 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Semi-supervised Clustering for Finding Predictive Clusters
Jan 26, 2022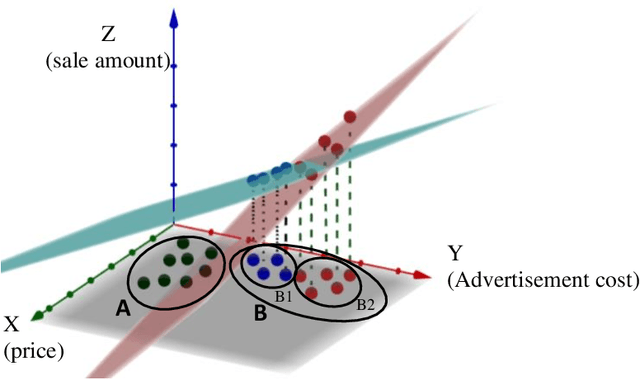
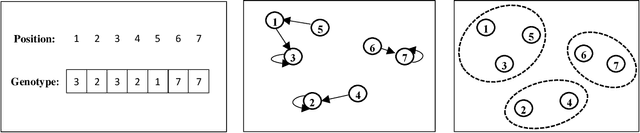
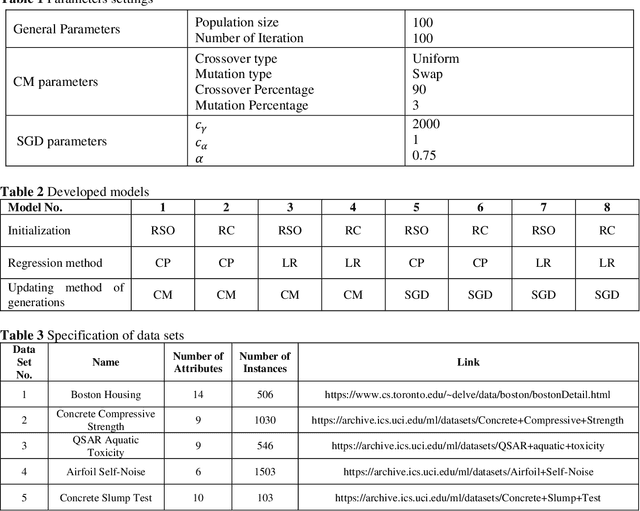

This study concentrates on clustering problems and aims to find compact clusters that are informative regarding the outcome variable. The main goal is partitioning data points so that observations in each cluster are similar and the outcome variable can be predicated using these clusters simultaneously. We model this semi-supervised clustering problem as a multi-objective optimization problem with considering deviation of data points in clusters and prediction error of the outcome variable as two objective functions to be minimized. For finding optimal clustering solutions, we employ a non-dominated sorting genetic algorithm II approach and local regression is applied as prediction method for the output variable. For comparing the performance of the proposed model, we compute seven models using five real-world data sets. Furthermore, we investigate the impact of using local regression for predicting the outcome variable in all models, and examine the performance of the multi-objective models compared to single-objective models.
On the Importance of Diversity in Re-Sampling for Imbalanced Data and Rare Events in Mortality Risk Models
Dec 15, 2020


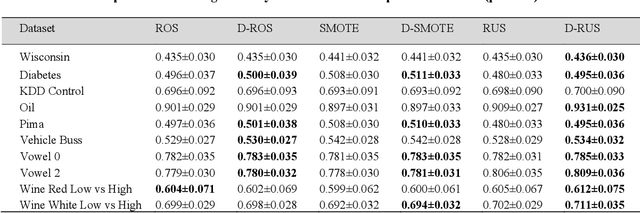
Surgical risk increases significantly when patients present with comorbid conditions. This has resulted in the creation of numerous risk stratification tools with the objective of formulating associated surgical risk to assist both surgeons and patients in decision-making. The Surgical Outcome Risk Tool (SORT) is one of the tools developed to predict mortality risk throughout the entire perioperative period for major elective in-patient surgeries in the UK. In this study, we enhance the original SORT prediction model (UK SORT) by addressing the class imbalance within the dataset. Our proposed method investigates the application of diversity-based selection on top of common re-sampling techniques to enhance the classifier's capability in detecting minority (mortality) events. Diversity amongst training datasets is an essential factor in ensuring re-sampled data keeps an accurate depiction of the minority/majority class region, thereby solving the generalization problem of mainstream sampling approaches. We incorporate the use of the Solow-Polasky measure as a drop-in functionality to evaluate diversity, with the addition of greedy algorithms to identify and discard subsets that share the most similarity. Additionally, through empirical experiments, we prove that the performance of the classifier trained over diversity-based dataset outperforms the original classifier over ten external datasets. Our diversity-based re-sampling method elevates the performance of the UK SORT algorithm by 1.4$.
