 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Detailed Human Context In-the-Wild from Smartphones and Smartwatches
Sep 30, 2017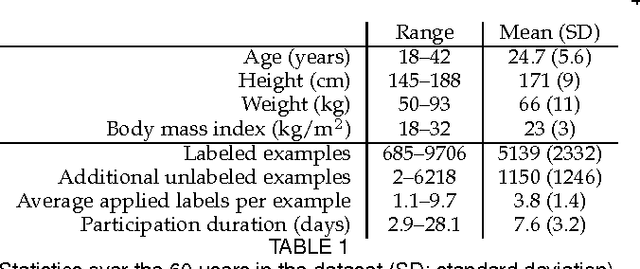
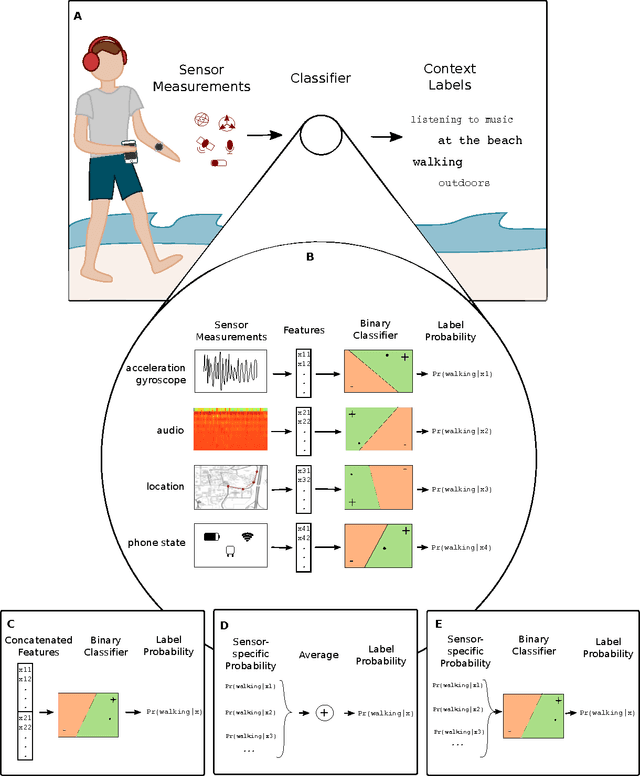
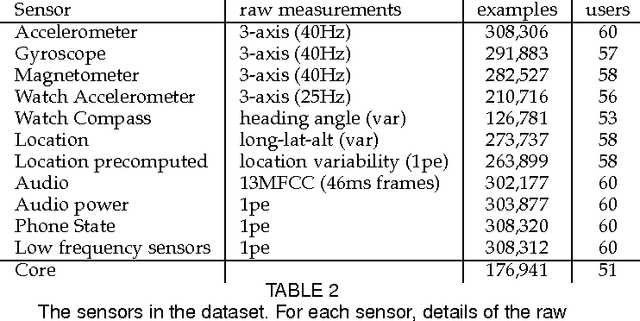
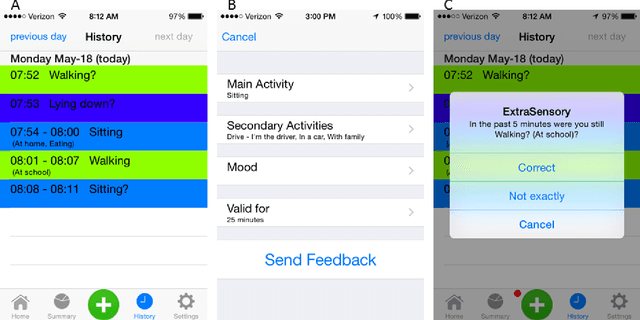
The ability to automatically recognize a person's behavioral context can contribute to health monitoring, aging care and many other domains. Validating context recognition in-the-wild is crucial to promote practical applications that work in real-life settings. We collected over 300k minutes of sensor data with context labels from 60 subjects. Unlike previous studies, our subjects used their own personal phone, in any way that was convenient to them, and engaged in their routine in their natural environments. Unscripted behavior and unconstrained phone usage resulted in situations that are harder to recognize. We demonstrate how fusion of multi-modal sensors is important for resolving such cases. We present a baseline system, and encourage researchers to use our public dataset to compare methods and improve context recognition in-the-wild.
