 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Federated Medical Image Segmentation via Client Contribution Estimation
Mar 29, 2023How to ensure fairness is an important topic in federated learning (FL). Recent studies have investigated how to reward clients based on their contribution (collaboration fairness), and how to achieve uniformity of performance across clients (performance fairness). Despite achieving progress on either one, we argue that it is critical to consider them together, in order to engage and motivate more diverse clients joining FL to derive a high-quality global model. In this work, we propose a novel method to optimize both types of fairness simultaneously. Specifically, we propose to estimate client contribution in gradient and data space. In gradient space, we monitor the gradient direction differences of each client with respect to others. And in data space, we measure the prediction error on client data using an auxiliary model. Based on this contribution estimation, we propose a FL method, federated training via contribution estimation (FedCE), i.e., using estimation as global model aggregation weights. We have theoretically analyzed our method and empirically evaluated it on two real-world medical datasets. The effectiveness of our approach has been validated with significant performance improvements, better collaboration fairness, better performance fairness, and comprehensive analytical studies.
Going to Extremes: Weakly Supervised Medical Image Segmentation
Sep 25, 2020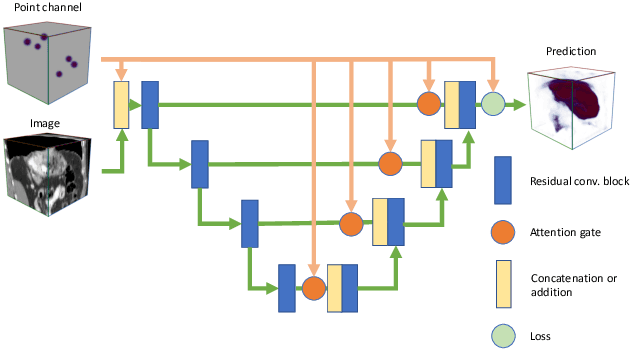
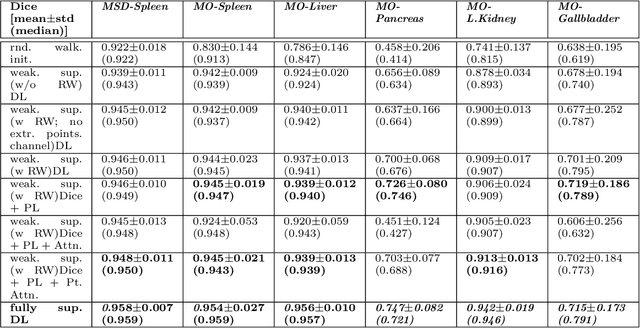
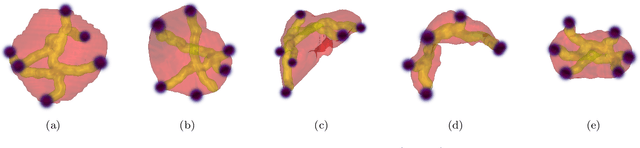

Medical image annotation is a major hurdle for developing precise and robust machine learning models. Annotation is expensive, time-consuming, and often requires expert knowledge, particularly in the medical field. Here, we suggest using minimal user interaction in the form of extreme point clicks to train a segmentation model which, in effect, can be used to speed up medical image annotation. An initial segmentation is generated based on the extreme points utilizing the random walker algorithm. This initial segmentation is then used as a noisy supervision signal to train a fully convolutional network that can segment the organ of interest, based on the provided user clicks. Through experimentation on several medical imaging datasets, we show that the predictions of the network can be refined using several rounds of training with the prediction from the same weakly annotated data. Further improvements are shown utilizing the clicked points within a custom-designed loss and attention mechanism. Our approach has the potential to speed up the process of generating new training datasets for the development of new machine learning and deep learning-based models for, but not exclusively, medical image analysis.