A new interval-based aggregation approach based on bagging and Interval Agreement Approach (IAA) in ensemble learning
Dec 15, 2020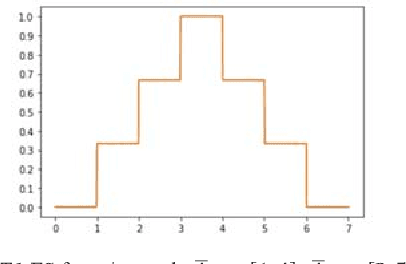
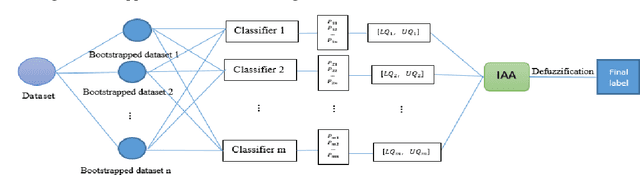

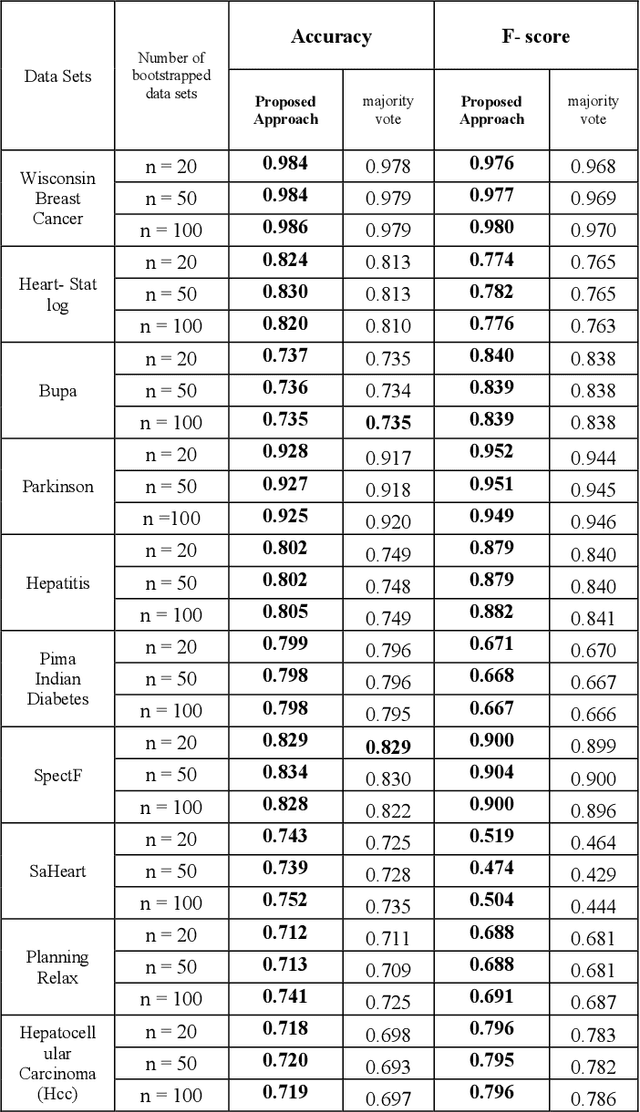
The main aim in ensemble learning is using multiple individual classifiers outputs rather than one classifier output to aggregate them for more accurate classification. Generating an ensemble classifier generally is composed of three steps: selecting the base classifier, applying a sampling strategy to generate different individual classifiers and aggregation the classifiers outputs. This paper focuses on the classifiers outputs aggregation step and presents a new interval-based aggregation modeling using bagging resampling approach and Interval Agreement Approach (IAA) in ensemble learning. IAA is an interesting and practical aggregation approach in decision making which was introduced to combine decision makers opinions when they present their opinions by intervals. In this paper, in addition to implementing a new aggregation approach in ensemble learning, we designed some experiments to encourage researchers to use interval modeling in ensemble learning because it preserves more uncertainty and this leads to more accurate classification. For this purpose, we compared the results of implementing the proposed method to the majority vote as the most common and successful aggregation function in the literature on 10 medical data sets to show the better performance of the interval modeling and the proposed interval-based aggregation function in binary classification when it comes to ensemble learning. The results confirm the good performance of our proposed approach.