* This paper was accepted and is to appear in IEEE Pervasive Computing, vol. 16, no. 4, October-December 2017, pp. 62-74
Codebook based Audio Feature Representation for Music Information Retrieval
Dec 19, 2013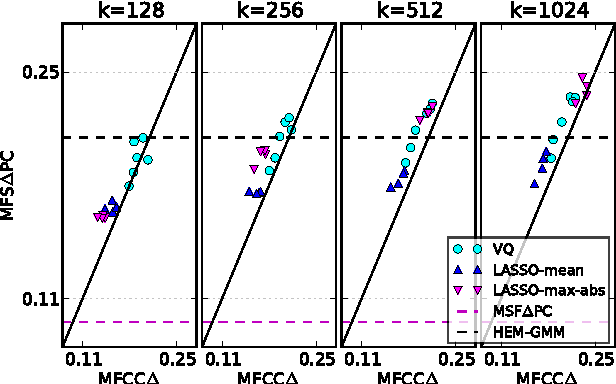
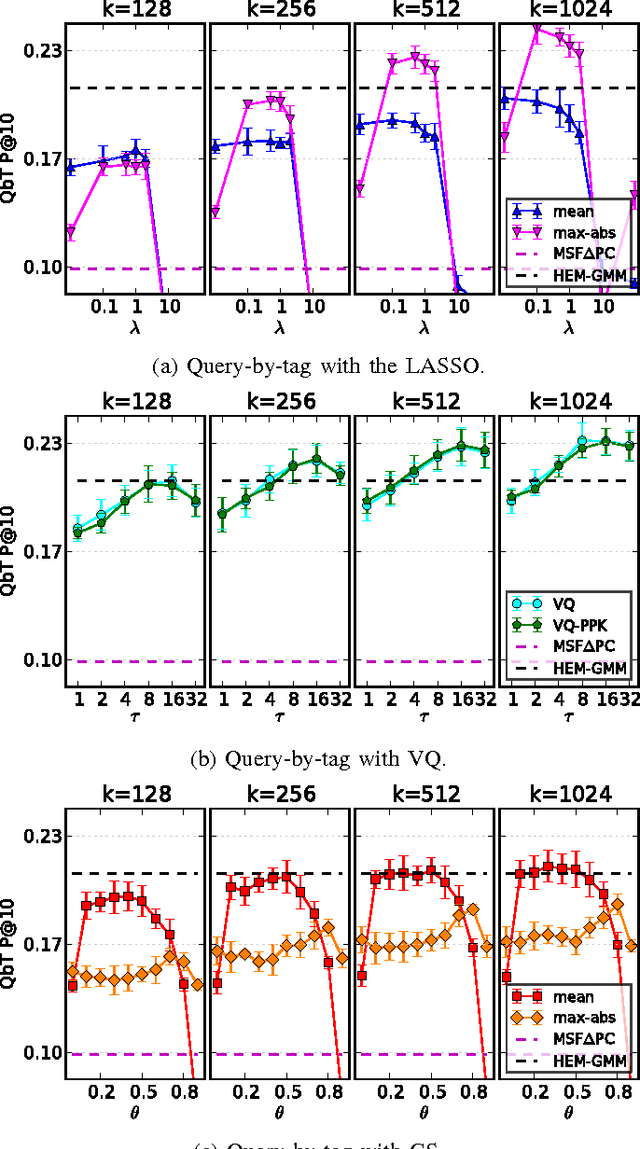
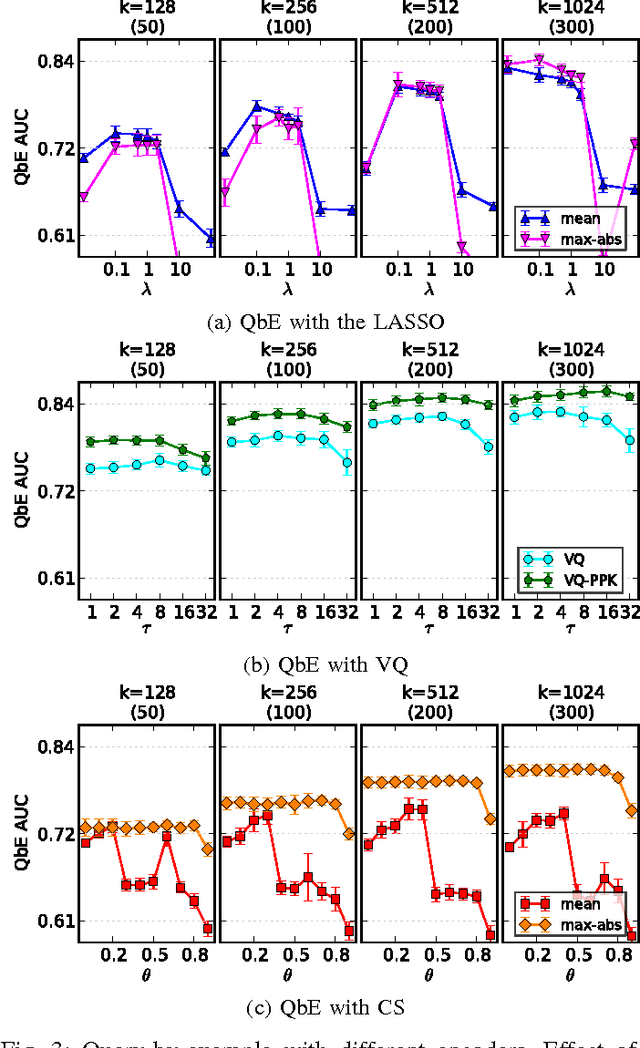
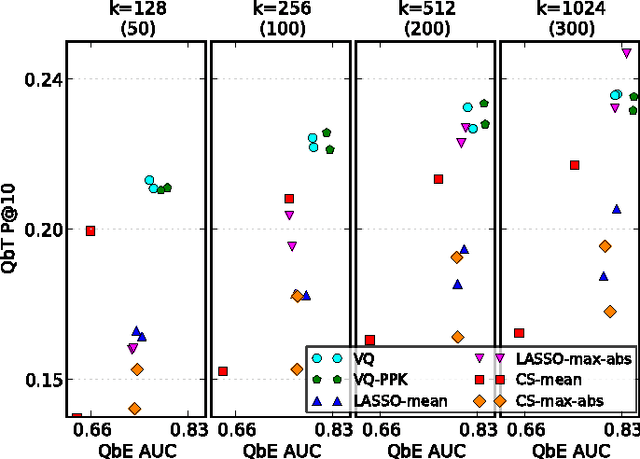
Digital music has become prolific in the web in recent decades. Automated recommendation systems are essential for users to discover music they love and for artists to reach appropriate audience. When manual annotations and user preference data is lacking (e.g. for new artists) these systems must rely on \emph{content based} methods. Besides powerful machine learning tools for classification and retrieval, a key component for successful recommendation is the \emph{audio content representation}. Good representations should capture informative musical patterns in the audio signal of songs. These representations should be concise, to enable efficient (low storage, easy indexing, fast search) management of huge music repositories, and should also be easy and fast to compute, to enable real-time interaction with a user supplying new songs to the system. Before designing new audio features, we explore the usage of traditional local features, while adding a stage of encoding with a pre-computed \emph{codebook} and a stage of pooling to get compact vectorial representations. We experiment with different encoding methods, namely \emph{the LASSO}, \emph{vector quantization (VQ)} and \emph{cosine similarity (CS)}. We evaluate the representations' quality in two music information retrieval applications: query-by-tag and query-by-example. Our results show that concise representations can be used for successful performance in both applications. We recommend using top-$\tau$ VQ encoding, which consistently performs well in both applications, and requires much less computation time than the LASSO.
Learning Multi-modal Similarity
Aug 30, 2010

