 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deep Model-Based Optoacoustic Image Reconstruction
Aug 13, 2024



Clinical adoption of multispectral optoacoustic tomography necessitates improvements of the image quality available in real-time, as well as a reduction in the scanner financial cost. Deep learning approaches have recently unlocked the reconstruction of high-quality optoacoustic images in real-time. However, currently used deep neural network architectures require powerful graphics processing units to infer images at sufficiently high frame-rates, consequently greatly increasing the price tag. Herein we propose EfficientDeepMB, a relatively lightweight (17M parameters) network architecture achieving high frame-rates on medium-sized graphics cards with no noticeable downgrade in image quality. EfficientDeepMB is built upon DeepMB, a previously established deep learning framework to reconstruct high-quality images in real-time, and upon EfficientNet, a network architectures designed to operate of mobile devices. We demonstrate the performance of EfficientDeepMB in terms of reconstruction speed and accuracy using a large and diverse dataset of in vivo optoacoustic scans. EfficientDeepMB is about three to five times faster than DeepMB: deployed on a medium-sized NVIDIA RTX A2000 Ada, EfficientDeepMB reconstructs images at speeds enabling live image feedback (59Hz) while DeepMB fails to meets the real-time inference threshold (14Hz). The quantitative difference between the reconstruction accuracy of EfficientDeepMB and DeepMB is marginal (data residual norms of 0.1560 vs. 0.1487, mean absolute error of 0.642 vs. 0.745). There are no perceptible qualitative differences between images inferred with the two reconstruction methods.
DeepMB: Deep neural network for real-time model-based optoacoustic image reconstruction with adjustable speed of sound
Jun 29, 2022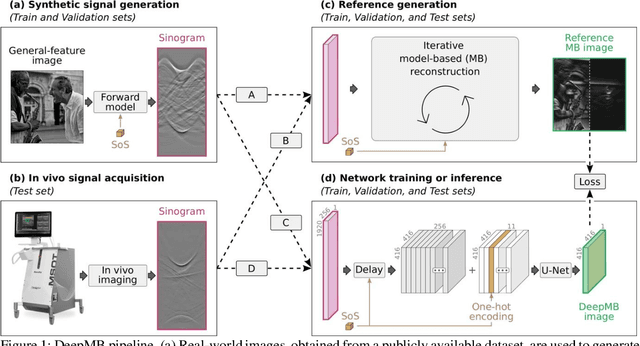
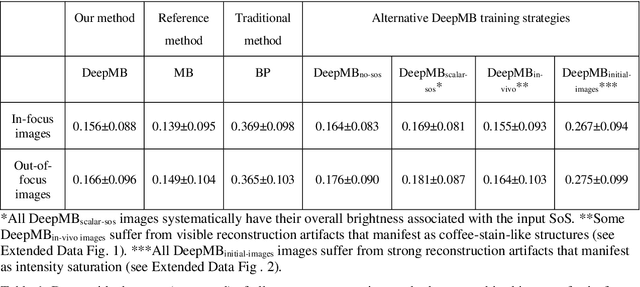

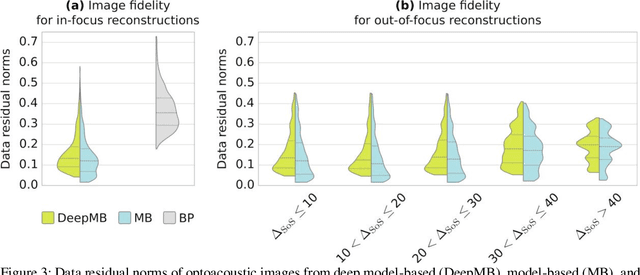
Multispectral optoacoustic tomography (MSOT) is a high-resolution functional imaging modality that can non-invasively access a broad range of pathophysiological phenomena by quantifying the contrast of endogenous chromophores in tissue. Real-time imaging is imperative to translate MSOT into clinical imaging, visualize dynamic pathophysiological changes associated with disease progression, and enable in situ diagnoses. Model-based reconstruction affords state-of-the-art optoacoustic images; however, the advanced image quality provided by model-based reconstruction remains inaccessible during real-time imaging because the algorithm is iterative and computationally demanding. Deep-learning may afford faster reconstructions for real-time optoacoustic imaging, but existing approaches only support oversimplified imaging settings and fail to generalize to in vivo data. In this work, we introduce a novel deep-learning framework, termed DeepMB, to learn the model-based reconstruction operator and infer optoacoustic images with state-of-the-art quality in less than 10 ms per image. DeepMB accurately generalizes to in vivo data after training on synthesized sinograms that are derived from real-world images. The framework affords in-focus images for a broad range of anatomical locations because it supports dynamic adjustment of the reconstruction speed of sound during imaging. Furthermore, DeepMB is compatible with the data rates and image sizes of modern multispectral optoacoustic tomography scanners. We evaluate DeepMB on a diverse dataset of in vivo images and demonstrate that the framework reconstructs images 3000 times faster than the iterative model-based reference method while affording near-identical image qualities. Accurate and real-time image reconstructions with DeepMB can enable full access to the high-resolution and multispectral contrast of handheld optoacoustic tomography.
