 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Model-Based Clustering With Entropic Optimal Transport
May 05, 2026We develop a new methodology for model-based clustering. Optimizing the log-likelihood provides a principled statistical framework for clustering, with solutions found via the EM algorithm. However, because the log-likelihood is nonconvex, only convergence to stationary points can be guaranteed, and practitioners often use multiple starting points in the hope that one will converge to the global solution. We consider a new loss function based on entropic optimal transport that shares the same global optimum as the log-likelihood but has a much better-behaved landscape, thereby avoiding spurious local-optima configurations that are pervasive with the log-likelihood. Similar to the EM algorithm for the log-likelihood, this new loss can be optimized by the Sinkhorn-EM algorithm, which we show converges at a rate comparable to that of EM. By analyzing extensive numerical experiments and two real-world applications in image segmentation in C. elegans microscopy and clustering in spatial transcriptomics, we show that this new loss outperforms log-likelihood optimization, indicating that it represents a valuable clustering methodology for practitioners.
Wasserstein Parallel Transport for Predicting the Dynamics of Statistical Systems
Mar 24, 2026Many scientific systems, such as cellular populations or economic cohorts, are naturally described by probability distributions that evolve over time. Predicting how such a system would have evolved under different forces or initial conditions is fundamental to causal inference, domain adaptation, and counterfactual prediction. However, the space of distributions often lacks the vector space structure on which classical methods rely. To address this, we introduce a general notion of parallel dynamics at a distributional level. We base this principle on parallel transport of tangent dynamics along optimal transport geodesics and call it ``Wasserstein Parallel Trends''. By replacing the vector subtraction of classic methods with geodesic parallel transport, we can provide counterfactual comparisons of distributional dynamics in applications such as causal inference, domain adaptation, and batch-effect correction in experimental settings. The main mathematical contribution is a novel notion of fanning scheme on the Wasserstein manifold that allows us to efficiently approximate parallel transport along geodesics while also providing the first theoretical guarantees for parallel transport in the Wasserstein space. We also show that Wasserstein Parallel Trends recovers the classic parallel trends assumption for averages as a special case and derive closed-form parallel transport for Gaussian measures. We deploy the method on synthetic data and two single-cell RNA sequencing datasets to impute gene-expression dynamics across biological systems.
Sinkhorn EM: An Expectation-Maximization algorithm based on entropic optimal transport
Jun 30, 2020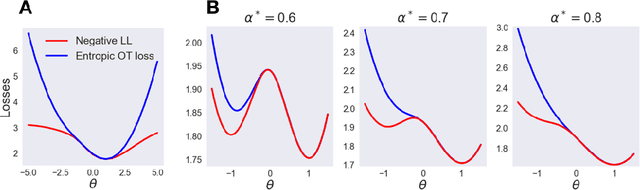
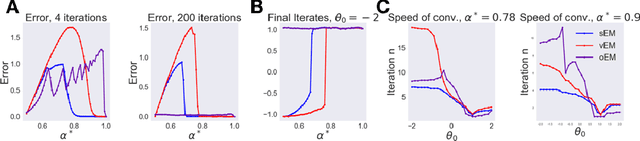
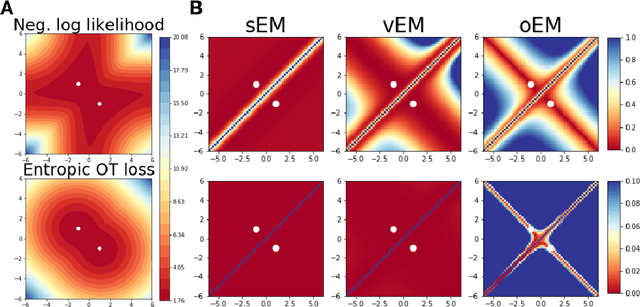
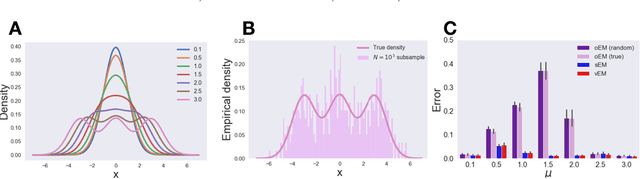
We study Sinkhorn EM (sEM), a variant of the expectation maximization (EM) algorithm for mixtures based on entropic optimal transport. sEM differs from the classic EM algorithm in the way responsibilities are computed during the expectation step: rather than assign data points to clusters independently, sEM uses optimal transport to compute responsibilities by incorporating prior information about mixing weights. Like EM, sEM has a natural interpretation as a coordinate ascent procedure, which iteratively constructs and optimizes a lower bound on the log-likelihood. However, we show theoretically and empirically that sEM has better behavior than EM: it possesses better global convergence guarantees and is less prone to getting stuck in bad local optima. We complement these findings with experiments on simulated data as well as in an inference task involving C. elegans neurons and show that sEM learns cell labels significantly better than other approaches.
