 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Points Are Equal: Learning Highly Efficient Point-based Detectors for 3D LiDAR Point Clouds
Mar 21, 2022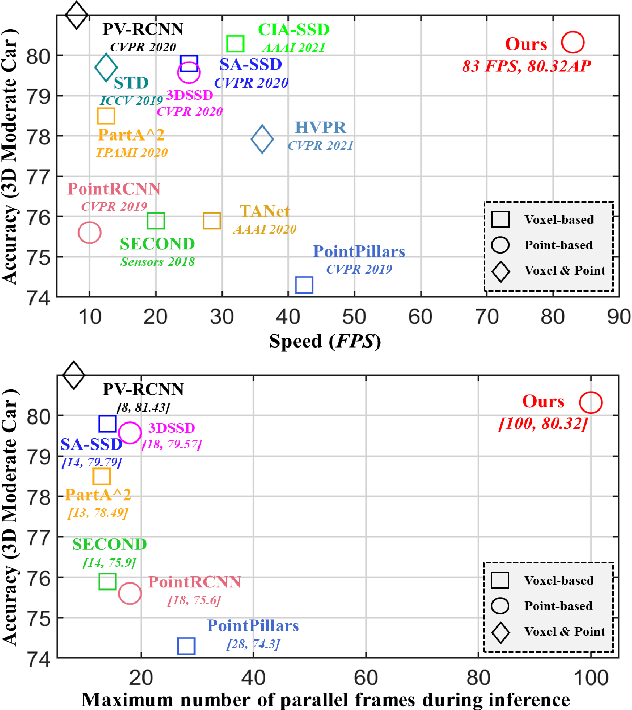

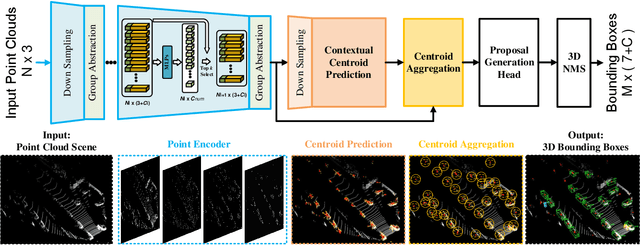
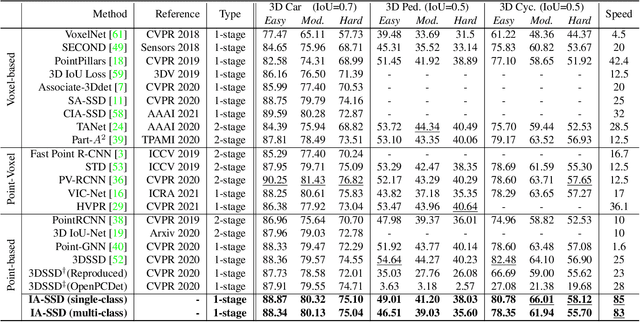
We study the problem of efficient object detection of 3D LiDAR point clouds. To reduce the memory and computational cost, existing point-based pipelines usually adopt task-agnostic random sampling or farthest point sampling to progressively downsample input point clouds, despite the fact that not all points are equally important to the task of object detection. In particular, the foreground points are inherently more important than background points for object detectors. Motivated by this, we propose a highly-efficient single-stage point-based 3D detector in this paper, termed IA-SSD. The key of our approach is to exploit two learnable, task-oriented, instance-aware downsampling strategies to hierarchically select the foreground points belonging to objects of interest. Additionally, we also introduce a contextual centroid perception module to further estimate precise instance centers. Finally, we build our IA-SSD following the encoder-only architecture for efficiency. Extensive experiments conducted on several large-scale detection benchmarks demonstrate the competitive performance of our IA-SSD. Thanks to the low memory footprint and a high degree of parallelism, it achieves a superior speed of 80+ frames-per-second on the KITTI dataset with a single RTX2080Ti GPU. The code is available at \url{https://github.com/yifanzhang713/IA-SSD}.
