 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuick Adaptive Ternary Segmentation: An Efficient Decoding Procedure For Hidden Markov Models
May 29, 2023Hidden Markov models (HMMs) are characterized by an unobservable (hidden) Markov chain and an observable process, which is a noisy version of the hidden chain. Decoding the original signal (i.e., hidden chain) from the noisy observations is one of the main goals in nearly all HMM based data analyses. Existing decoding algorithms such as the Viterbi algorithm have computational complexity at best linear in the length of the observed sequence, and sub-quadratic in the size of the state space of the Markov chain. We present Quick Adaptive Ternary Segmentation (QATS), a divide-and-conquer procedure which decodes the hidden sequence in polylogarithmic computational complexity in the length of the sequence, and cubic in the size of the state space, hence particularly suited for large scale HMMs with relatively few states. The procedure also suggests an effective way of data storage as specific cumulative sums. In essence, the estimated sequence of states sequentially maximizes local likelihood scores among all local paths with at most three segments. The maximization is performed only approximately using an adaptive search procedure. The resulting sequence is admissible in the sense that all transitions occur with positive probability. To complement formal results justifying our approach, we present Monte-Carlo simulations which demonstrate the speedups provided by QATS in comparison to Viterbi, along with a precision analysis of the returned sequences. An implementation of QATS in C++ is provided in the R-package QATS and is available from GitHub.
Optimistic search strategy: Change point detection for large-scale data via adaptive logarithmic queries
Oct 20, 2020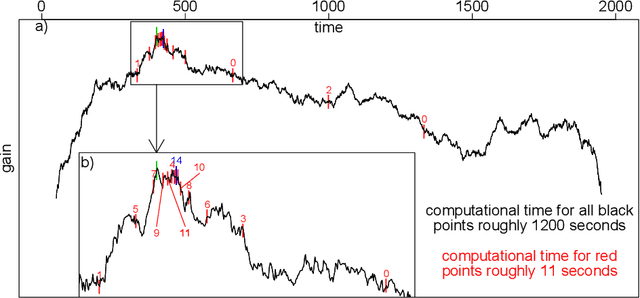
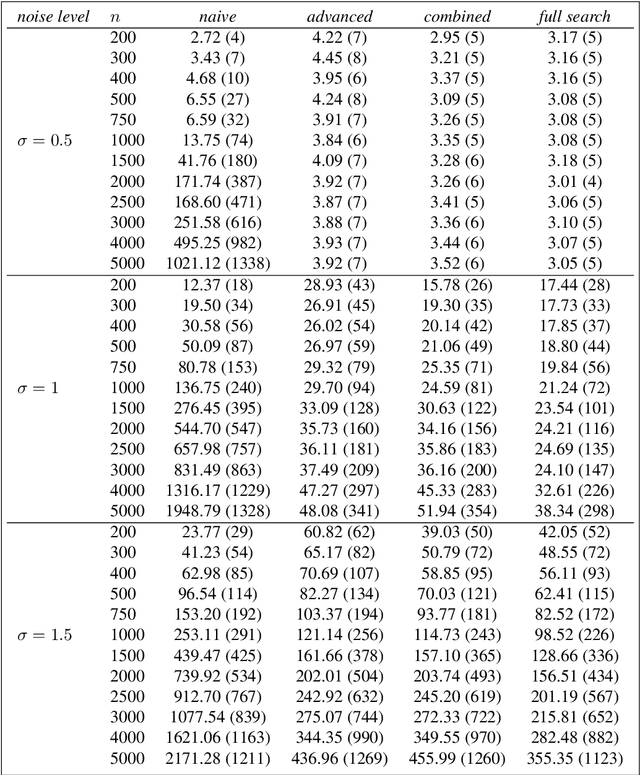
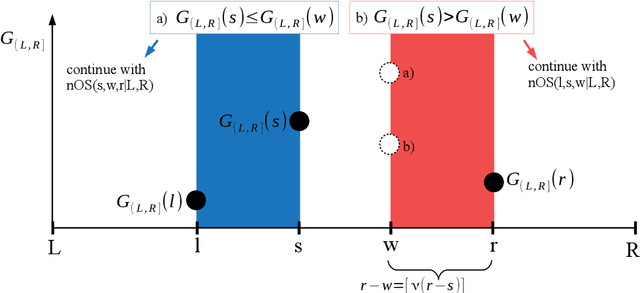
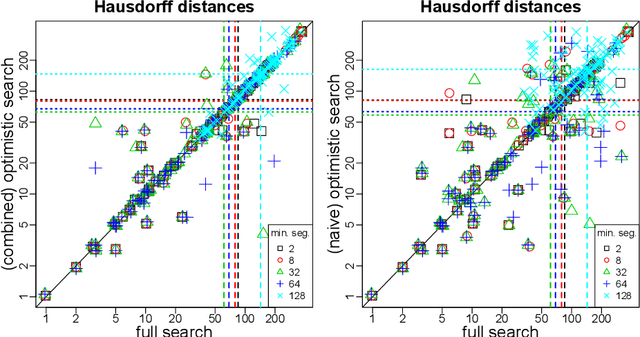
As a classical and ever reviving topic, change point detection is often formulated as a search for the maximum of a gain function describing improved fits when segmenting the data. Searching through all candidate split points on the grid for finding the best one requires $O(T)$ evaluations of the gain function for an interval with $T$ observations. If each evaluation is computationally demanding (e.g. in high-dimensional models), this can become infeasible. Instead, we propose optimistic search strategies with $O(\log T)$ evaluations exploiting specific structure of the gain function. Towards solid understanding of our strategies, we investigate in detail the classical univariate Gaussian change in mean setup. For some of our proposals we prove asymptotic minimax optimality for single and multiple change point scenarios. Our search strategies generalize far beyond the theoretically analyzed univariate setup. We illustrate, as an example, massive computational speedup in change point detection for high-dimensional Gaussian graphical models. More generally, we demonstrate empirically that our optimistic search methods lead to competitive estimation performance while heavily reducing run-time.