Similarity measure for aggregated fuzzy numbers from interval-valued data
Dec 04, 2020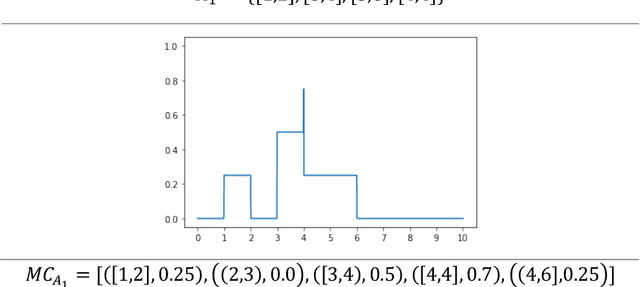
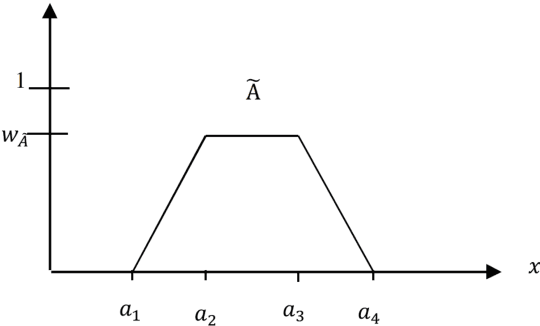
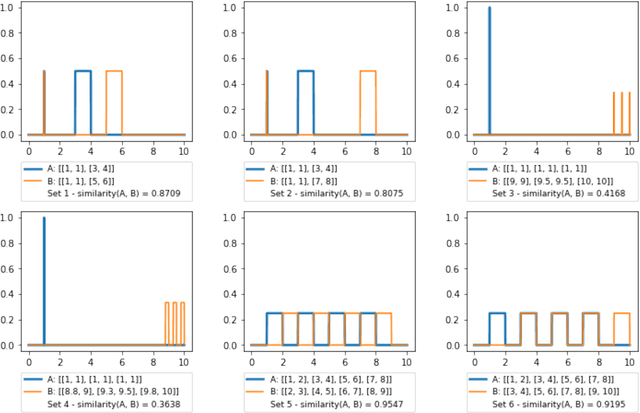
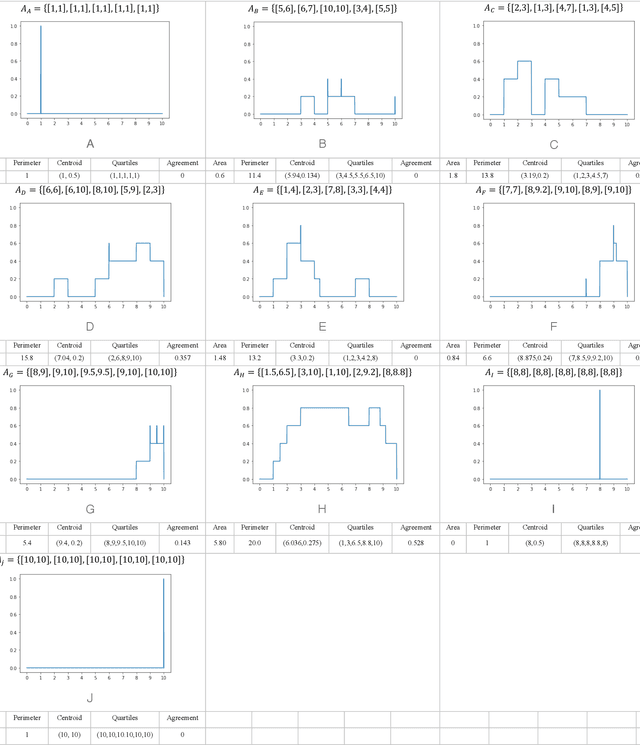
This paper presents a method to compute the degree of similarity between two aggregated fuzzy numbers from intervals using the Interval Agreement Approach (IAA). The similarity measure proposed within this study contains several features and attributes, of which are novel to aggregated fuzzy numbers. The attributes completely redefined or modified within this study include area, perimeter, centroids, quartiles and the agreement ratio. The recommended weighting for each feature has been learned using Principal Component Analysis (PCA). Furthermore, an illustrative example is provided to detail the application and potential future use of the similarity measure.
