 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Joint Mining of Deep Features and Image Labels for Large-scale Radiology Image Categorization and Scene Recognition
Dec 27, 2017
The recent rapid and tremendous success of deep convolutional neural networks (CNN) on many challenging computer vision tasks largely derives from the accessibility of the well-annotated ImageNet and PASCAL VOC datasets. Nevertheless, unsupervised image categorization (i.e., without the ground-truth labeling) is much less investigated, yet critically important and difficult when annotations are extremely hard to obtain in the conventional way of "Google Search" and crowd sourcing. We address this problem by presenting a looped deep pseudo-task optimization (LDPO) framework for joint mining of deep CNN features and image labels. Our method is conceptually simple and rests upon the hypothesized "convergence" of better labels leading to better trained CNN models which in turn feed more discriminative image representations to facilitate more meaningful clusters/labels. Our proposed method is validated in tackling two important applications: 1) Large-scale medical image annotation has always been a prohibitively expensive and easily-biased task even for well-trained radiologists. Significantly better image categorization results are achieved via our proposed approach compared to the previous state-of-the-art method. 2) Unsupervised scene recognition on representative and publicly available datasets with our proposed technique is examined. The LDPO achieves excellent quantitative scene classification results. On the MIT indoor scene dataset, it attains a clustering accuracy of 75.3%, compared to the state-of-the-art supervised classification accuracy of 81.0% (when both are based on the VGG-VD model).
Unsupervised Category Discovery via Looped Deep Pseudo-Task Optimization Using a Large Scale Radiology Image Database
Mar 25, 2016
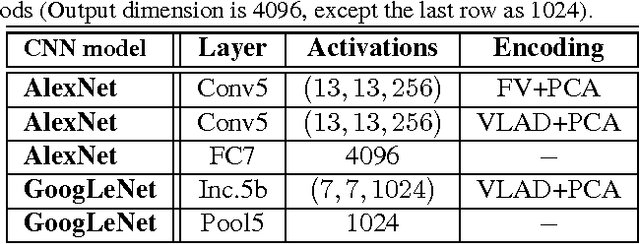
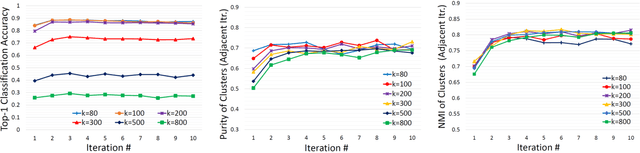
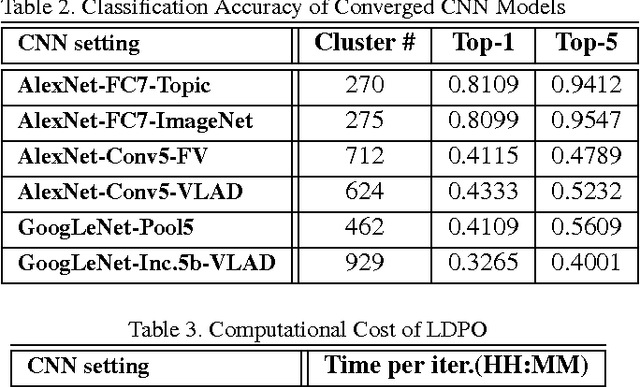
Obtaining semantic labels on a large scale radiology image database (215,786 key images from 61,845 unique patients) is a prerequisite yet bottleneck to train highly effective deep convolutional neural network (CNN) models for image recognition. Nevertheless, conventional methods for collecting image labels (e.g., Google search followed by crowd-sourcing) are not applicable due to the formidable difficulties of medical annotation tasks for those who are not clinically trained. This type of image labeling task remains non-trivial even for radiologists due to uncertainty and possible drastic inter-observer variation or inconsistency. In this paper, we present a looped deep pseudo-task optimization procedure for automatic category discovery of visually coherent and clinically semantic (concept) clusters. Our system can be initialized by domain-specific (CNN trained on radiology images and text report derived labels) or generic (ImageNet based) CNN models. Afterwards, a sequence of pseudo-tasks are exploited by the looped deep image feature clustering (to refine image labels) and deep CNN training/classification using new labels (to obtain more task representative deep features). Our method is conceptually simple and based on the hypothesized "convergence" of better labels leading to better trained CNN models which in turn feed more effective deep image features to facilitate more meaningful clustering/labels. We have empirically validated the convergence and demonstrated promising quantitative and qualitative results. Category labels of significantly higher quality than those in previous work are discovered. This allows for further investigation of the hierarchical semantic nature of the given large-scale radiology image database.