Adaptive Channel Encoding for Point Cloud Analysis
Dec 05, 2021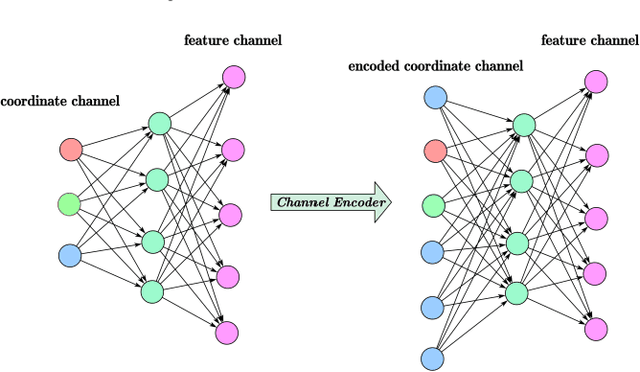

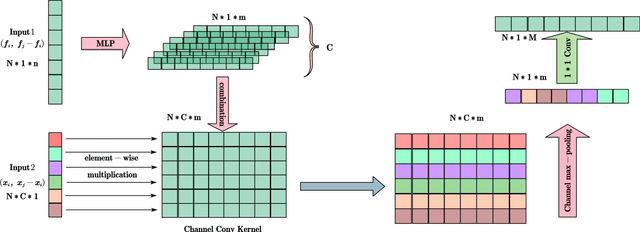
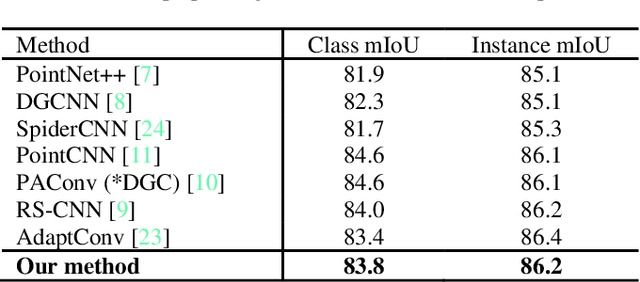
Attention mechanism plays a more and more important role in point cloud analysis and channel attention is one of the hotspots. With so much channel information, it is difficult for neural networks to screen useful channel information. Thus, an adaptive channel encoding mechanism is proposed to capture channel relationships in this paper. It improves the quality of the representation generated by the network by explicitly encoding the interdependence between the channels of its features. Specifically, a channel-wise convolution (Channel-Conv) is proposed to adaptively learn the relationship between coordinates and features, so as to encode the channel. Different from the popular attention weight schemes, the Channel-Conv proposed in this paper realizes adaptability in convolution operation, rather than simply assigning different weights for channels. Extensive experiments on existing benchmarks verify our method achieves the state of the arts.
Adaptive Channel Encoding Transformer for Point Cloud Analysis
Dec 05, 2021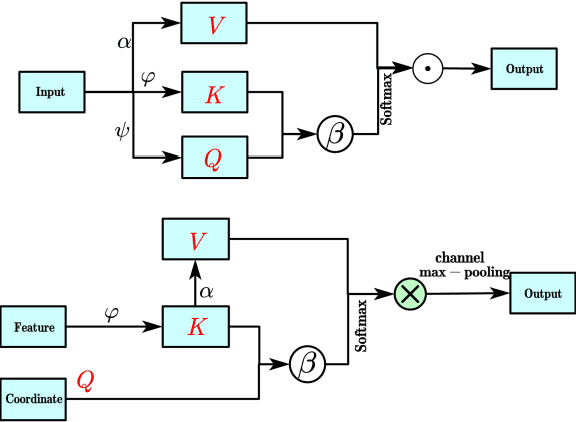
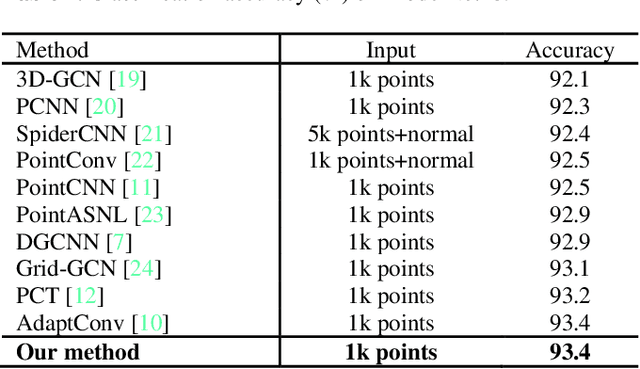
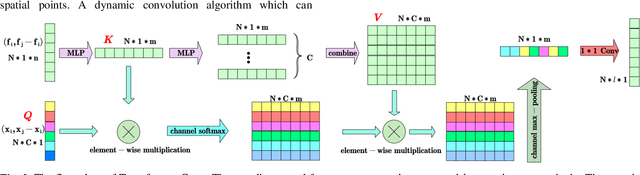
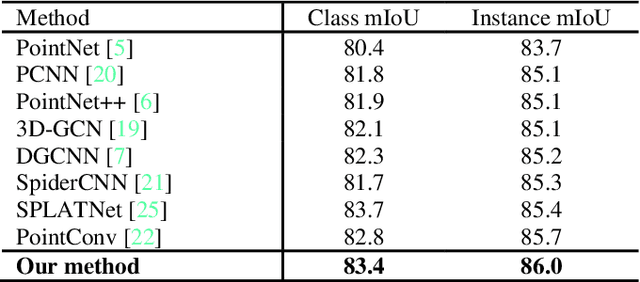
Transformer plays an increasingly important role in various computer vision areas and remarkable achievements have also been made in point cloud analysis. Since they mainly focus on point-wise transformer, an adaptive channel encoding transformer is proposed in this paper. Specifically, a channel convolution called Transformer-Conv is designed to encode the channel. It can encode feature channels by capturing the potential relationship between coordinates and features. Compared with simply assigning attention weight to each channel, our method aims to encode the channel adaptively. In addition, our network adopts the neighborhood search method of low-level and high-level dual semantic receptive fields to improve the performance. Extensive experiments show that our method is superior to state-of-the-art point cloud classification and segmentation methods on three benchmark datasets.