Methods of ranking for aggregated fuzzy numbers from interval-valued data
Dec 03, 2020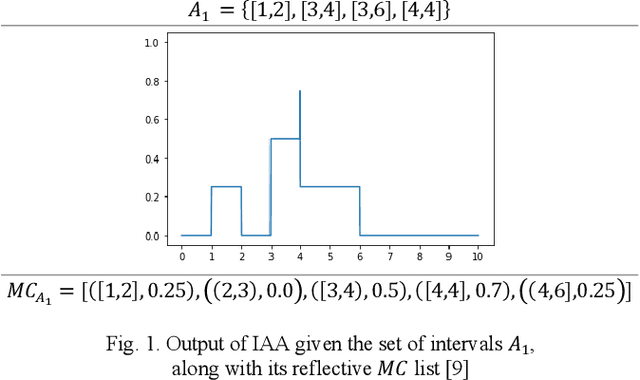
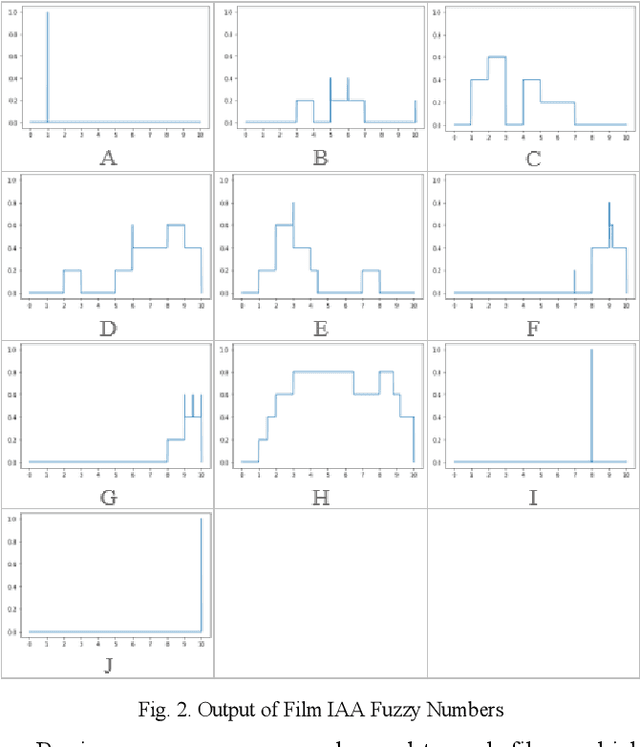
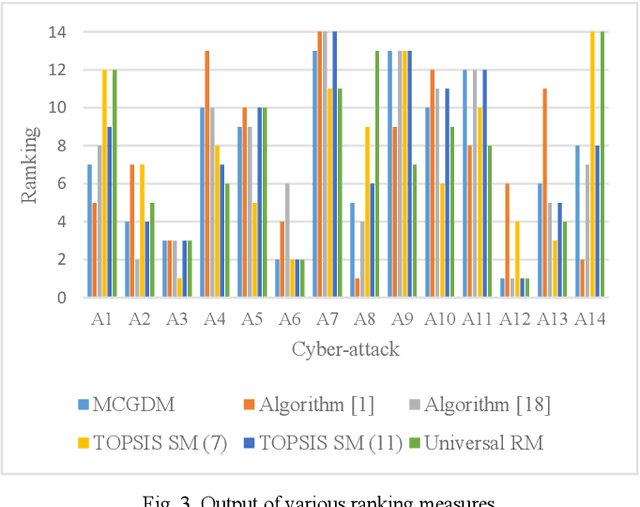
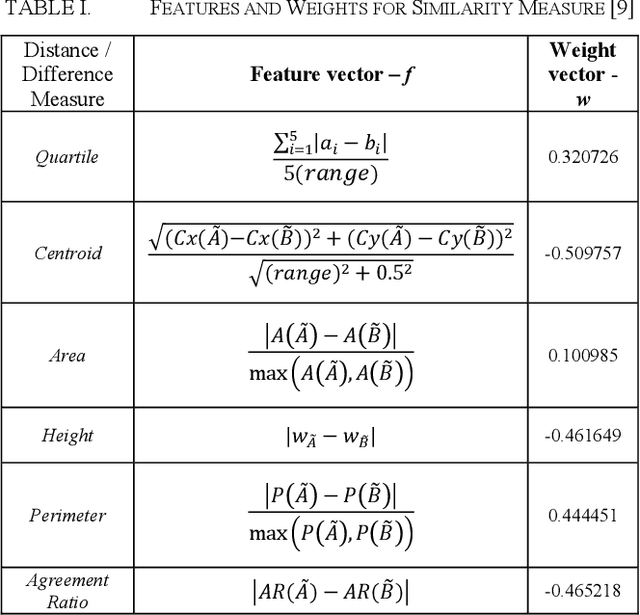
This paper primarily presents two methods of ranking aggregated fuzzy numbers from intervals using the Interval Agreement Approach (IAA). The two proposed ranking methods within this study contain the combination and application of previously proposed similarity measures, along with attributes novel to that of aggregated fuzzy numbers from interval-valued data. The shortcomings of previous measures, along with the improvements of the proposed methods, are illustrated using both a synthetic and real-world application. The real-world application regards the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) algorithm, modified to include both the previous and newly proposed methods.
