 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLamarckian Platform: Pushing the Boundaries of Evolutionary Reinforcement Learning towards Asynchronous Commercial Games
Paper and Code
Sep 21, 2022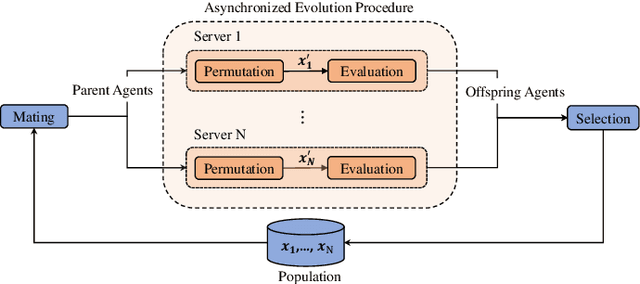
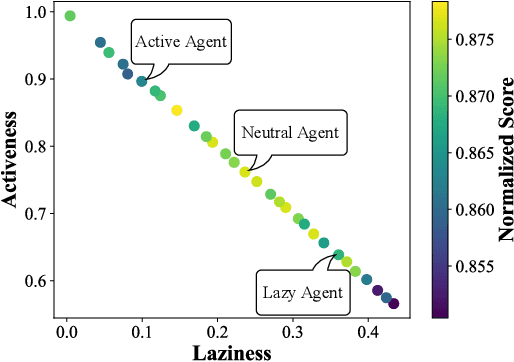


Despite the emerging progress of integrating evolutionary computation into reinforcement learning, the absence of a high-performance platform endowing composability and massive parallelism causes non-trivial difficulties for research and applications related to asynchronous commercial games. Here we introduce Lamarckian - an open-source platform featuring support for evolutionary reinforcement learning scalable to distributed computing resources. To improve the training speed and data efficiency, Lamarckian adopts optimized communication methods and an asynchronous evolutionary reinforcement learning workflow. To meet the demand for an asynchronous interface by commercial games and various methods, Lamarckian tailors an asynchronous Markov Decision Process interface and designs an object-oriented software architecture with decoupled modules. In comparison with the state-of-the-art RLlib, we empirically demonstrate the unique advantages of Lamarckian on benchmark tests with up to 6000 CPU cores: i) both the sampling efficiency and training speed are doubled when running PPO on Google football game; ii) the training speed is 13 times faster when running PBT+PPO on Pong game. Moreover, we also present two use cases: i) how Lamarckian is applied to generating behavior-diverse game AI; ii) how Lamarckian is applied to game balancing tests for an asynchronous commercial game.