 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-modal Similarity
Paper and Code
Aug 30, 2010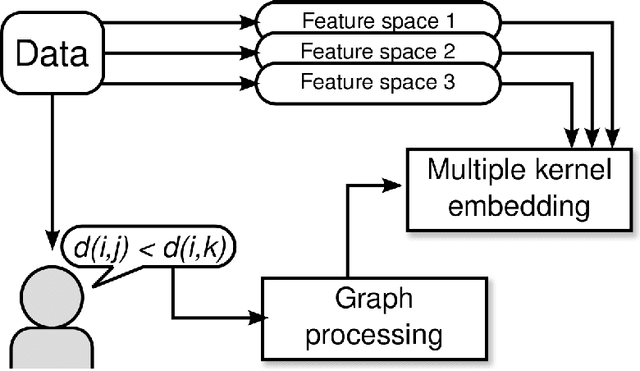
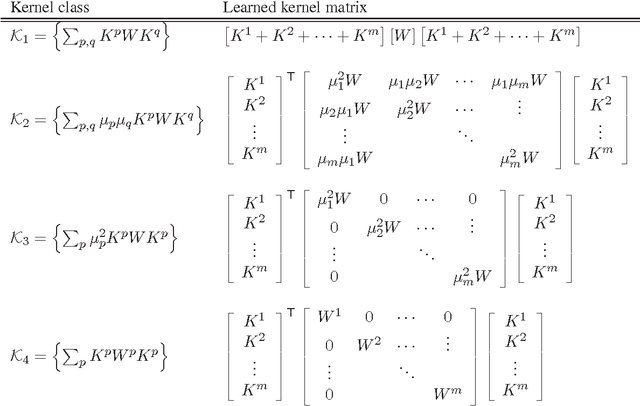
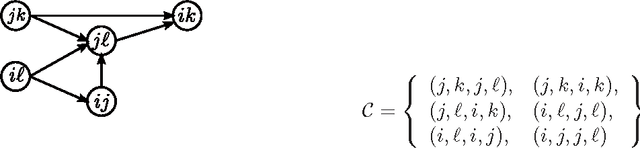

In many applications involving multi-media data, the definition of similarity between items is integral to several key tasks, e.g., nearest-neighbor retrieval, classification, and recommendation. Data in such regimes typically exhibits multiple modalities, such as acoustic and visual content of video. Integrating such heterogeneous data to form a holistic similarity space is therefore a key challenge to be overcome in many real-world applications. We present a novel multiple kernel learning technique for integrating heterogeneous data into a single, unified similarity space. Our algorithm learns an optimal ensemble of kernel transfor- mations which conform to measurements of human perceptual similarity, as expressed by relative comparisons. To cope with the ubiquitous problems of subjectivity and inconsistency in multi- media similarity, we develop graph-based techniques to filter similarity measurements, resulting in a simplified and robust training procedure.