Carotid artery wall segmentation in ultrasound image sequences using a deep convolutional neural network
Jan 28, 2022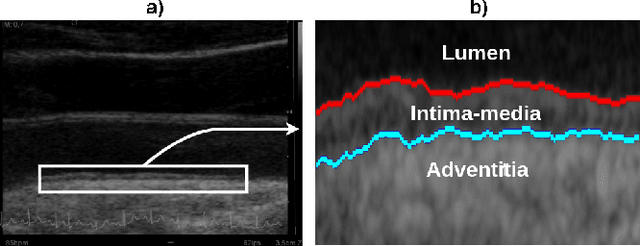
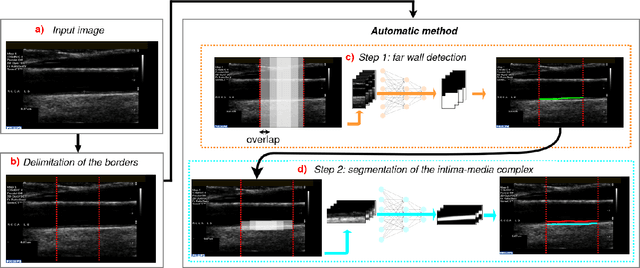
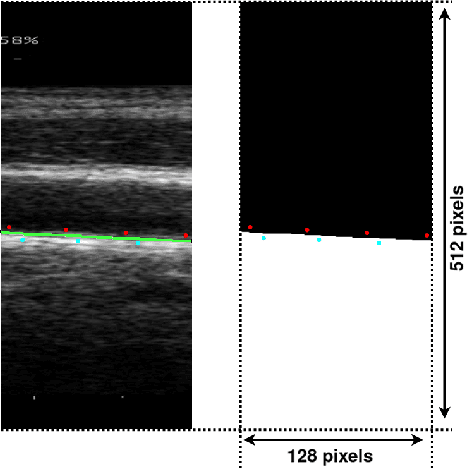
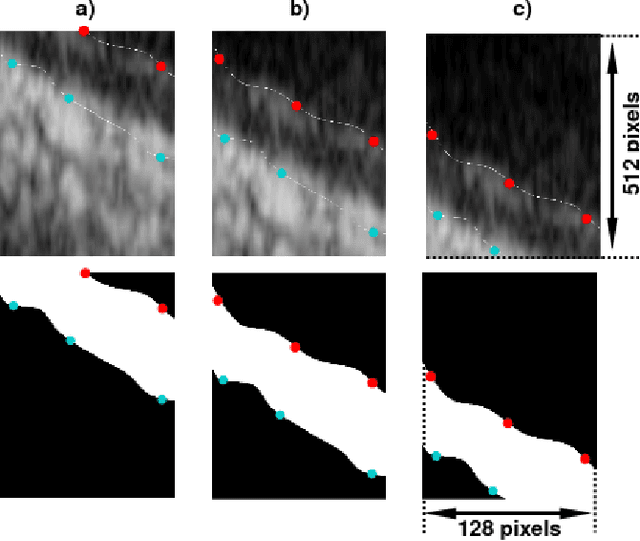
The objective of this study is the segmentation of the intima-media complex of the common carotid artery, on longitudinal ultrasound images, to measure its thickness. We propose a fully automatic region-based segmentation method, involving a supervised region-based deep-learning approach based on a dilated U-net network. It was trained and evaluated using a 5-fold cross-validation on a multicenter database composed of 2176 images annotated by two experts. The resulting mean absolute difference (<120 um) compared to reference annotations was less than the inter-observer variability (180 um). With a 98.7% success rate, i.e., only 1.3% cases requiring manual correction, the proposed method has been shown to be robust and thus may be recommended for use in clinical practice.
