 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Model for Multilingual Hope Speech Detection
Jan 31, 2026This paper describes a system that has been submitted to the "PolyHope-M" at RANLP2025. In this work various transformers have been implemented and evaluated for hope speech detection for English and Germany. RoBERTa has been implemented for English, while the multilingual model XLM-RoBERTa has been implemented for both English and German languages. The proposed system using RoBERTa reported a weighted f1-score of 0.818 and an accuracy of 81.8% for English. On the other hand, XLM-RoBERTa achieved a weighted f1-score of 0.786 and an accuracy of 78.5%. These results reflects the importance of improvement of pre-trained large language models and how these models enhancing the performance of different natural language processing tasks.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
BFCAI at SemEval-2022 Task 6: Multi-Layer Perceptron for Sarcasm Detection in Arabic Texts
May 18, 2022
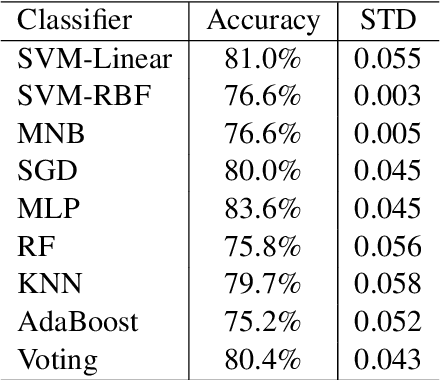

This paper describes the systems submitted to iSarcasm shared task. The aim of iSarcasm is to identify the sarcastic contents in Arabic and English text. Our team participated in iSarcasm for the Arabic language. A multi-Layer machine learning based model has been submitted for Arabic sarcasm detection. In this model, a vector space TF-IDF has been used as for feature representation. The submitted system is simple and does not need any external resources. The test results show encouraging results.