 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Learning of Individualized Task Contrast Prediction from Resting-state Functional Connectomes
Oct 21, 2023Given sufficient pairs of resting-state and task-evoked fMRI scans from subjects, it is possible to train ML models to predict subject-specific task-evoked activity using resting-state functional MRI (rsfMRI) scans. However, while rsfMRI scans are relatively easy to collect, obtaining sufficient task fMRI scans is much harder as it involves more complex experimental designs and procedures. Thus, the reliance on scarce paired data limits the application of current techniques to only tasks seen during training. We show that this reliance can be reduced by leveraging group-average contrasts, enabling zero-shot predictions for novel tasks. Our approach, named OPIC (short for Omni-Task Prediction of Individual Contrasts), takes as input a subject's rsfMRI-derived connectome and a group-average contrast, to produce a prediction of the subject-specific contrast. Similar to zero-shot learning in large language models using special inputs to obtain answers for novel natural language processing tasks, inputting group-average contrasts guides the OPIC model to generalize to novel tasks unseen in training. Experimental results show that OPIC's predictions for novel tasks are not only better than simple group-averages, but are also competitive with a state-of-the-art model's in-domain predictions that was trained using in-domain tasks' data.
GLACIAL: Granger and Learning-based Causality Analysis for Longitudinal Studies
Oct 13, 2022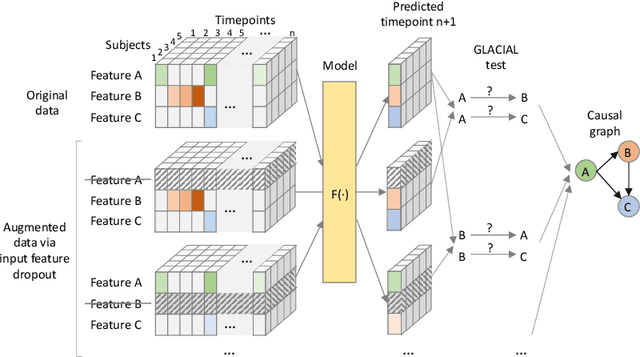
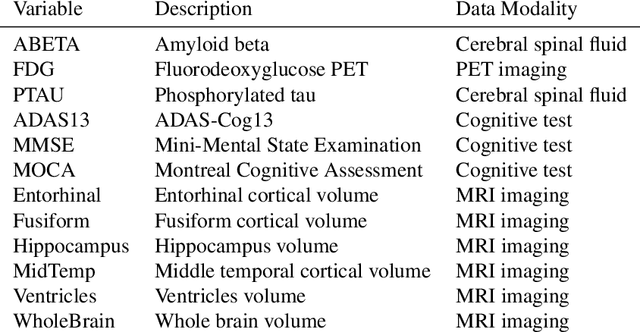
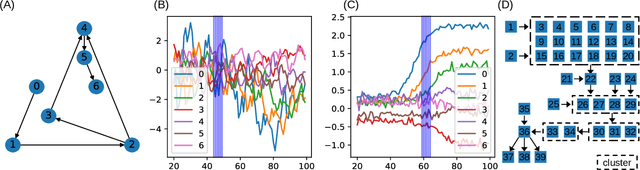
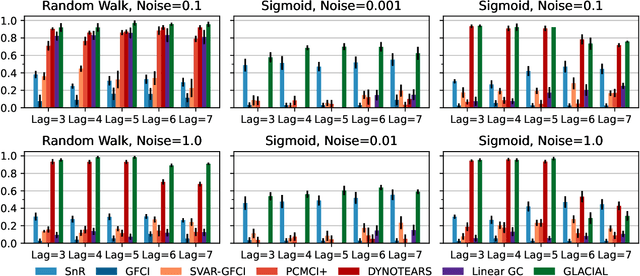
The Granger framework is widely used for discovering causal relationships based on time-varying signals. Implementations of Granger causality (GC) are mostly developed for densely sampled timeseries data. A substantially different setting, particularly common in population health applications, is the longitudinal study design, where multiple individuals are followed and sparsely observed for a limited number of times. Longitudinal studies commonly track many variables, which are likely governed by nonlinear dynamics that might have individual-specific idiosyncrasies and exhibit both direct and indirect causes. Furthermore, real-world longitudinal data often suffer from widespread missingness. GC methods are not well-suited to handle these issues. In this paper, we intend to fill this methodological gap. We propose to marry the GC framework with a machine learning based prediction model. We call our approach GLACIAL, which stands for "Granger and LeArning-based CausalIty Analysis for Longitudinal studies." GLACIAL treats individuals as independent samples and uses average prediction accuracy on hold-out individuals to test for effects of causal relationships. GLACIAL employs a multi-task neural network trained with input feature dropout to efficiently learn nonlinear dynamic relationships between a large number of variables, handle missing values, and probe causal links. Extensive experiments on synthetic and real data demonstrate the utility of GLACIAL and how it can outperform competitive baselines.
