 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable Filtering using Hierarchical Embeddings for Chinese Spell Check
Paper and Code
Aug 27, 2020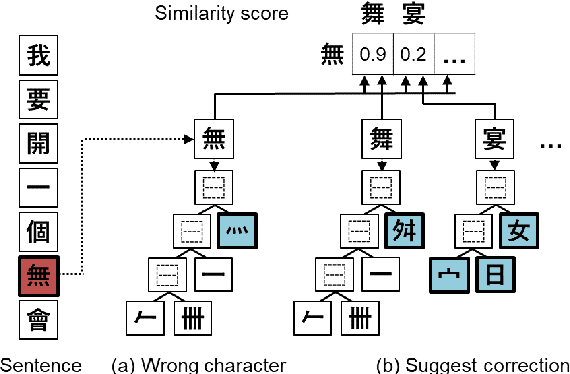
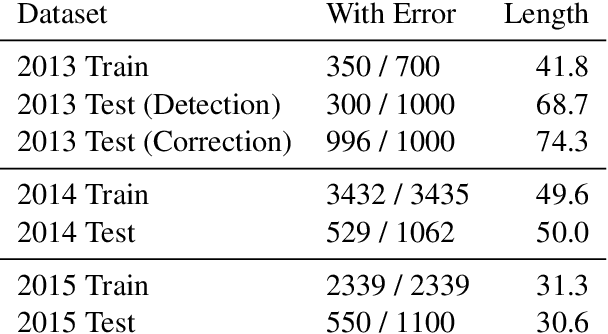
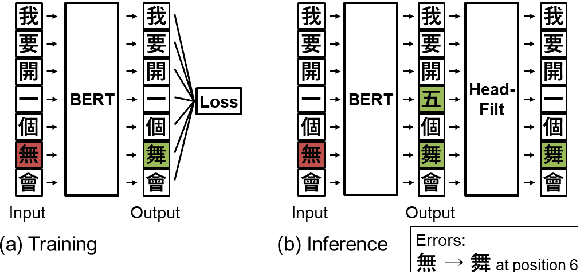
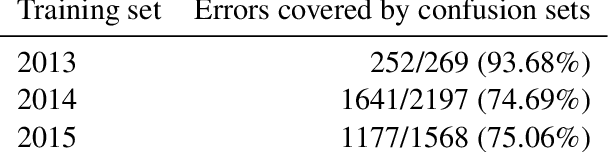
Spell check is a useful application which involves processing noisy human-generated text. Compared to other languages like English, it is more challenging to detect and correct spelling errors in Chinese because it has more (up to 100k) characters. For Chinese spell check, using confusion sets narrows the search space and makes finding corrections easier. However, most, if not all, confusion sets used to date are fixed and thus do not include new, evolving error patterns. We propose a scalable approach to adapt confusion sets by exploiting hierarchical character embeddings to (1) obviate the need to handcraft confusion sets, and (2) resolve sparsity issues related to seldom-occurring errors. Our approach establishes new SOTA results in spelling error correction on the 2014 and 2015 Chinese Spelling Correction Bake-off datasets.