 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning
Aug 09, 2024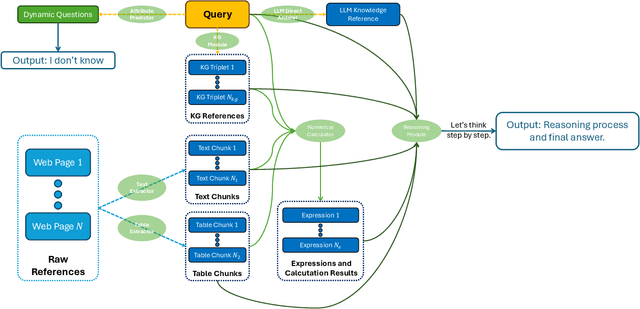
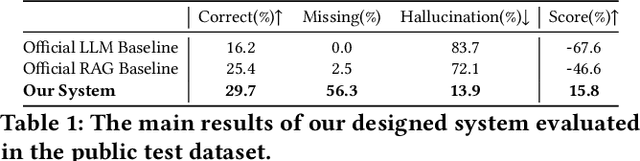
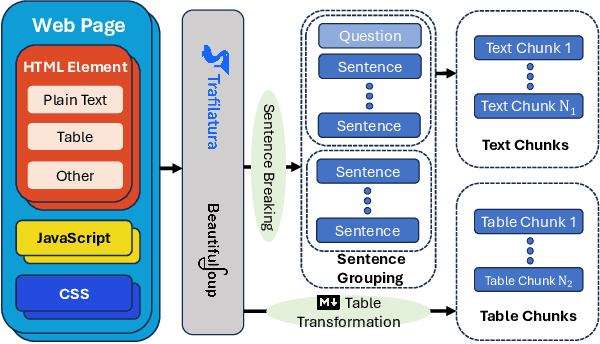
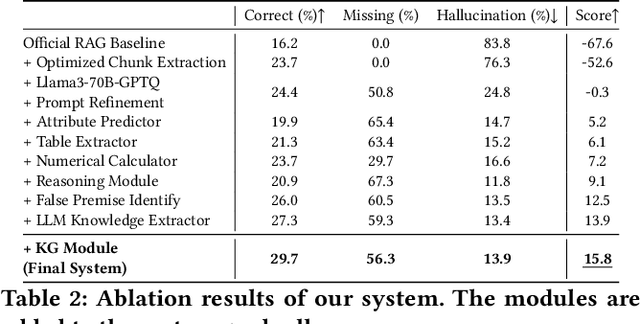
Retrieval-augmented generation (RAG) is a framework enabling large language models (LLMs) to enhance their accuracy and reduce hallucinations by integrating external knowledge bases. In this paper, we introduce a hybrid RAG system enhanced through a comprehensive suite of optimizations that significantly improve retrieval quality, augment reasoning capabilities, and refine numerical computation ability. We refined the text chunks and tables in web pages, added attribute predictors to reduce hallucinations, conducted LLM Knowledge Extractor and Knowledge Graph Extractor, and finally built a reasoning strategy with all the references. We evaluated our system on the CRAG dataset through the Meta CRAG KDD Cup 2024 Competition. Both the local and online evaluations demonstrate that our system significantly enhances complex reasoning capabilities. In local evaluations, we have significantly improved accuracy and reduced error rates compared to the baseline model, achieving a notable increase in scores. In the meanwhile, we have attained outstanding results in online assessments, demonstrating the performance and generalization capabilities of the proposed system. The source code for our system is released in \url{https://gitlab.aicrowd.com/shizueyy/crag-new}.
End-to-End Rubbing Restoration Using Generative Adversarial Networks
May 08, 2022Rubbing restorations are significant for preserving world cultural history. In this paper, we propose the RubbingGAN model for restoring incomplete rubbing characters. Specifically, we collect characters from the Zhang Menglong Bei and build up the first rubbing restoration dataset. We design the first generative adversarial network for rubbing restoration. Based on the dataset we collect, we apply the RubbingGAN to learn the Zhang Menglong Bei font style and restore the characters. The results of experiments show that RubbingGAN can repair both slightly and severely incomplete rubbing characters fast and effectively.