Transfer learning to enhance amenorrhea status prediction in cancer and fertility data with missing values
Dec 01, 2020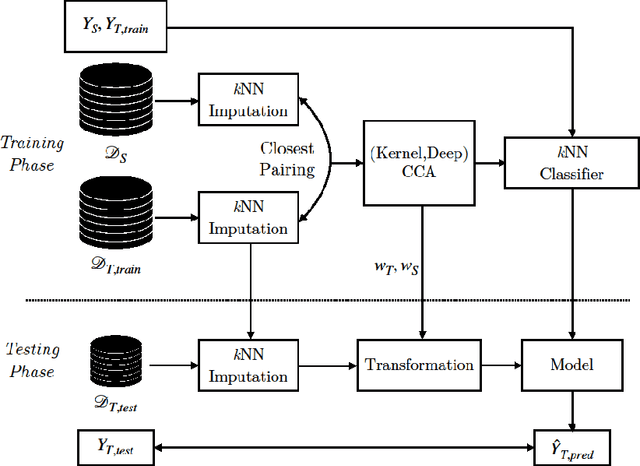
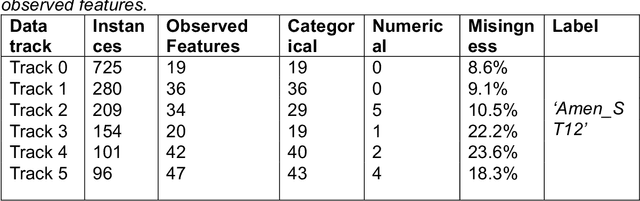
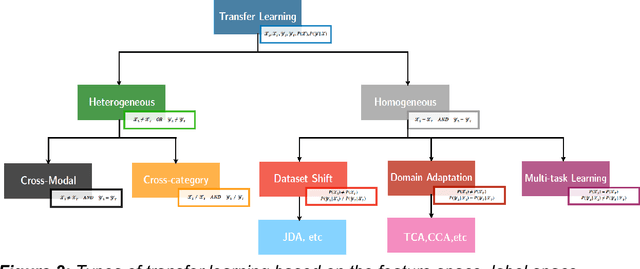
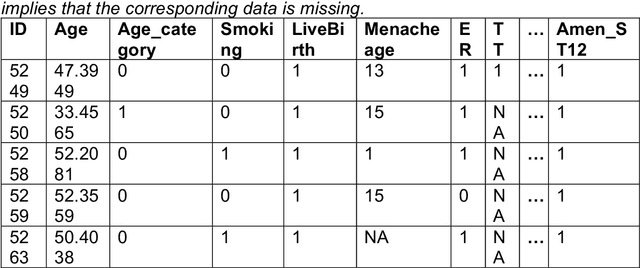
Collecting sufficient labelled training data for health and medical problems is difficult (Antropova, et al., 2018). Also, missing values are unavoidable in health and medical datasets and tackling the problem arising from the inadequate instances and missingness is not straightforward (Snell, et al. 2017, Sterne, et al. 2009). However, machine learning algorithms have achieved significant success in many real-world healthcare problems, such as regression and classification and these techniques could possibly be a way to resolve the issues.