A Transformer-based Neural Language Model that Synthesizes Brain Activation Maps from Free-Form Text Queries
Jul 24, 2022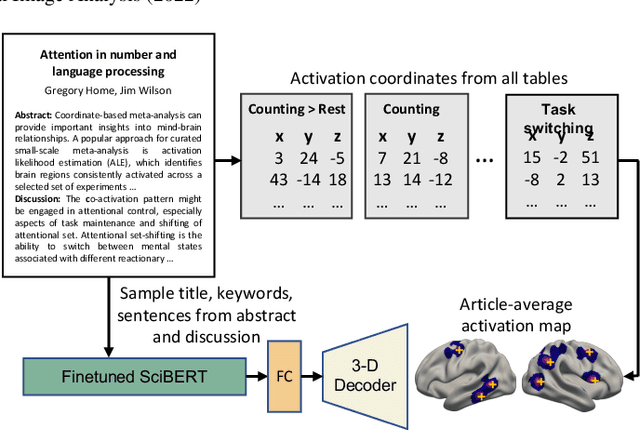
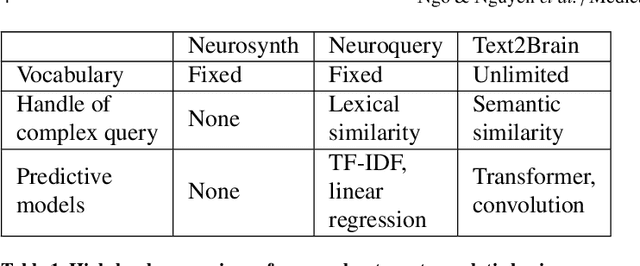
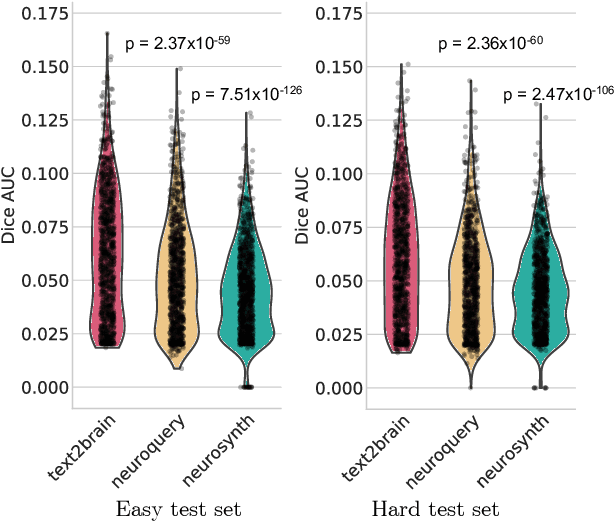
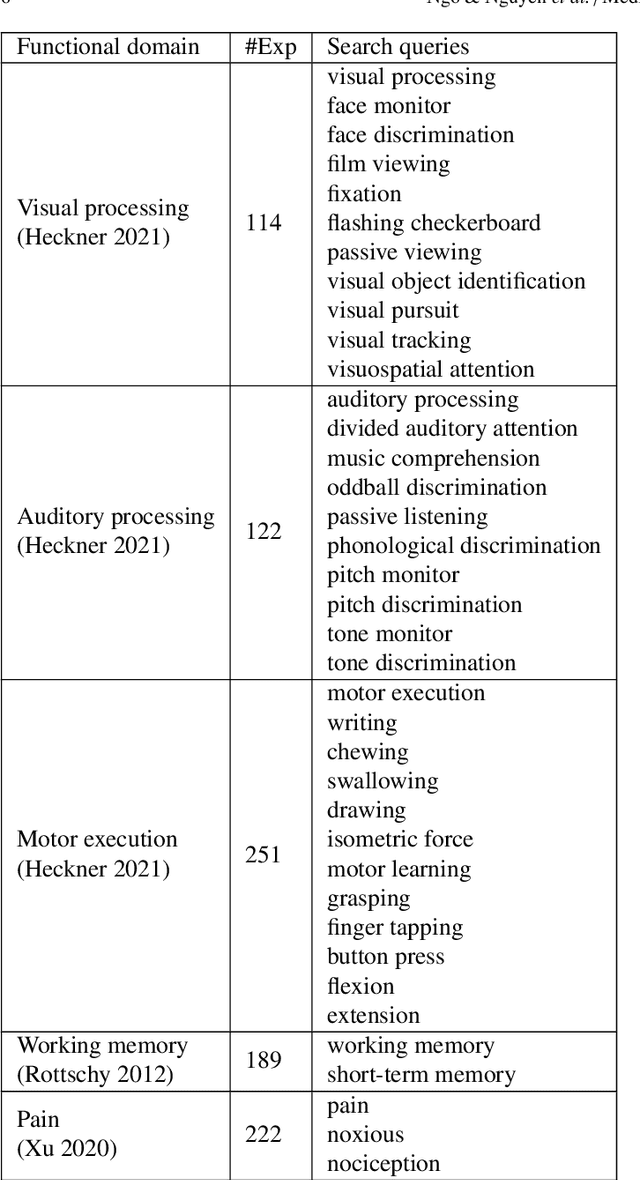
Neuroimaging studies are often limited by the number of subjects and cognitive processes that can be feasibly interrogated. However, a rapidly growing number of neuroscientific studies have collectively accumulated an extensive wealth of results. Digesting this growing literature and obtaining novel insights remains to be a major challenge, since existing meta-analytic tools are constrained to keyword queries. In this paper, we present Text2Brain, an easy to use tool for synthesizing brain activation maps from open-ended text queries. Text2Brain was built on a transformer-based neural network language model and a coordinate-based meta-analysis of neuroimaging studies. Text2Brain combines a transformer-based text encoder and a 3D image generator, and was trained on variable-length text snippets and their corresponding activation maps sampled from 13,000 published studies. In our experiments, we demonstrate that Text2Brain can synthesize meaningful neural activation patterns from various free-form textual descriptions. Text2Brain is available at https://braininterpreter.com as a web-based tool for efficiently searching through the vast neuroimaging literature and generating new hypotheses.
