 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLockout: Sparse Regularization of Neural Networks
Jul 15, 2021

Many regression and classification procedures fit a parameterized function $f(x;w)$ of predictor variables $x$ to data $\{x_{i},y_{i}\}_1^N$ based on some loss criterion $L(y,f)$. Often, regularization is applied to improve accuracy by placing a constraint $P(w)\leq t$ on the values of the parameters $w$. Although efficient methods exist for finding solutions to these constrained optimization problems for all values of $t\geq0$ in the special case when $f$ is a linear function, none are available when $f$ is non-linear (e.g. Neural Networks). Here we present a fast algorithm that provides all such solutions for any differentiable function $f$ and loss $L$, and any constraint $P$ that is an increasing monotone function of the absolute value of each parameter. Applications involving sparsity inducing regularization of arbitrary Neural Networks are discussed. Empirical results indicate that these sparse solutions are usually superior to their dense counterparts in both accuracy and interpretability. This improvement in accuracy can often make Neural Networks competitive with, and sometimes superior to, state-of-the-art methods in the analysis of tabular data.
Training Deep Learning models with small datasets
Dec 14, 2019
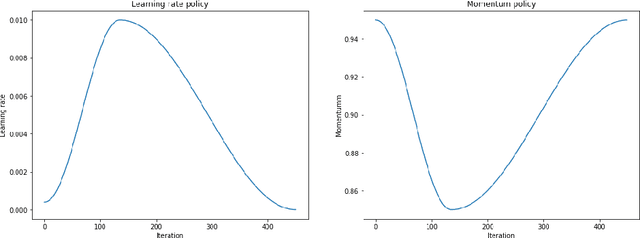
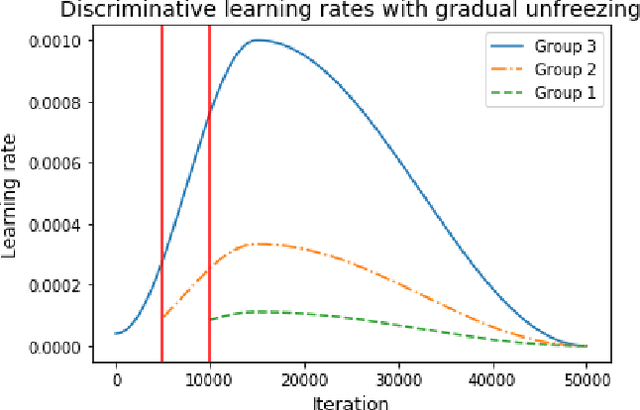
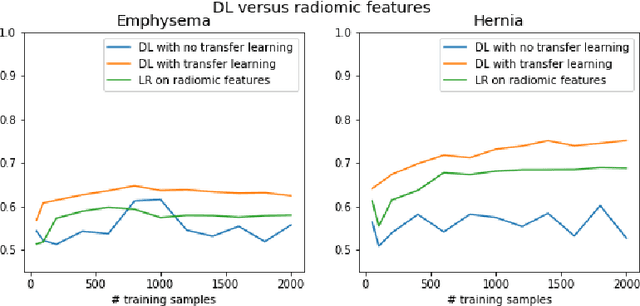
The growing use of Machine Learning has produced significant advances in many fields. For image-based tasks, however, the use of deep learning remains challenging in small datasets. In this article, we review, evaluate and compare the current state of the art techniques in training neural networks to elucidate which techniques work best for small datasets. We further propose a path forward for the improvement of model accuracy in medical imaging applications. We observed best results from one cycle training, discriminative learning rates with gradual freezing and parameter modification after transfer learning. We also established that when datasets are small, transfer learning plays an important role beyond parameter initialization by reusing previously learned features. Surprisingly we observed that there is little advantage in using pre-trained networks in images from another part of the body compared to Imagenet. On the contrary, if images from the same part of the body are available then transfer learning can produce a significant improvement in performance with as little as 50 images in the training data.
