 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPCFormer: Expression Prompt Collaboration Transformer for Universal Referring Video Object Segmentation
Aug 08, 2023



Audio-guided Video Object Segmentation (A-VOS) and Referring Video Object Segmentation (R-VOS) are two highly-related tasks, which both aim to segment specific objects from video sequences according to user-provided expression prompts. However, due to the challenges in modeling representations for different modalities, contemporary methods struggle to strike a balance between interaction flexibility and high-precision localization and segmentation. In this paper, we address this problem from two perspectives: the alignment representation of audio and text and the deep interaction among audio, text, and visual features. First, we propose a universal architecture, the Expression Prompt Collaboration Transformer, herein EPCFormer. Next, we propose an Expression Alignment (EA) mechanism for audio and text expressions. By introducing contrastive learning for audio and text expressions, the proposed EPCFormer realizes comprehension of the semantic equivalence between audio and text expressions denoting the same objects. Then, to facilitate deep interactions among audio, text, and video features, we introduce an Expression-Visual Attention (EVA) mechanism. The knowledge of video object segmentation in terms of the expression prompts can seamlessly transfer between the two tasks by deeply exploring complementary cues between text and audio. Experiments on well-recognized benchmarks demonstrate that our universal EPCFormer attains state-of-the-art results on both tasks. The source code of EPCFormer will be made publicly available at https://github.com/lab206/EPCFormer.
SSD-MonoDTR: Supervised Scale-constrained Deformable Transformer for Monocular 3D Object Detection
May 12, 2023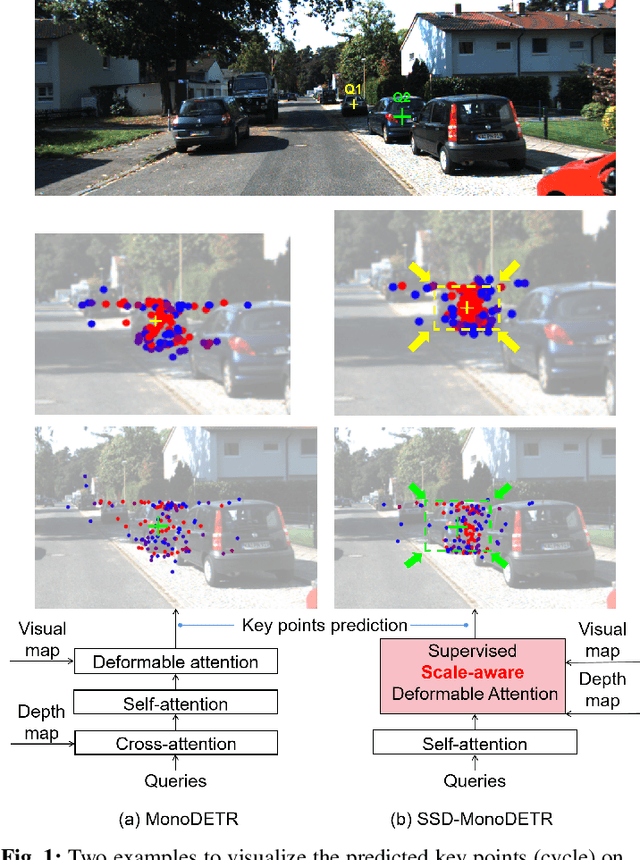



Transformer-based methods have demonstrated superior performance for monocular 3D object detection recently, which predicts 3D attributes from a single 2D image. Most existing transformer-based methods leverage visual and depth representations to explore valuable query points on objects, and the quality of the learned queries has a great impact on detection accuracy. Unfortunately, existing unsupervised attention mechanisms in transformer are prone to generate low-quality query features due to inaccurate receptive fields, especially on hard objects. To tackle this problem, this paper proposes a novel ``Supervised Scale-constrained Deformable Attention'' (SSDA) for monocular 3D object detection. Specifically, SSDA presets several masks with different scales and utilizes depth and visual features to predict the local feature for each query. Imposing the scale constraint, SSDA could well predict the accurate receptive field of a query to support robust query feature generation. What is more, SSDA is assigned with a Weighted Scale Matching (WSM) loss to supervise scale prediction, which presents more confident results as compared to the unsupervised attention mechanisms. Extensive experiments on ``KITTI'' demonstrate that SSDA significantly improves the detection accuracy especially on moderate and hard objects, yielding SOTA performance as compared to the existing approaches. Code will be publicly available at https://github.com/mikasa3lili/SSD-MonoDETR.