Adaptive image-feature learning for disease classification using inductive graph networks
May 08, 2019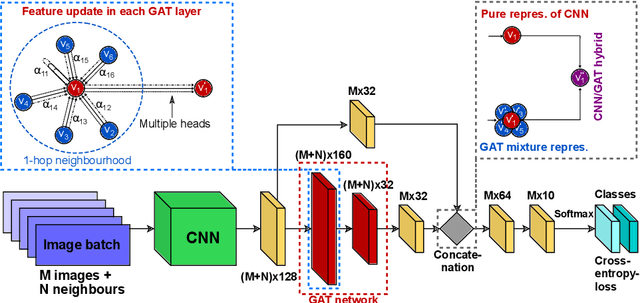
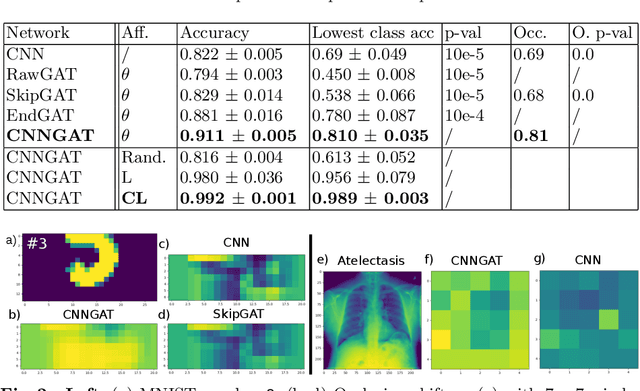

Recently, Geometric Deep Learning (GDL) has been introduced as a novel and versatile framework for computer-aided disease classification. GDL uses patient meta-information such as age and gender to model patient cohort relations in a graph structure. Concepts from graph signal processing are leveraged to learn the optimal mapping of multi-modal features, e.g. from images to disease classes. Related studies so far have considered image features that are extracted in a pre-processing step. We hypothesize that such an approach prevents the network from optimizing feature representations towards achieving the best performance in the graph network. We propose a new network architecture that exploits an inductive end-to-end learning approach for disease classification, where filters from both the CNN and the graph are trained jointly. We validate this architecture against state-of-the-art inductive graph networks and demonstrate significantly improved classification scores on a modified MNIST toy dataset, as well as comparable classification results with higher stability on a chest X-ray image dataset. Additionally, we explain how the structural information of the graph affects both the image filters and the feature learning.