* arXiv admin note: text overlap with arXiv:2109.13814
Text2Brain: Synthesis of Brain Activation Maps from Free-form Text Query
Sep 28, 2021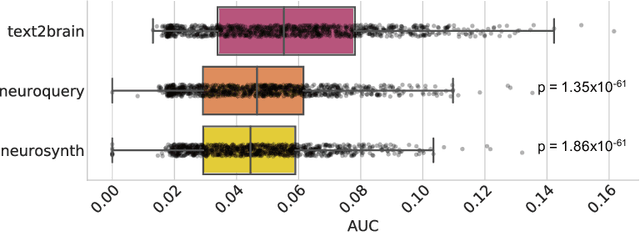
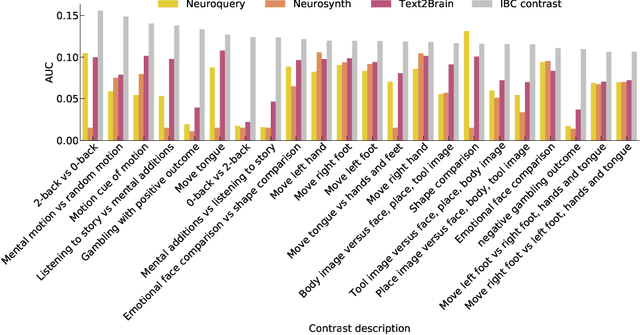
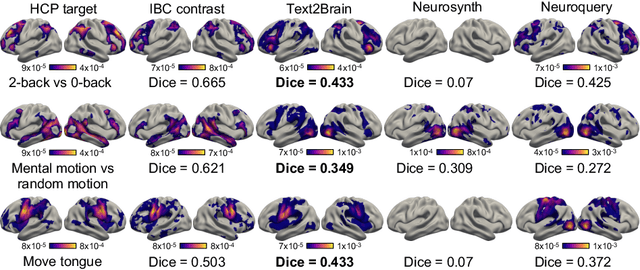
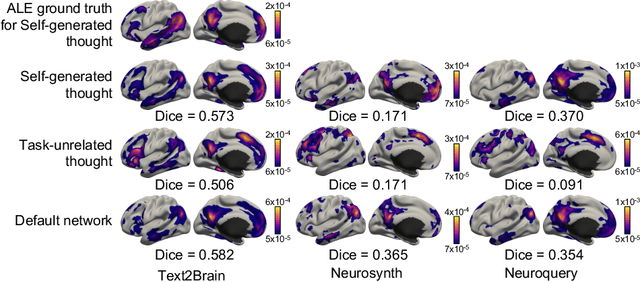
Most neuroimaging experiments are under-powered, limited by the number of subjects and cognitive processes that an individual study can investigate. Nonetheless, over decades of research, neuroscience has accumulated an extensive wealth of results. It remains a challenge to digest this growing knowledge base and obtain new insights since existing meta-analytic tools are limited to keyword queries. In this work, we propose Text2Brain, a neural network approach for coordinate-based meta-analysis of neuroimaging studies to synthesize brain activation maps from open-ended text queries. Combining a transformer-based text encoder and a 3D image generator, Text2Brain was trained on variable-length text snippets and their corresponding activation maps sampled from 13,000 published neuroimaging studies. We demonstrate that Text2Brain can synthesize anatomically-plausible