 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding LLM Fine-tuning via Push-Pull Distributional Alignment
Jan 12, 2026The inherent safety alignment of Large Language Models (LLMs) is prone to erosion during fine-tuning, even when using seemingly innocuous datasets. While existing defenses attempt to mitigate this via data selection, they typically rely on heuristic, instance-level assessments that neglect the global geometry of the data distribution and fail to explicitly repel harmful patterns. To address this, we introduce Safety Optimal Transport (SOT), a novel framework that reframes safe fine-tuning from an instance-level filtering challenge to a distribution-level alignment task grounded in Optimal Transport (OT). At its core is a dual-reference ``push-pull'' weight-learning mechanism: SOT optimizes sample importance by actively pulling the downstream distribution towards a trusted safe anchor while simultaneously pushing it away from a general harmful reference. This establishes a robust geometric safety boundary that effectively purifies the training data. Extensive experiments across diverse model families and domains demonstrate that SOT significantly enhances model safety while maintaining competitive downstream performance, achieving a superior safety-utility trade-off compared to baselines.
Sound source ranging using a feed-forward neural network with fitting-based early stopping
Apr 01, 2019
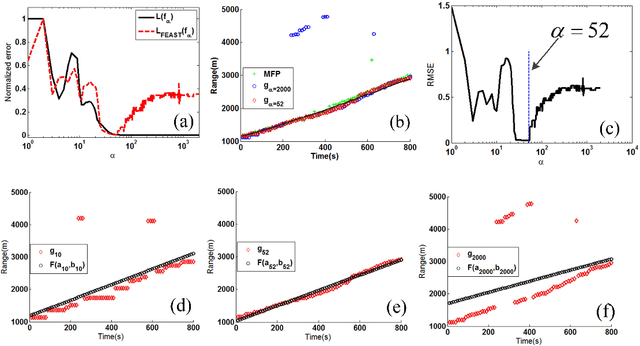
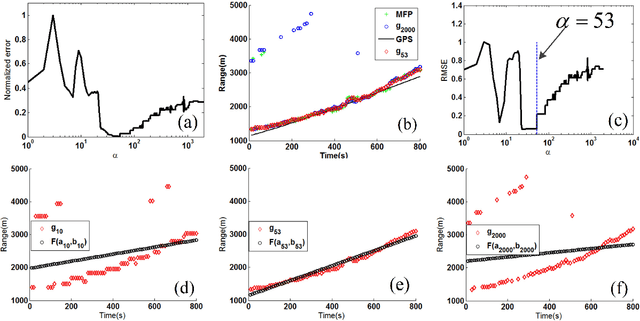
When a feed-forward neural network (FNN) is trained for source ranging in an ocean waveguide, it is difficult evaluating the range accuracy of the FNN on unlabeled test data. A fitting-based early stopping (FEAST) method is introduced to evaluate the range error of the FNN on test data where the distance of source is unknown. Based on FEAST, when the evaluated range error of the FNN reaches the minimum on test data, stopping training, which will help to improve the ranging accuracy of the FNN on the test data. The FEAST is demonstrated on simulated and experimental data.