Statistical bounds for entropic optimal transport: sample complexity and the central limit theorem
May 30, 2019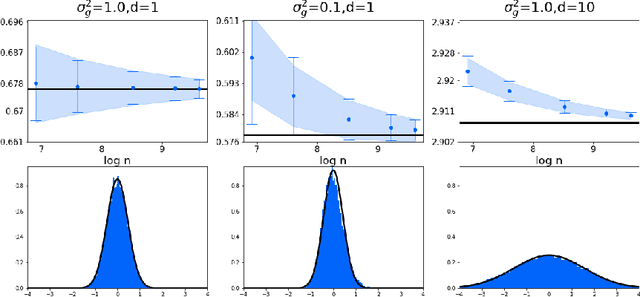
We prove several fundamental statistical bounds for entropic OT with the squared Euclidean cost between subgaussian probability measures in arbitrary dimension. First, through a new sample complexity result we establish the rate of convergence of entropic OT for empirical measures. Our analysis improves exponentially on the bound of Genevay et al. (2019) and extends their work to unbounded measures. Second, we establish a central limit theorem for entropic OT, based on techniques developed by Del Barrio and Loubes (2019). Previously, such a result was only known for finite metric spaces. As an application of our results, we develop and analyze a new technique for estimating the entropy of a random variable corrupted by gaussian noise.
Learning Latent Permutations with Gumbel-Sinkhorn Networks
Feb 23, 2018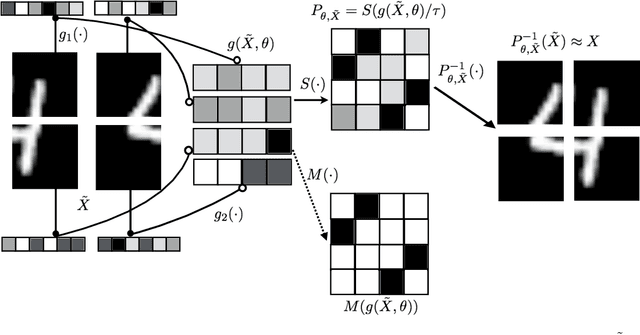



Permutations and matchings are core building blocks in a variety of latent variable models, as they allow us to align, canonicalize, and sort data. Learning in such models is difficult, however, because exact marginalization over these combinatorial objects is intractable. In response, this paper introduces a collection of new methods for end-to-end learning in such models that approximate discrete maximum-weight matching using the continuous Sinkhorn operator. Sinkhorn iteration is attractive because it functions as a simple, easy-to-implement analog of the softmax operator. With this, we can define the Gumbel-Sinkhorn method, an extension of the Gumbel-Softmax method (Jang et al. 2016, Maddison2016 et al. 2016) to distributions over latent matchings. We demonstrate the effectiveness of our method by outperforming competitive baselines on a range of qualitatively different tasks: sorting numbers, solving jigsaw puzzles, and identifying neural signals in worms.