neural activation patterns from free-form textual descriptions of cognitive concepts. Text2Brain is available at https://braininterpreter.com as a web-based tool for retrieving established priors and generating new hypotheses for neuroscience research.
Neural encoding with visual attention
Oct 01, 2020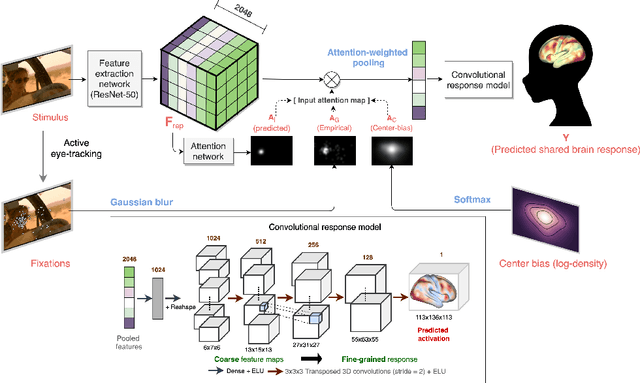
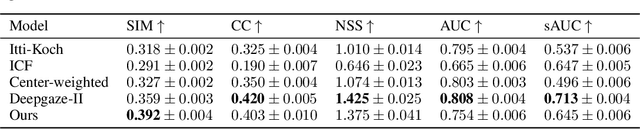
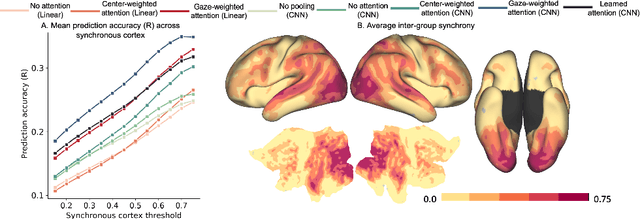
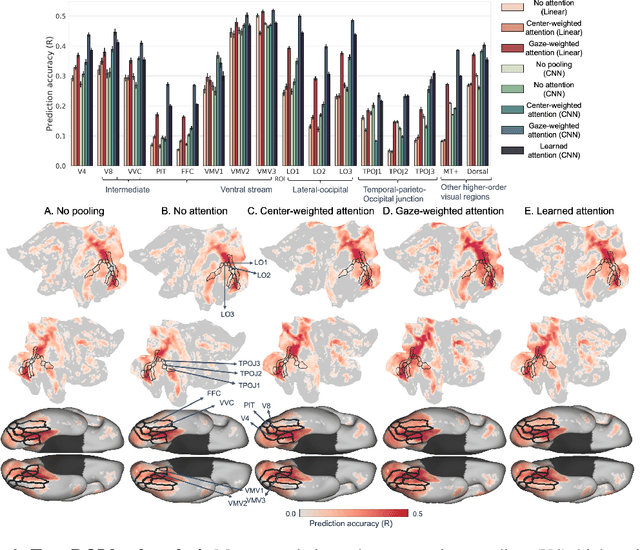
Visual perception is critically influenced by the focus of attention. Due to limited resources, it is well known that neural representations are biased in favor of attended locations. Using concurrent eye-tracking and functional Magnetic Resonance Imaging (fMRI) recordings from a large cohort of human subjects watching movies, we first demonstrate that leveraging gaze information, in the form of attentional masking, can significantly improve brain response prediction accuracy in a neural encoding model. Next, we propose a novel approach to neural encoding by including a trainable soft-attention module. Using our new approach, we demonstrate that it is possible to learn visual attention policies by end-to-end learning merely on fMRI response data, and without relying on any eye-tracking. Interestingly, we find that attention locations estimated by the