 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Blockchain-based Decentralized Federated Learning Framework with Committee Consensus
Apr 02, 2020



Federated learning has been widely studied and applied to various scenarios. In mobile computing scenarios, federated learning protects users from exposing their private data, while cooperatively training the global model for a variety of real-world applications. However, the security of federated learning is increasingly being questioned, due to the malicious clients or central servers' constant attack to the global model or user privacy data. To address these security issues, we proposed a decentralized federated learning framework based on blockchain, i.e., a Blockchain-based Federated Learning framework with Committee consensus (BFLC). The framework uses blockchain for the global model storage and the local model update exchange. To enable the proposed BFLC, we also devised an innovative committee consensus mechanism, which can effectively reduce the amount of consensus computing and reduce malicious attacks. We then discussed the scalability of BFLC, including theoretical security, storage optimization, and incentives. Finally, we performed experiments using real-world datasets to verify the effectiveness of the BFLC framework.
Prophet: Proactive Candidate-Selection for Federated Learning by Predicting the Qualities of Training and Reporting Phases
Feb 03, 2020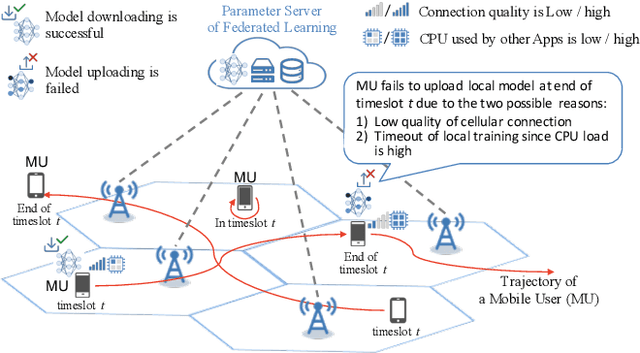

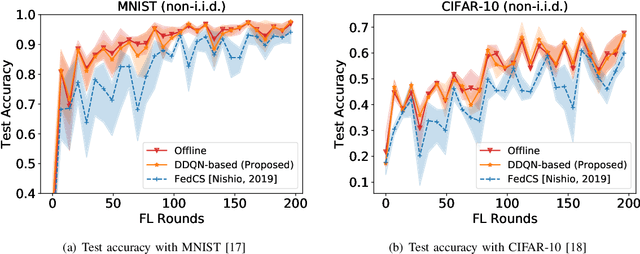
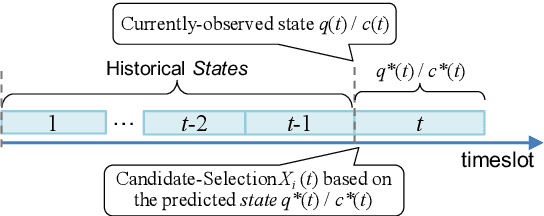
Federated Learning (FL) is viewed as a promising technique for future distributed machine learning. It permits a large number of mobile devices participating in the training of a global model collaboratively without having to expose their local private data. Although the challenge of the network connection will be much relieved in 5G/B5G era, the training latency is still an obstacle preventing FL from being largely adopted. One of the most fundamental problems that leads to large training latency is the bad candidate-selection of FL participants. To the best of our knowledge, the existing candidate-selection algorithms belong to the reactive manner. Under such reactive selection, the FL parameter server only knows the currently-observed resources of all candidates. In the dynamic FL environment, the mobile devices selected by the reactive candidate-selection algorithms very possibly fail to complete the training and reporting phases of FL. To this end, we study the proactive candidate-selection for FL in this paper. We first let each candidate device locally predict the qualities of both its training and reporting phases using the LSTM network. Then, the proposed candidate-selection algorithm is implemented by the Deep Reinforcement Learning (DRL) framework, which can adapt to the dynamically varying factors in the metropolitan edge computing environment. Finally, the real-world trace-driven experiments prove that the proposed proactive approach outperforms the existing reactive algorithms with respect to the ratio of valid participants and the test accuracy of the aggregated global FL model.