 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputation techniques on missing values in breast cancer treatment and fertility data
Paper and Code
Nov 16, 2020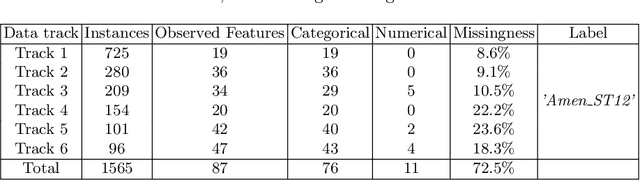
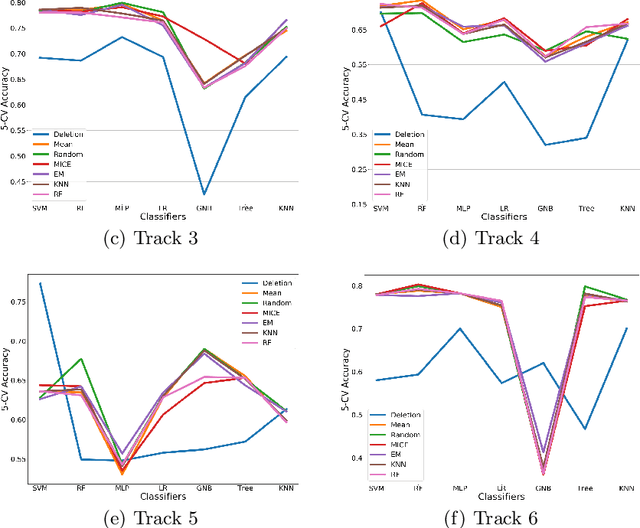
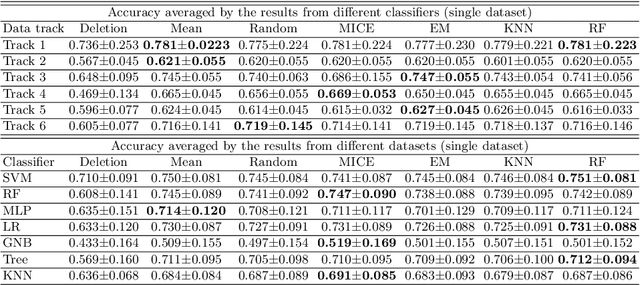
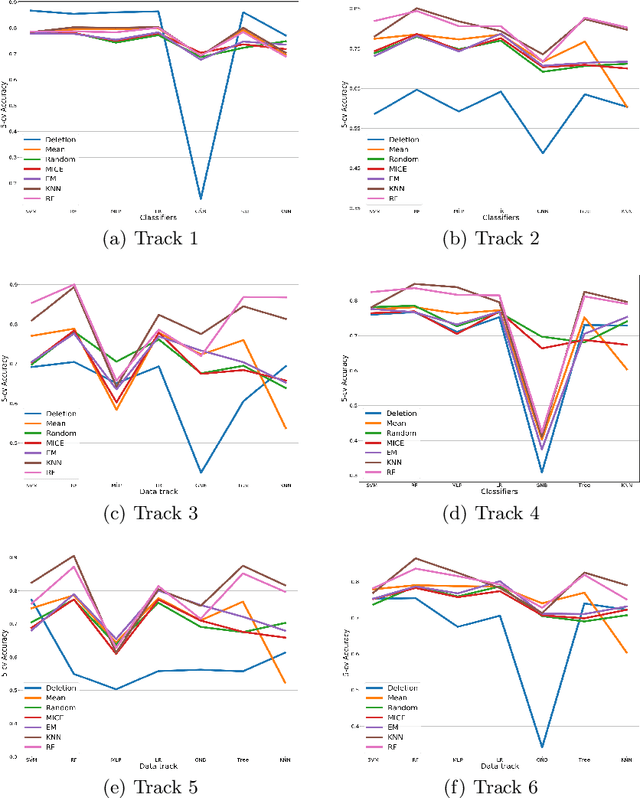
Clinical decision support using data mining techniques offers more intelligent way to reduce the decision error in the last few years. However, clinical datasets often suffer from high missingness, which adversely impacts the quality of modelling if handled improperly. Imputing missing values provides an opportunity to resolve the issue. Conventional imputation methods adopt simple statistical analysis, such as mean imputation or discarding missing cases, which have many limitations and thus degrade the performance of learning. This study examines a series of machine learning based imputation methods and suggests an efficient approach to in preparing a good quality breast cancer (BC) dataset, to find the relationship between BC treatment and chemotherapy-related amenorrhoea, where the performance is evaluated with the accuracy of the prediction.