model on independent data agree well with the corresponding eye fixation patterns, despite no explicit supervision to do so. Together, these findings suggest that attention modules can be instrumental in neural encoding models of visual stimuli.
Adaptable Filtering using Hierarchical Embeddings for Chinese Spell Check
Aug 27, 2020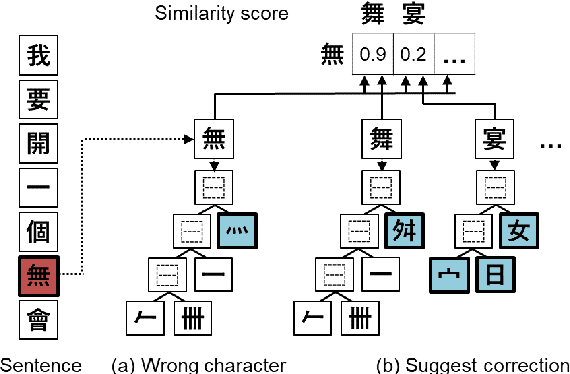
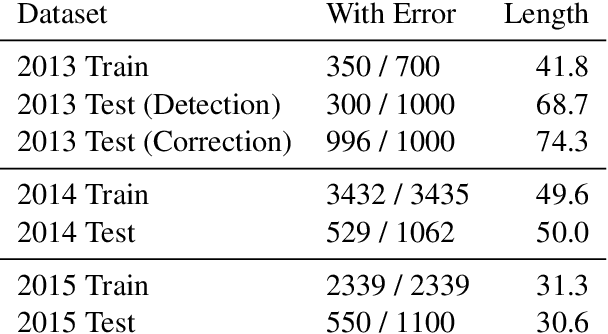
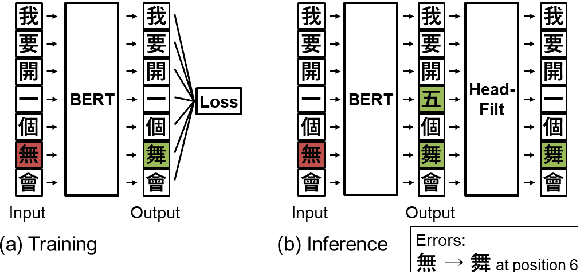
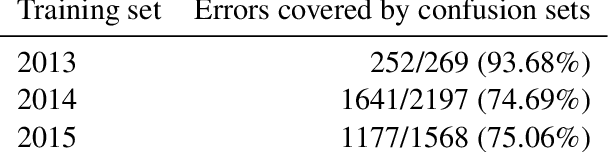
Spell check is a useful application which involves processing noisy human-generated text. Compared to other languages like English, it is more challenging to detect and correct spelling errors in Chinese because it has more (up to 100k) characters. For Chinese spell check, using confusion sets narrows the search space and makes finding corrections easier. However, most, if not all, confusion sets used to date are fixed and thus do not include new, evolving error patterns. We propose a scalable approach to adapt confusion sets by exploiting hierarchical character embeddings to (1) obviate the need to handcraft confusion sets, and (2) resolve sparsity issues related to seldom-occurring errors. Our approach establishes new SOTA results in spelling error correction on the 2014 and 2015 Chinese Spelling Correction Bake-off datasets.
