 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodebook based Audio Feature Representation for Music Information Retrieval
Paper and Code
Dec 19, 2013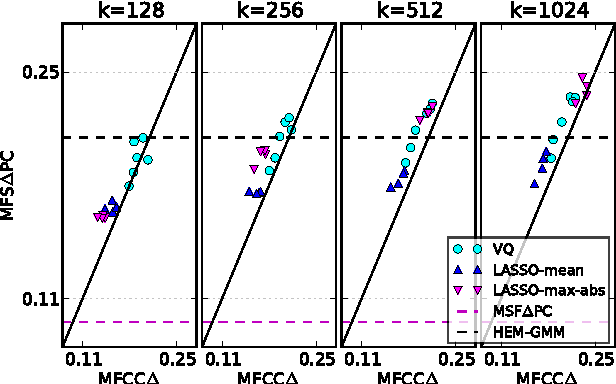
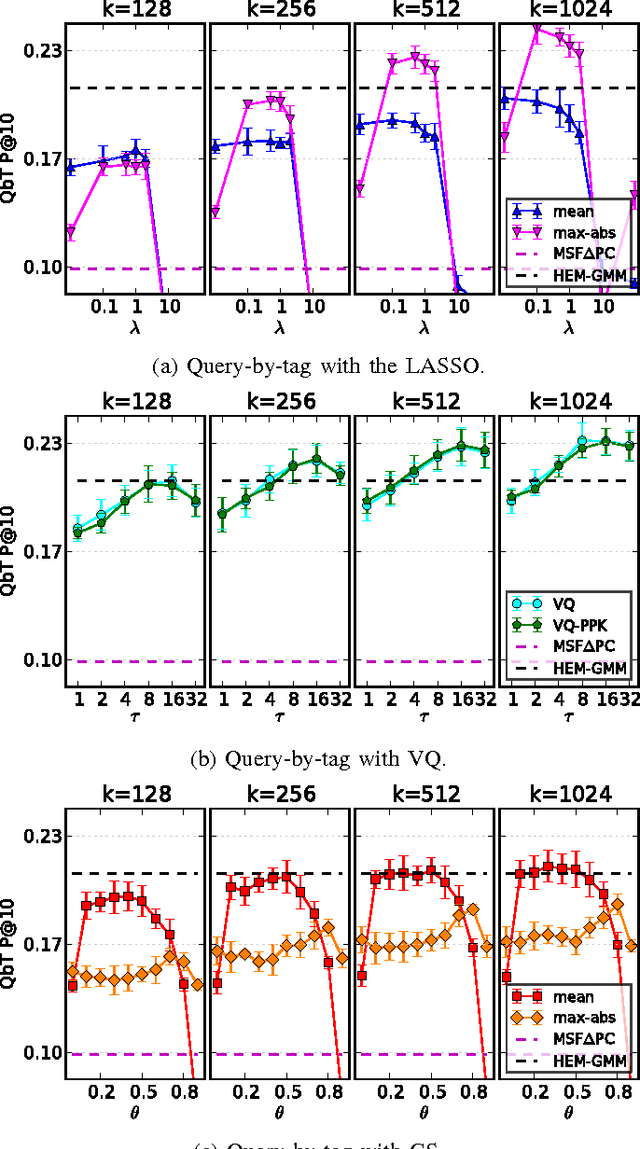
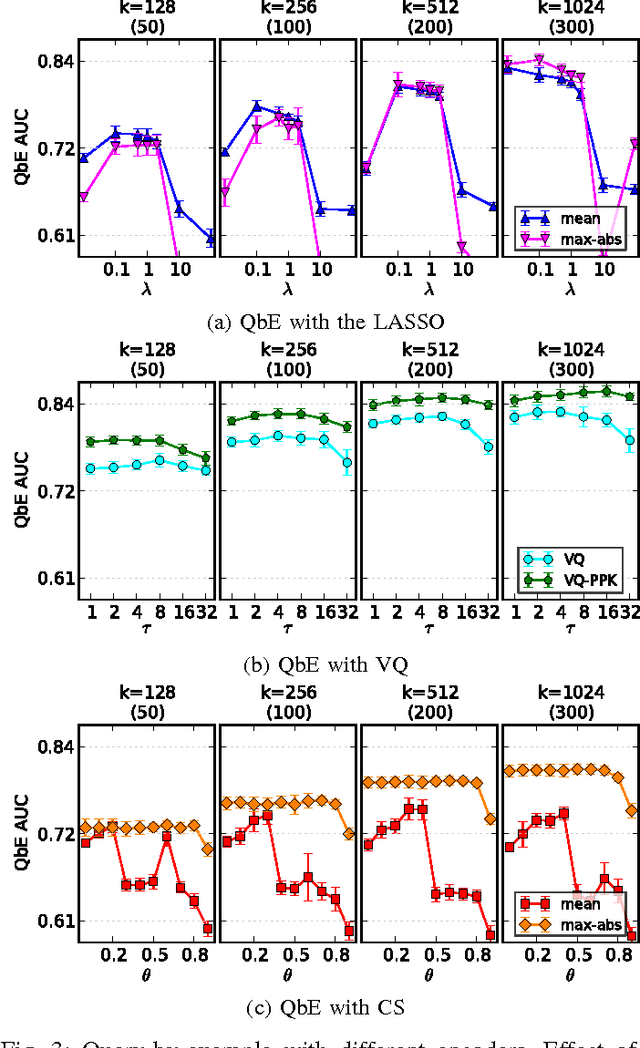
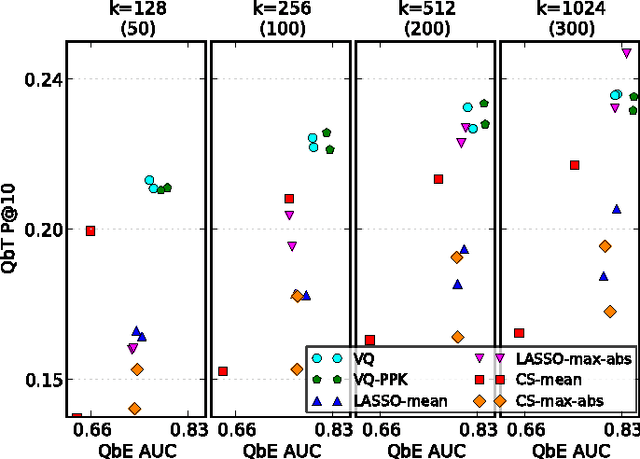
Digital music has become prolific in the web in recent decades. Automated recommendation systems are essential for users to discover music they love and for artists to reach appropriate audience. When manual annotations and user preference data is lacking (e.g. for new artists) these systems must rely on \emph{content based} methods. Besides powerful machine learning tools for classification and retrieval, a key component for successful recommendation is the \emph{audio content representation}. Good representations should capture informative musical patterns in the audio signal of songs. These representations should be concise, to enable efficient (low storage, easy indexing, fast search) management of huge music repositories, and should also be easy and fast to compute, to enable real-time interaction with a user supplying new songs to the system. Before designing new audio features, we explore the usage of traditional local features, while adding a stage of encoding with a pre-computed \emph{codebook} and a stage of pooling to get compact vectorial representations. We experiment with different encoding methods, namely \emph{the LASSO}, \emph{vector quantization (VQ)} and \emph{cosine similarity (CS)}. We evaluate the representations' quality in two music information retrieval applications: query-by-tag and query-by-example. Our results show that concise representations can be used for successful performance in both applications. We recommend using top-$\tau$ VQ encoding, which consistently performs well in both applications, and requires much less computation time than the LASSO.