 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBM-Fold: Fully-Differentiable Protein Folding Powered by Energy-based Models
May 31, 2021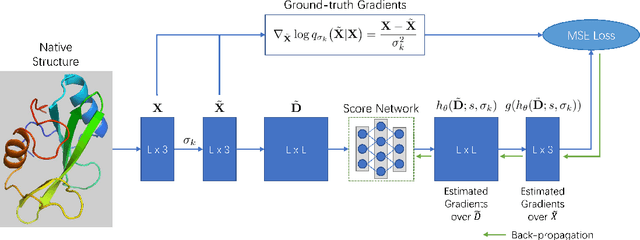



Accurate protein structure prediction from amino-acid sequences is critical to better understanding the protein function. Recent advances in this area largely benefit from more precise inter-residue distance and orientation predictions, powered by deep neural networks. However, the structure optimization procedure is still dominated by traditional tools, e.g. Rosetta, where the structure is solved via minimizing a pre-defined statistical energy function (with optional prediction-based restraints). Such energy function may not be optimal in formulating the whole conformation space of proteins. In this paper, we propose a fully-differentiable approach for protein structure optimization, guided by a data-driven generative network. This network is trained in a denoising manner, attempting to predict the correction signal from corrupted distance matrices between Ca atoms. Once the network is well trained, Langevin dynamics based sampling is adopted to gradually optimize structures from random initialization. Extensive experiments demonstrate that our EBM-Fold approach can efficiently produce high-quality decoys, compared against traditional Rosetta-based structure optimization routines.
tFold-TR: Combining Deep Learning Enhanced Hybrid Potential Energy for Template-Based Modeling Structure Refinement
May 30, 2021



Protein structure prediction has been a grand challenge for over 50 years, owing to its broad scientific and application interests. There are two primary types of modeling algorithms, template-free modeling and template-based modeling. The latter one is suitable for easy prediction tasks and is widely adopted in computer-aided drug discoveries for drug design and screening. Although it has been several decades since its first edition, the current template-based modeling approach suffers from two critical problems: 1) there are many missing regions in the template-query sequence alignment, and 2) the accuracy of the distance pairs from different regions of the template varies, and this information is not well introduced into the modeling. To solve these two problems, we propose a structural optimization process based on template modeling, introducing two neural network models to predict the distance information of the missing regions and the accuracy of the distance pairs of different regions in the template modeling structure. The predicted distances and residue pairwise-specific deviations are incorporated into the potential energy function for structural optimization, which significantly improves the qualities of the original template modeling decoys.