Dual-Neighborhood Deep Fusion Network for Point Cloud Analysis
Aug 20, 2021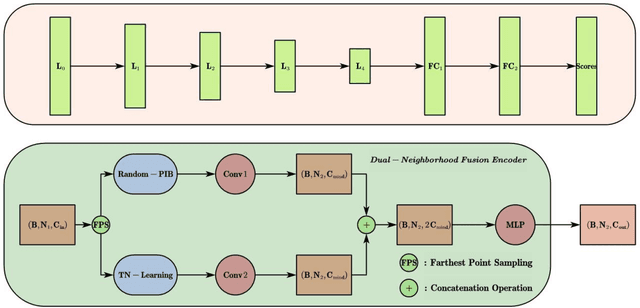
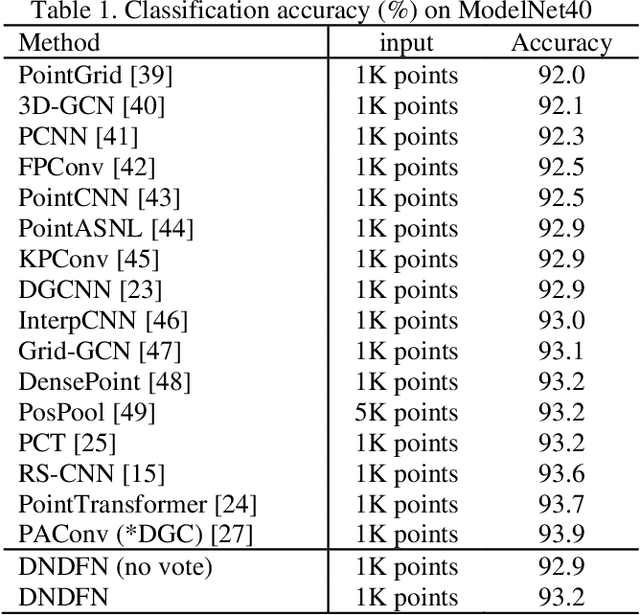
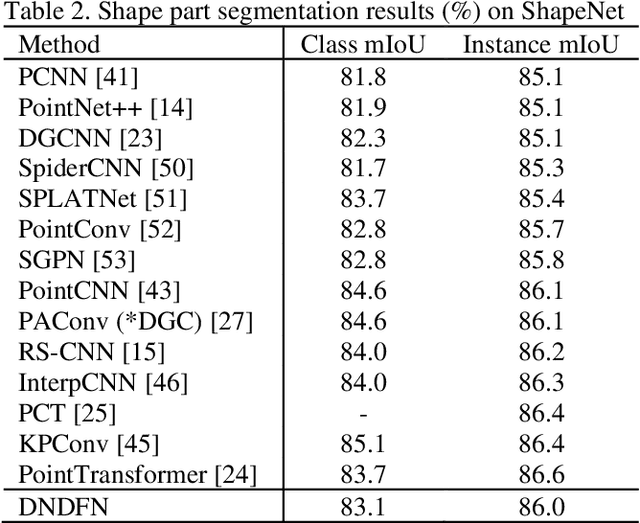

Convolutional neural network has made remarkable achievements in classification of idealized point cloud, however, non-idealized point cloud classification is still a challenging task. In this paper, DNDFN, namely, Dual-Neighborhood Deep Fusion Network, is proposed to deal with this problem. DNDFN has two key points. One is combination of local neighborhood and global neigh-borhood. nearest neighbor (kNN) or ball query can capture the local neighborhood but ignores long-distance dependencies. A trainable neighborhood learning meth-od called TN-Learning is proposed, which can capture the global neighborhood. TN-Learning is combined with them to obtain richer neighborhood information. The other is information transfer convolution (IT-Conv) which can learn the structural information between two points and transfer features through it. Extensive exper-iments on idealized and non-idealized benchmarks across four tasks verify DNDFN achieves the state of the arts.