From Connectomic to Task-evoked Fingerprints: Individualized Prediction of Task Contrasts from Resting-state Functional Connectivity
Aug 07, 2020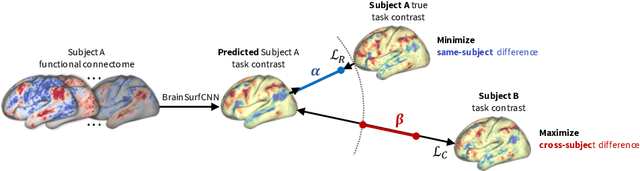
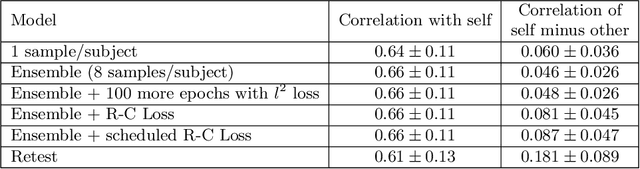
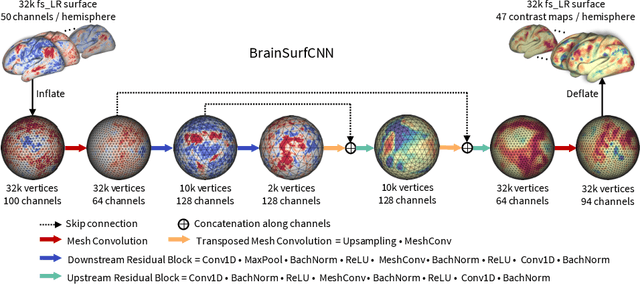
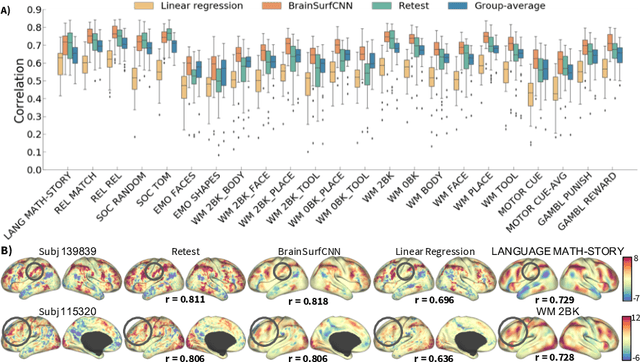
Resting-state functional MRI (rsfMRI) yields functional connectomes that can serve as cognitive fingerprints of individuals. Connectomic fingerprints have proven useful in many machine learning tasks, such as predicting subject-specific behavioral traits or task-evoked activity. In this work, we propose a surface-based convolutional neural network (BrainSurfCNN) model to predict individual task contrasts from their resting-state fingerprints. We introduce a reconstructive-contrastive loss that enforces subject-specificity of model outputs while minimizing predictive error. The proposed approach significantly improves the accuracy of predicted contrasts over a well-established baseline. Furthermore, BrainSurfCNN's prediction also surpasses test-retest benchmark in a subject identification task.
