 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Channel Encoding Transformer for Point Cloud Analysis
Paper and Code
Dec 05, 2021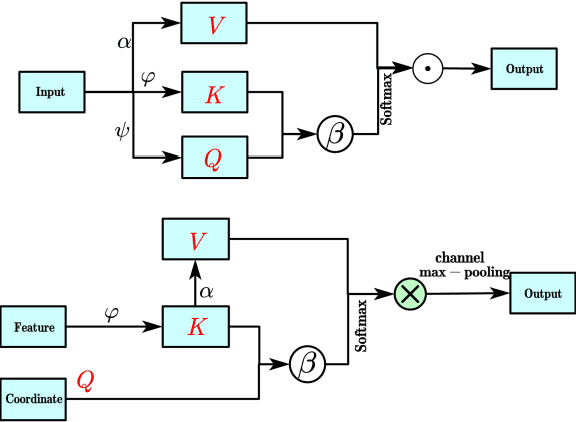
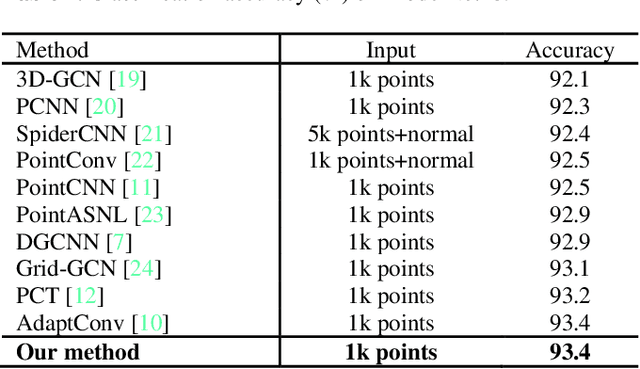
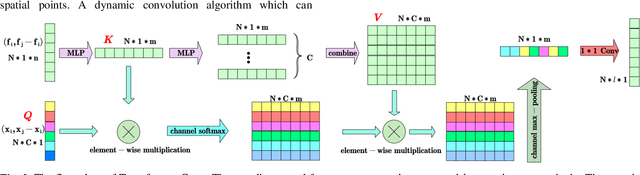
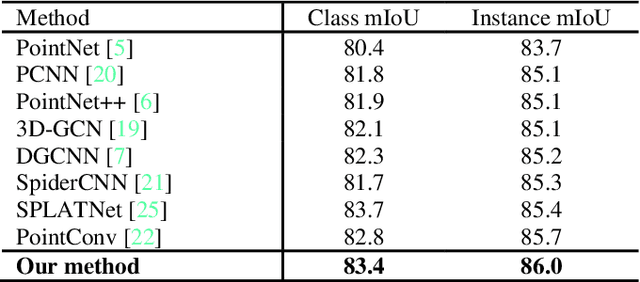
Transformer plays an increasingly important role in various computer vision areas and remarkable achievements have also been made in point cloud analysis. Since they mainly focus on point-wise transformer, an adaptive channel encoding transformer is proposed in this paper. Specifically, a channel convolution called Transformer-Conv is designed to encode the channel. It can encode feature channels by capturing the potential relationship between coordinates and features. Compared with simply assigning attention weight to each channel, our method aims to encode the channel adaptively. In addition, our network adopts the neighborhood search method of low-level and high-level dual semantic receptive fields to improve the performance. Extensive experiments show that our method is superior to state-of-the-art point cloud classification and segmentation methods on three benchmark datasets.