 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised cross-user adaptation in taste sensationrecognition based on surface electromyography withconformal prediction and domain regularizedcomponent analysis
Oct 20, 2021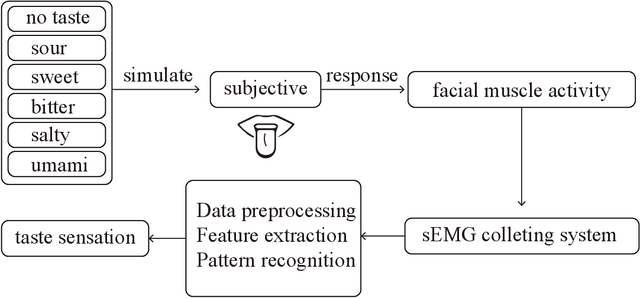

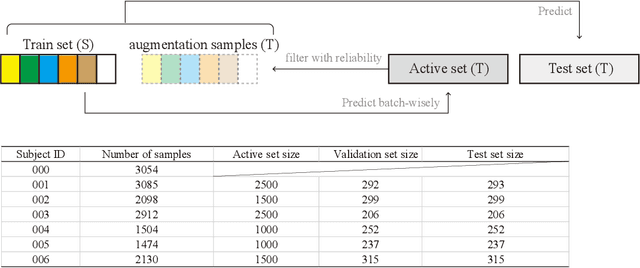
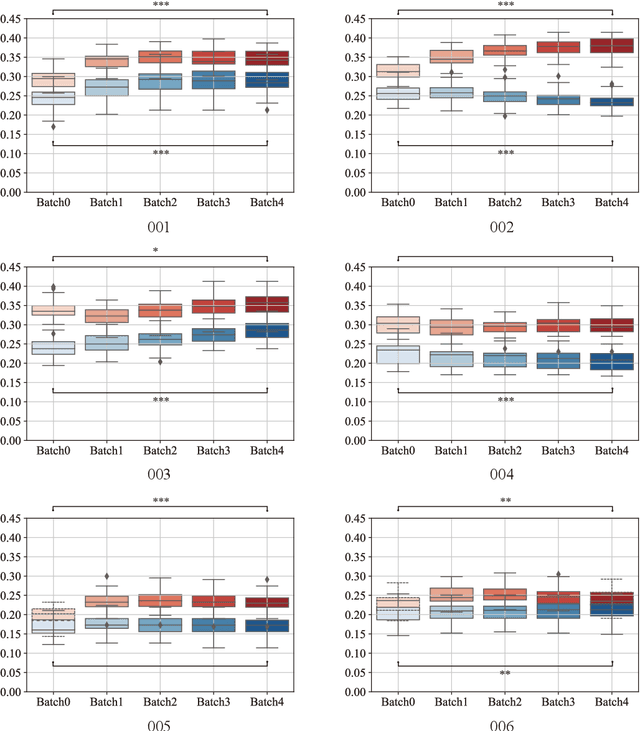
Human taste sensation can be qualitatively described with surface electromyography. However, the pattern recognition models trained on one subject (the source domain) do not generalize well on other subjects (the target domain). To improve the generalizability and transferability of taste sensation models developed with sEMG data, two methods were innovatively applied in this study: domain regularized component analysis (DRCA) and conformal prediction with shrunken centroids (CPSC). The effectiveness of these two methods was investigated independently in an unlabeled data augmentation process with the unlabeled data from the target domain, and the same cross-user adaptation pipeline were conducted on six subjects. The results show that DRCA improved the classification accuracy on six subjects (p < 0.05), compared with the baseline models trained only with the source domain data;, while CPSC did not guarantee the accuracy improvement. Furthermore, the combination of DRCA and CPSC presented statistically significant improvement (p < 0.05) in classification accuracy on six subjects. The proposed strategy combining DRCA and CPSC showed its effectiveness in addressing the cross-user data distribution drift in sEMG-based taste sensation recognition application. It also shows the potential in more cross-user adaptation applications.