A shared neural encoding model for the prediction of subject-specific fMRI response
Jul 11, 2020
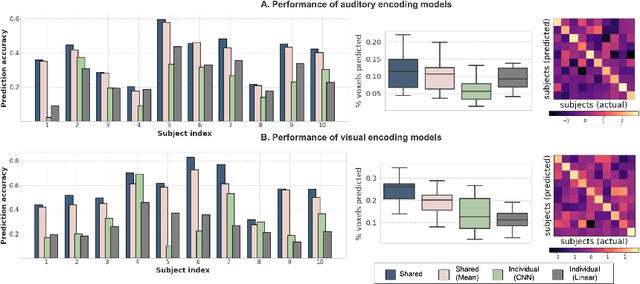
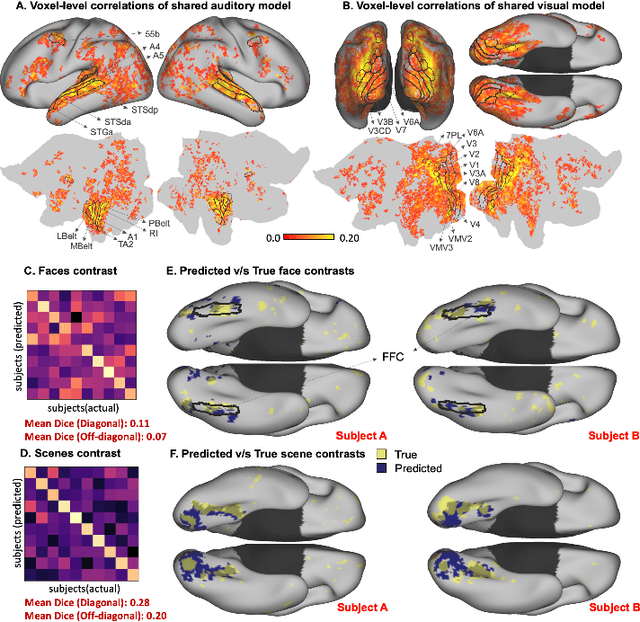
The increasing popularity of naturalistic paradigms in fMRI (such as movie watching) demands novel strategies for multi-subject data analysis, such as use of neural encoding models. In the present study, we propose a shared convolutional neural encoding method that accounts for individual-level differences. Our method leverages multi-subject data to improve the prediction of subject-specific responses evoked by visual or auditory stimuli. We showcase our approach on high-resolution 7T fMRI data from the Human Connectome Project movie-watching protocol and demonstrate significant improvement over single-subject encoding models. We further demonstrate the ability of the shared encoding model to successfully capture meaningful individual differences in response to traditional task-based facial and scenes stimuli. Taken together, our findings suggest that inter-subject knowledge transfer can be beneficial to subject-specific predictive models.
Hierarchical Character Embeddings: Learning Phonological and Semantic Representations in Languages of Logographic Origin using Recursive Neural Networks
Dec 20, 2019

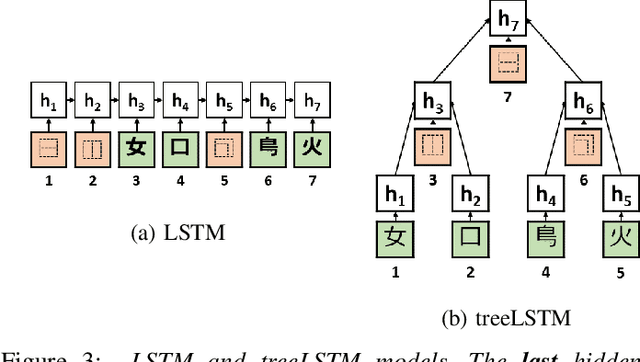
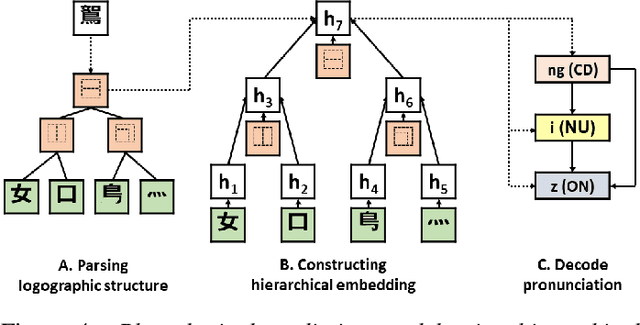
Logographs (Chinese characters) have recursive structures (i.e. hierarchies of sub-units in logographs) that contain phonological and semantic information, as developmental psychology literature suggests that native speakers leverage on the structures to learn how to read. Exploiting these structures could potentially lead to better embeddings that can benefit many downstream tasks. We propose building hierarchical logograph (character) embeddings from logograph recursive structures using treeLSTM, a recursive neural network. Using recursive neural network imposes a prior on the mapping from logographs to embeddings since the network must read in the sub-units in logographs according to the order specified by the recursive structures. Based on human behavior in language learning and reading, we hypothesize that modeling logographs' structures using recursive neural network should be beneficial. To verify this claim, we consider two tasks (1) predicting logographs' Cantonese pronunciation from logographic structures and (2) language modeling. Empirical results show that the proposed hierarchical embeddings outperform baseline approaches. Diagnostic analysis suggests that hierarchical embeddings constructed using treeLSTM is less sensitive to distractors, thus is more robust, especially on complex logographs.