Dynamic Block Matching to assess the longitudinal component of the dense motion field of the carotid artery wall in B-mode ultrasound sequences - Association with coronary artery disease
Sep 21, 2018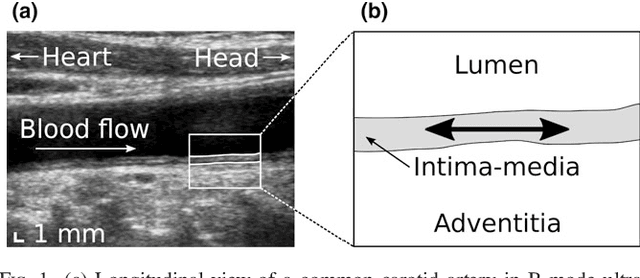
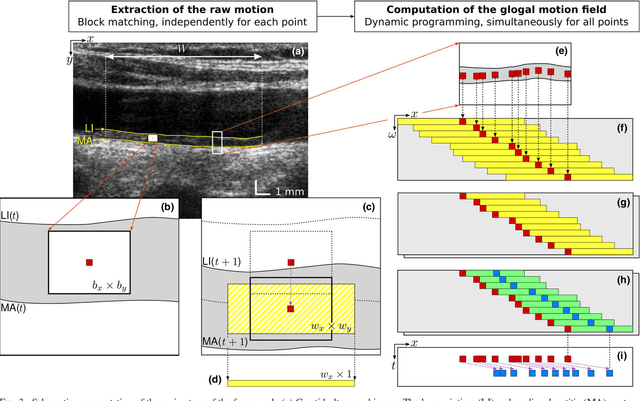
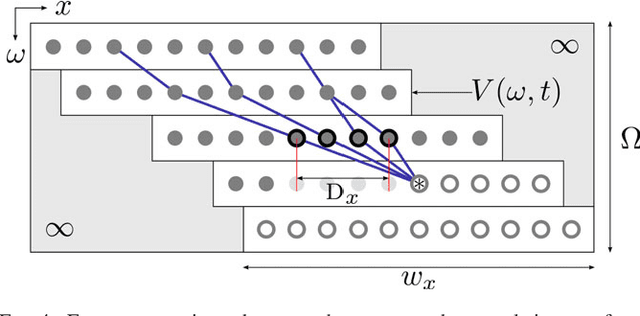
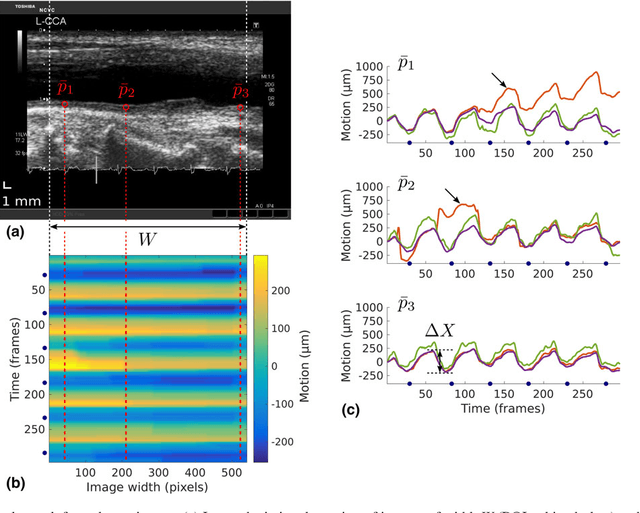
Purpose: The motion of the common carotid artery tissue layers along the vessel axis during the cardiac cycle, observed in ultrasound imaging, is associated with the presence of established cardiovascular risk factors. However, the vast majority of the methods are based on the tracking of a single point, thus failing to capture the overall motion of the entire arterial wall. The aim of this work is to introduce a motion tracking framework able to simultaneously extract the trajectory of a large collection of points spanning the entire exploitable width of the image. Method: The longitudinal motion, which is the main focus of the present work, is determined in two steps. First, a series of independent block matching operations are carried out for all the tracked points. Then, an original dynamic-programming approach is exploited to regularize the collection of similarity maps and estimate the globally optimal motion over the entire vessel wall. Sixty-two atherosclerotic participants at high cardiovascular risk were involved in this study. Results: A dense displacement field, describing the longitudinal motion of the carotid far wall over time, was extracted. For each cine-loop, the method was evaluated against manual reference tracings performed on three local points, with an average absolute error of 150+/-163 um. A strong correlation was found between motion inhomogeneity and the presence of coronary artery disease (beta-coefficient=0.586, p=0.003). Conclusions: To the best of our knowledge, this is the first time that a method is specifically proposed to assess the dense motion field of the carotid far wall. This approach has potential to evaluate the (in)homogeneity of the wall dynamics. The proposed method has promising performances to improve the analysis of arterial longitudinal motion and the understanding of the underlying patho-physiological parameters.