Conditional Super Learner
Dec 13, 2019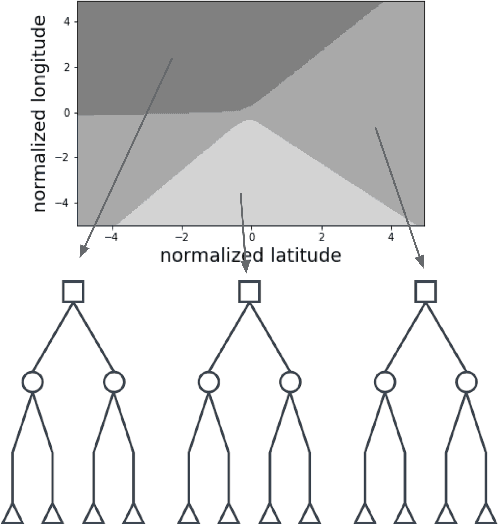
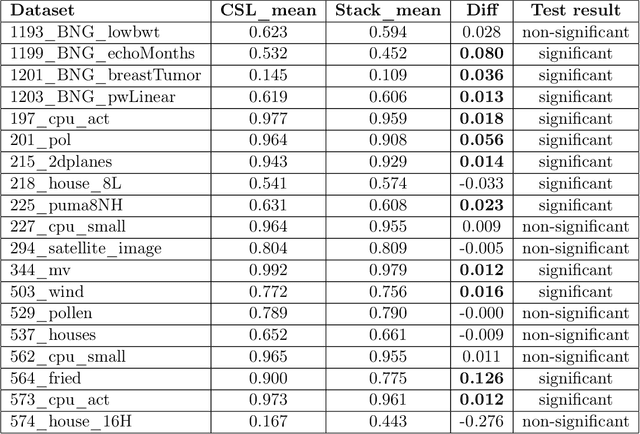
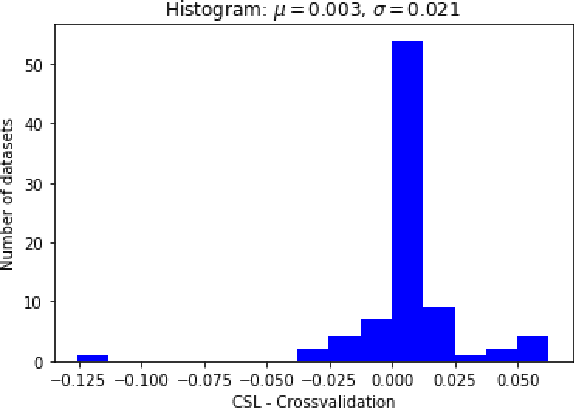
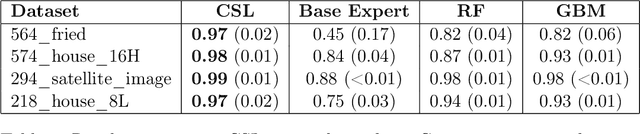
In this article we consider the Conditional Super Learner (CSL), an algorithm which selects the best model candidate from a library conditional on the covariates. The CSL expands the idea of using cross-validation to select the best model and merges it with meta learning. Here we propose a specific algorithm that finds a local minimum to the problem posed, proof that it converges at a rate faster than Op(n^-1/4) and offers extensive empirical evidence that it is an excellent candidate to substitute stacking or for the analysis of Hierarchical problems.
Tree-Structured Boosting: Connections Between Gradient Boosted Stumps and Full Decision Trees
Nov 18, 2017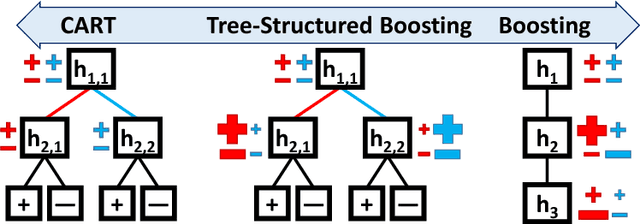
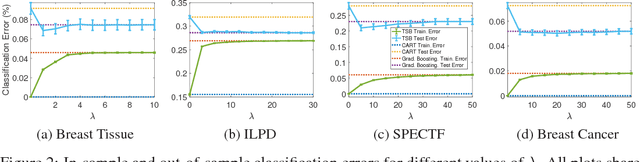
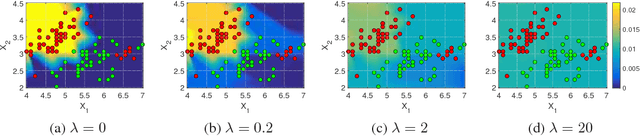
Additive models, such as produced by gradient boosting, and full interaction models, such as classification and regression trees (CART), are widely used algorithms that have been investigated largely in isolation. We show that these models exist along a spectrum, revealing never-before-known connections between these two approaches. This paper introduces a novel technique called tree-structured boosting for creating a single decision tree, and shows that this method can produce models equivalent to CART or gradient boosted stumps at the extremes by varying a single parameter. Although tree-structured boosting is designed primarily to provide both the model interpretability and predictive performance needed for high-stake applications like medicine, it also can produce decision trees represented by hybrid models between CART and boosted stumps that can outperform either of these approaches.