In many applications involving multi-media data, the definition of similarity between items is integral to several key tasks, e.g., nearest-neighbor retrieval, classification, and recommendation. Data in such regimes typically exhibits multiple modalities, such as acoustic and visual content of video. Integrating such heterogeneous data to form a holistic similarity space is therefore a key challenge to be overcome in many real-world applications. We present a novel multiple kernel learning technique for integrating heterogeneous data into a single, unified similarity space. Our algorithm learns an optimal ensemble of kernel transfor- mations which conform to measurements of human perceptual similarity, as expressed by relative comparisons. To cope with the ubiquitous problems of subjectivity and inconsistency in multi- media similarity, we develop graph-based techniques to filter similarity measurements, resulting in a simplified and robust training procedure.
A D.C. Programming Approach to the Sparse Generalized Eigenvalue Problem
Oct 13, 2009
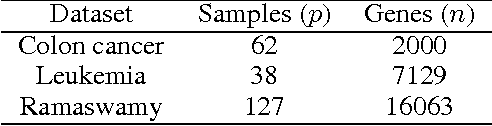
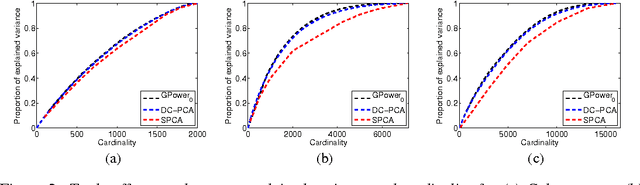
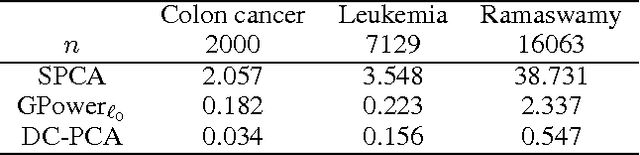
In this paper, we consider the sparse eigenvalue problem wherein the goal is to obtain a sparse solution to the generalized eigenvalue problem. We achieve this by constraining the cardinality of the solution to the generalized eigenvalue problem and obtain sparse principal component analysis (PCA), sparse canonical correlation analysis (CCA) and sparse Fisher discriminant analysis (FDA) as special cases. Unlike the $\ell_1$-norm approximation to the cardinality constraint, which previous methods have used in the context of sparse PCA, we propose a tighter approximation that is related to the negative log-likelihood of a Student's t-distribution. The problem is then framed as a d.c. (difference of convex functions) program and is solved as a sequence of convex programs by invoking the majorization-minimization method. The resulting algorithm is proved to exhibit \emph{global convergence} behavior, i.e., for any random initialization, the sequence (subsequence) of iterates generated by the algorithm converges to a stationary point of the d.c. program. The performance of the algorithm is empirically demonstrated on both sparse PCA (finding few relevant genes that explain as much variance as possible in a high-dimensional gene dataset) and sparse CCA (cross-language document retrieval and vocabulary selection for music retrieval) applications.