Voice Reconstruction from Silent Speech with a Sequence-to-Sequence Model
Jul 31, 2021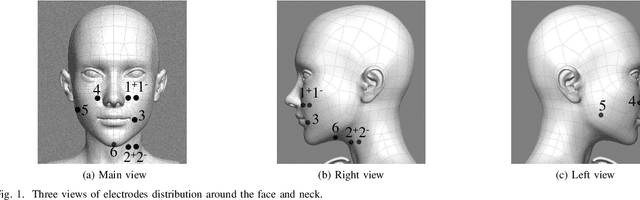
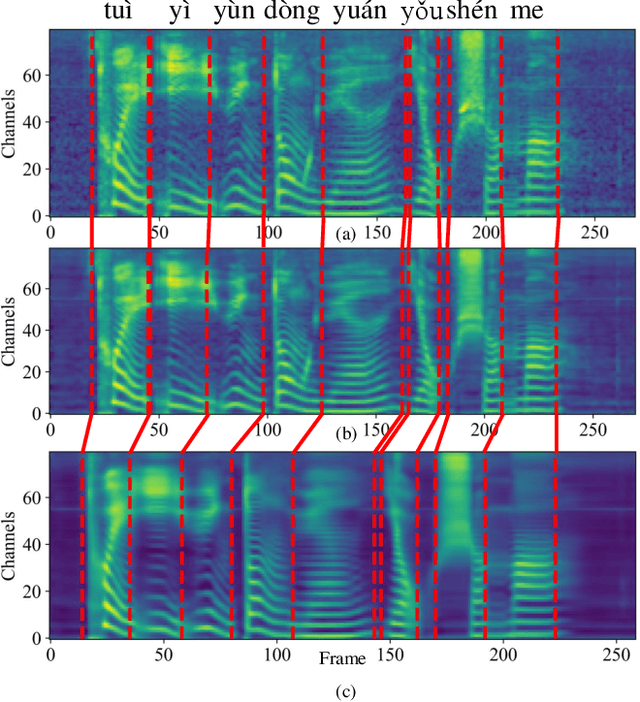
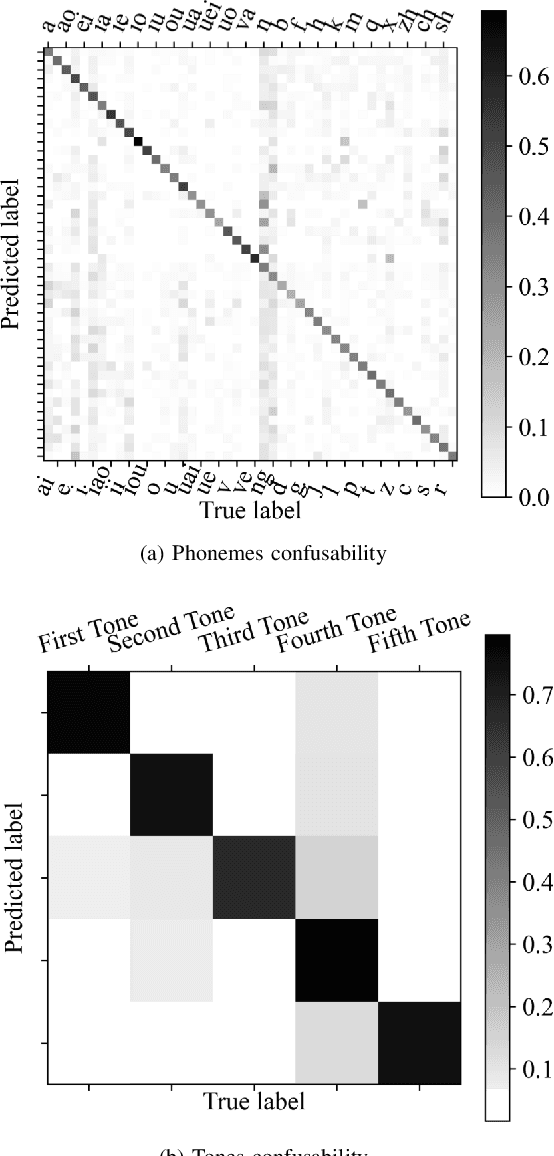
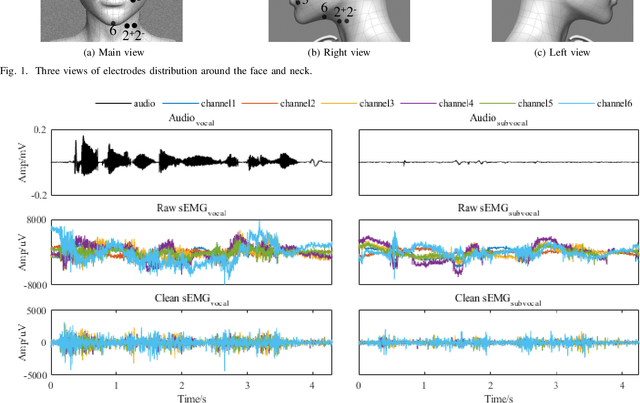
Silent Speech Decoding (SSD) based on Surface electromyography (sEMG) has become a prevalent task in recent years. Though revolutions have been proposed to decode sEMG to audio successfully, some problems still remain. In this paper, we propose an optimized sequence-to-sequence (Seq2Seq) approach to synthesize voice from subvocal sEMG. Both subvocal and vocal sEMG are collected and preprocessed to provide data information. Then, we extract durations from the alignment between subvocal and vocal signals to regulate the subvocal sEMG following audio length. Besides, we use phoneme classification and vocal sEMG reconstruction modules to improve the model performance. Finally, experiments on a Mandarin speaker dataset, which consists of 6.49 hours of data, demonstrate that the proposed model improves the mapping accuracy and voice quality of reconstructed voice.