Uncertainty measures for probabilistic hesitant fuzzy sets in multiple criteria decision making
Nov 16, 2020This contribution reviews critically the existing entropy measures for probabilistic hesitant fuzzy sets (PHFSs), and demonstrates that these entropy measures fail to effectively distinguish a variety of different PHFSs in some cases. In the sequel, we develop a new axiomatic framework of entropy measures for probabilistic hesitant fuzzy elements (PHFEs) by considering two facets of uncertainty associated with PHFEs which are known as fuzziness and nonspecificity. Respect to each kind of uncertainty, a number of formulae are derived to permit flexible selection of PHFE entropy measures. Moreover, based on the proposed PHFE entropy measures, we introduce some entropy-based distance measures which are used in the portion of comparative analysis.
Multi-objective semi-supervised clustering to identify health service patterns for injured patients
Nov 16, 2020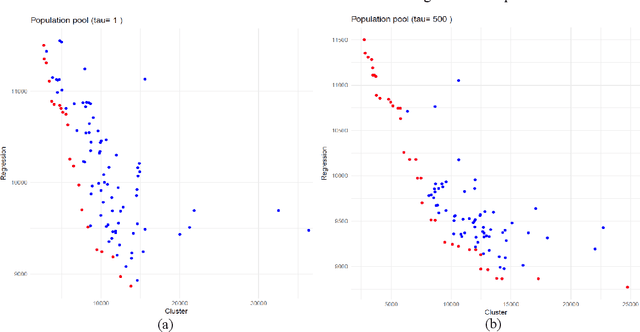
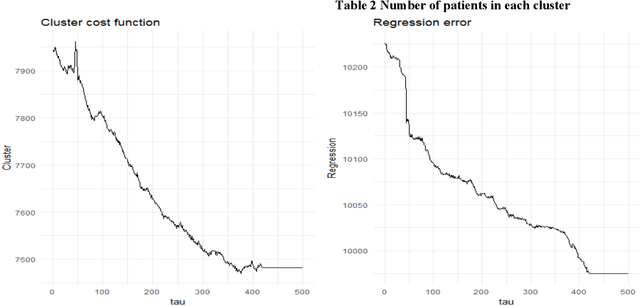
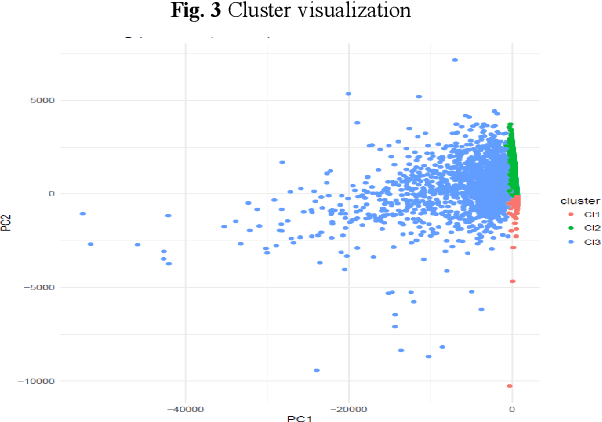
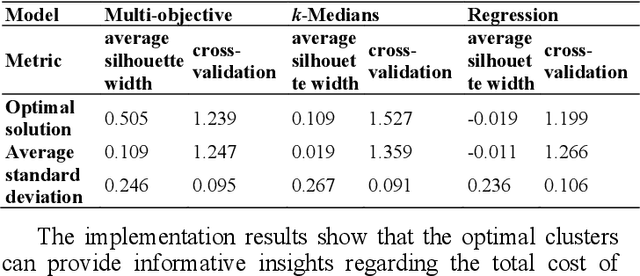
This study develops a pattern recognition method that identifies patterns based on their similarity and their association with the outcome of interest. The practical purpose of developing this pattern recognition method is to group patients, who are injured in transport accidents, in the early stages post-injury. This grouping is based on distinctive patterns in health service use within the first week post-injury. The groups also provide predictive information towards the total cost of medication process. As a result, the group of patients who have undesirable outcomes are identified as early as possible based health service use patterns.
