially neglecting the explorative potential of agents on the brink of significant advancements. To mitigate the limitations of PBT, we present the Generalized Population-Based Training (GPBT), a refined framework designed for enhanced granularity and flexibility in hyperparameter adaptation. Complementing GPBT, we further introduce Pairwise Learning (PL). Instead of merely focusing on elite agents, PL employs a comprehensive pairwise strategy to identify performance differentials and provide holistic guidance to underperforming agents. By integrating the capabilities of GPBT and PL, our approach significantly improves upon traditional PBT in terms of adaptability and computational efficiency. Rigorous empirical evaluations across a range of RL benchmarks confirm that our approach consistently outperforms not only the conventional PBT but also its Bayesian-optimized variant.
Evolutionary Reinforcement Learning: A Survey
Mar 10, 2023Reinforcement learning (RL) is a machine learning approach that trains agents to maximize cumulative rewards through interactions with environments. The integration of RL with deep learning has recently resulted in impressive achievements in a wide range of challenging tasks, including board games, arcade games, and robot control. Despite these successes, there remain several crucial challenges, including brittle convergence properties caused by sensitive hyperparameters, difficulties in temporal credit assignment with long time horizons and sparse rewards, a lack of diverse exploration, especially in continuous search space scenarios, difficulties in credit assignment in multi-agent reinforcement learning, and conflicting objectives for rewards. Evolutionary computation (EC), which maintains a population of learning agents, has demonstrated promising performance in addressing these limitations. This article presents a comprehensive survey of state-of-the-art methods for integrating EC into RL, referred to as evolutionary reinforcement learning (EvoRL). We categorize EvoRL methods according to key research fields in RL, including hyperparameter optimization, policy search, exploration, reward shaping, meta-RL, and multi-objective RL. We then discuss future research directions in terms of efficient methods, benchmarks, and scalable platforms. This survey serves as a resource for researchers and practitioners interested in the field of EvoRL, highlighting the important challenges and opportunities for future research. With the help of this survey, researchers and practitioners can develop more efficient methods and tailored benchmarks for EvoRL, further advancing this promising cross-disciplinary research field.
Lamarckian Platform: Pushing the Boundaries of Evolutionary Reinforcement Learning towards Asynchronous Commercial Games
Sep 21, 2022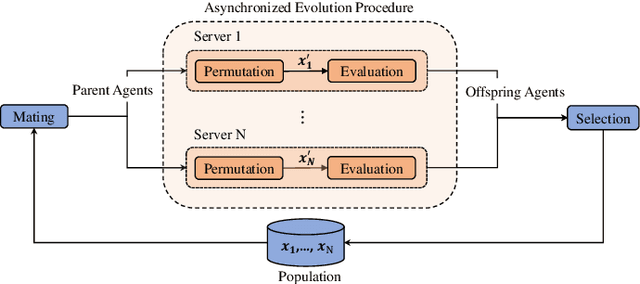


Despite the emerging progress of integrating evolutionary computation into reinforcement learning, the absence of a high-performance platform endowing composability and massive parallelism causes non-trivial difficulties for research and applications related to asynchronous commercial games. Here we introduce Lamarckian - an open-source platform featuring support for evolutionary reinforcement learning scalable to distributed computing resources. To improve the training speed and data efficiency, Lamarckian adopts optimized communication methods and an asynchronous evolutionary reinforcement learning workflow. To meet the demand for an asynchronous interface by commercial games and various methods, Lamarckian tailors an asynchronous Markov Decision Process interface and designs an object-oriented software architecture with decoupled modules. In comparison with the state-of-the-art RLlib, we empirically demonstrate the unique advantages of Lamarckian on benchmark tests with up to 6000 CPU cores: i) both the sampling efficiency and training speed are doubled when running PPO on Google football game; ii) the training speed is 13 times faster when running PBT+PPO on Pong game. Moreover, we also present two use cases: i) how Lamarckian is applied to generating behavior-diverse game AI; ii) how Lamarckian is applied to game balancing tests for an asynchronous commercial game.