NETT: Solving Inverse Problems with Deep Neural Networks
Feb 28, 2018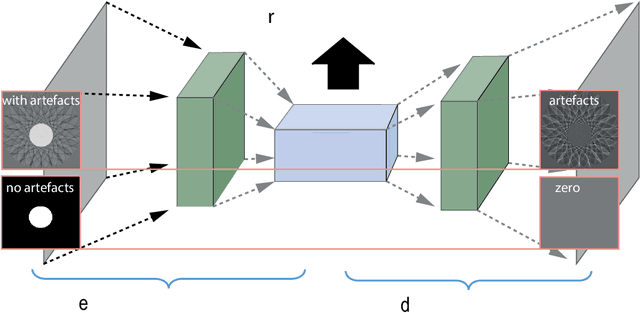
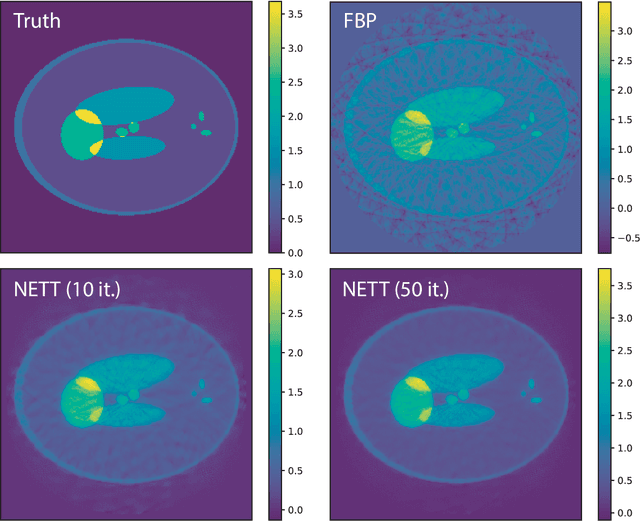
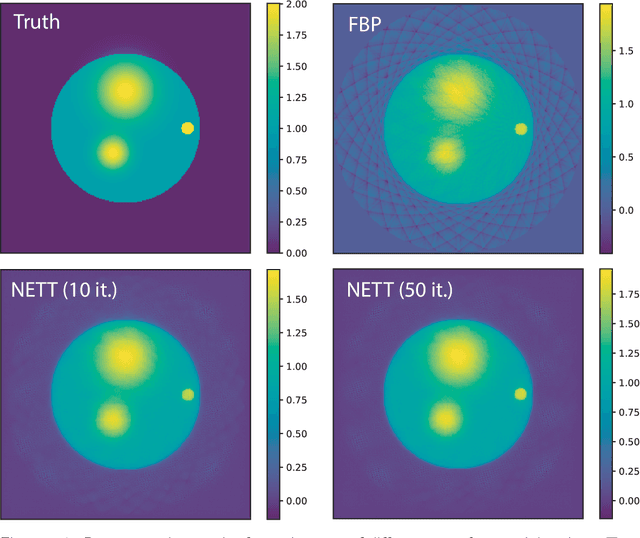
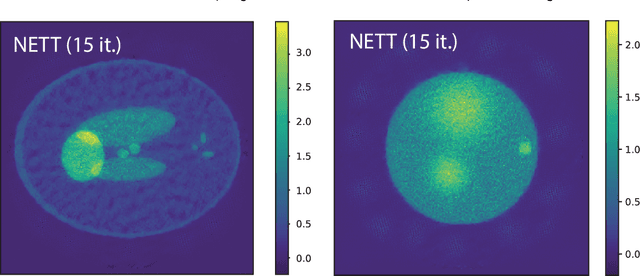
Recovering a function or high-dimensional parameter vector from indirect measurements is a central task in various scientific areas. Several methods for solving such inverse problems are well developed and well understood. Recently, novel algorithms using deep learning and neural networks for inverse problems appeared. While still in their infancy, these techniques show astonishing performance for applications like low-dose CT or various sparse data problems. However, theoretical results for deep learning in inverse problems are missing so far. In this paper, we establish such a convergence analysis for the proposed NETT (Network Tikhonov) approach to inverse problems. NETT considers regularized solutions having small value of a regularizer defined by a trained neural network. Opposed to existing deep learning approaches, our regularization scheme enforces data consistency also for the actual unknown to be recovered. This is beneficial in case the unknown to be recovered is not sufficiently similar to available training data. We present a complete convergence analysis for NETT, where we derive well-posedness results and quantitative error estimates, and propose a possible strategy for training the regularizer. Numerical results are presented for a tomographic sparse data problem using the $\ell^q$-norm of auto-encoder as trained regularizer, which demonstrate good performance of NETT even for unknowns of different type from the training data.