Imputation techniques on missing values in breast cancer treatment and fertility data
Nov 16, 2020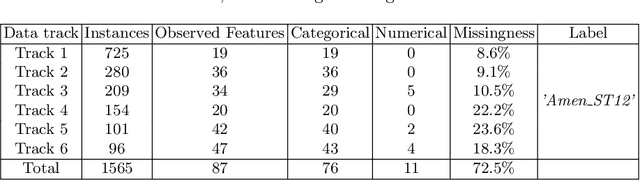
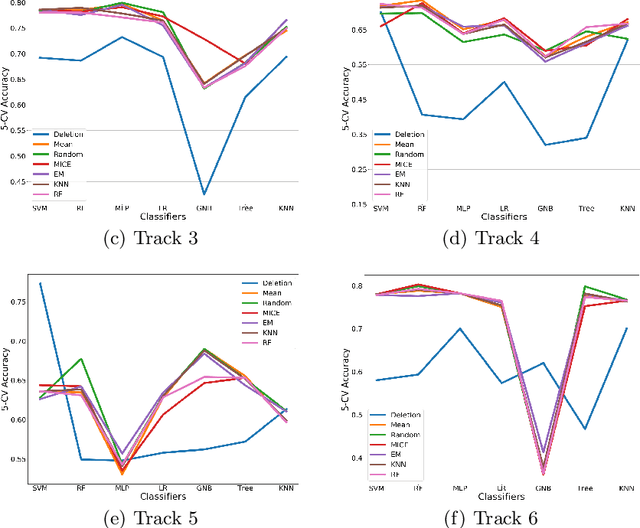
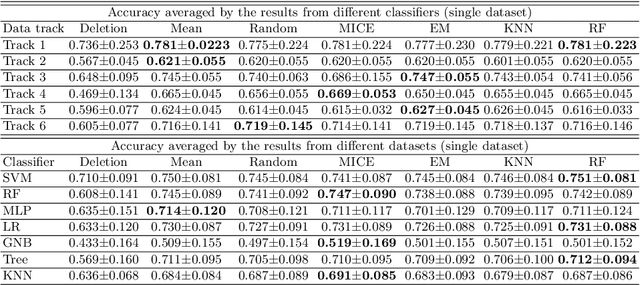
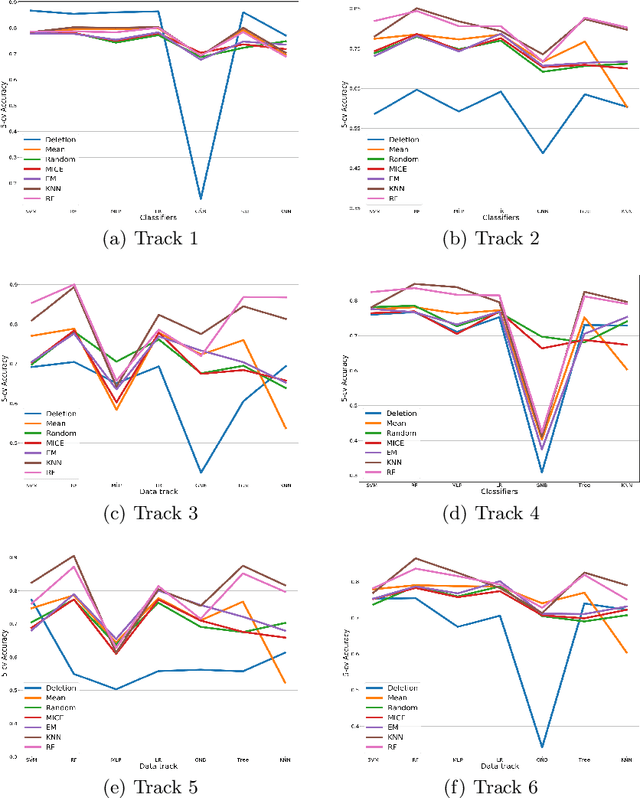
Clinical decision support using data mining techniques offers more intelligent way to reduce the decision error in the last few years. However, clinical datasets often suffer from high missingness, which adversely impacts the quality of modelling if handled improperly. Imputing missing values provides an opportunity to resolve the issue. Conventional imputation methods adopt simple statistical analysis, such as mean imputation or discarding missing cases, which have many limitations and thus degrade the performance of learning. This study examines a series of machine learning based imputation methods and suggests an efficient approach to in preparing a good quality breast cancer (BC) dataset, to find the relationship between BC treatment and chemotherapy-related amenorrhoea, where the performance is evaluated with the accuracy of the prediction.