Machine learning in resting-state fMRI analysis
Dec 30, 2018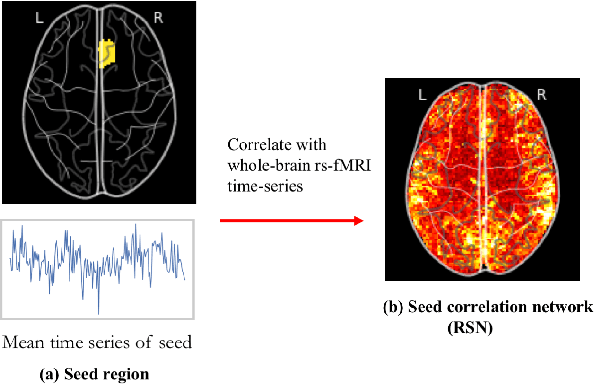
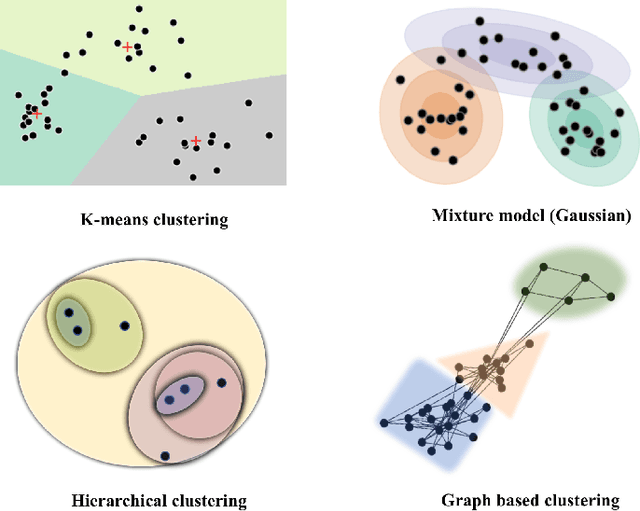
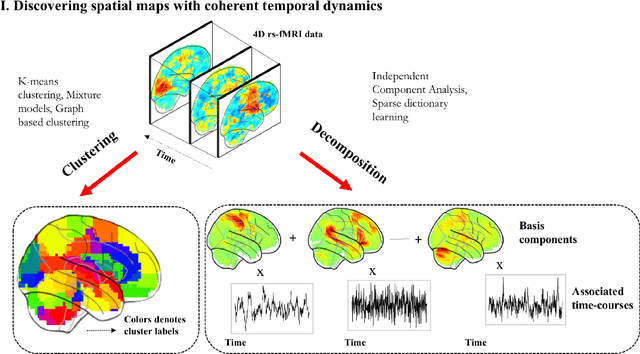
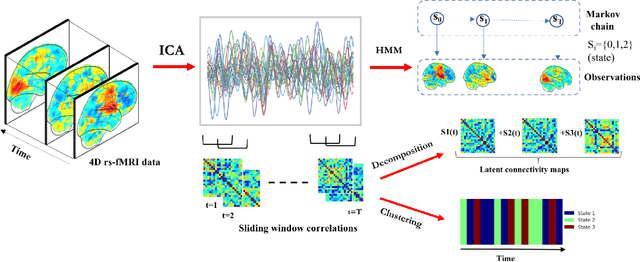
Machine learning techniques have gained prominence for the analysis of resting-state functional Magnetic Resonance Imaging (rs-fMRI) data. Here, we present an overview of various unsupervised and supervised machine learning applications to rs-fMRI. We present a methodical taxonomy of machine learning methods in resting-state fMRI. We identify three major divisions of unsupervised learning methods with regard to their applications to rs-fMRI, based on whether they discover principal modes of variation across space, time or population. Next, we survey the algorithms and rs-fMRI feature representations that have driven the success of supervised subject-level predictions. The goal is to provide a high-level overview of the burgeoning field of rs-fMRI from the perspective of machine learning applications.