 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTighter expected generalization error bounds via Wasserstein distance
Jan 22, 2021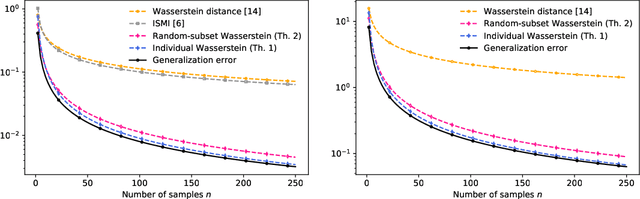
In this work, we introduce several expected generalization error bounds based on the Wasserstein distance. More precisely, we present full-dataset, single-letter, and random-subset bounds on both the standard setting and the randomized-subsample setting from Steinke and Zakynthinou [2020]. Moreover, we show that, when the loss function is bounded, these bounds recover from below (and thus are tighter than) current bounds based on the relative entropy and, for the standard setting, generate new, non-vacuous bounds also based on the relative entropy. Then, we show how similar bounds featuring the backward channel can be derived with the proposed proof techniques. Finally, we show how various new bounds based on different information measures (e.g., the lautum information or several $f$-divergences) can be derived from the presented bounds.
On Random Subset Generalization Error Bounds and the Stochastic Gradient Langevin Dynamics Algorithm
Oct 21, 2020In this work, we unify several expected generalization error bounds based on random subsets using the framework developed by Hellstr\"om and Durisi [1]. First, we recover the bounds based on the individual sample mutual information from Bu et al. [2] and on a random subset of the dataset from Negrea et al. [3]. Then, we introduce their new, analogous bounds in the randomized subsample setting from Steinke and Zakynthinou [4], and we identify some limitations of the framework. Finally, we extend the bounds from Haghifam et al. [5] for Langevin dynamics to stochastic gradient Langevin dynamics and we refine them for loss functions with potentially large gradient norms.
On Neural Estimators for Conditional Mutual Information Using Nearest Neighbors Sampling
Jun 12, 2020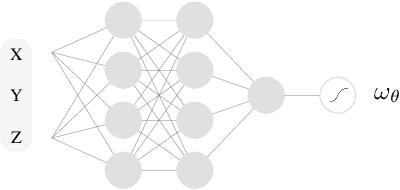
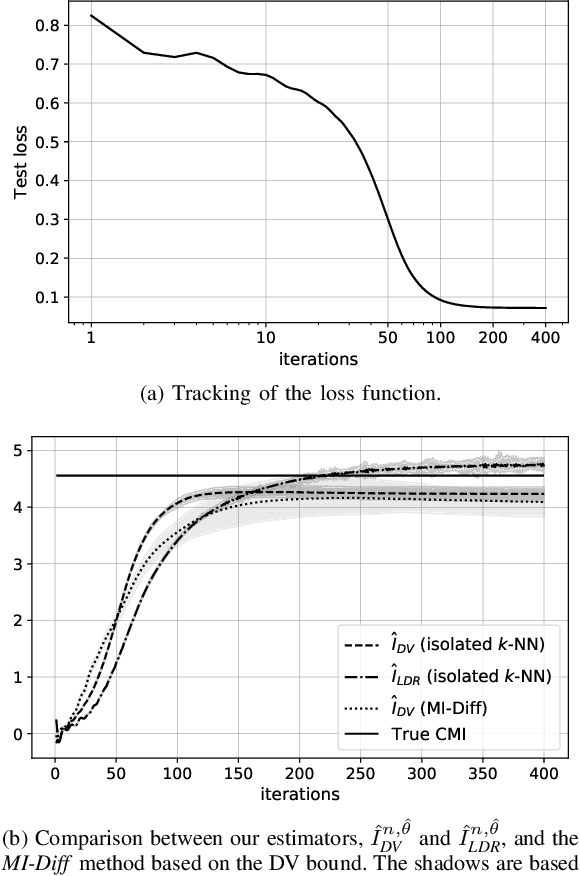
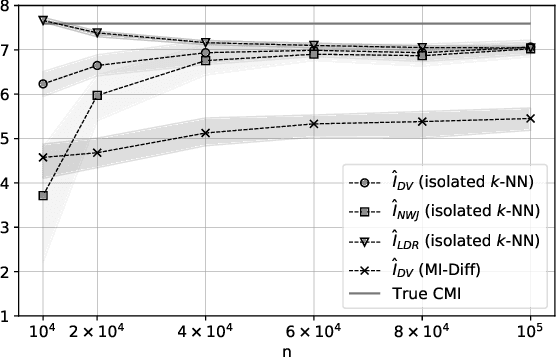
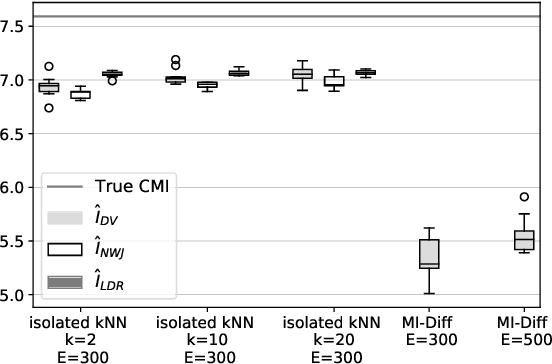
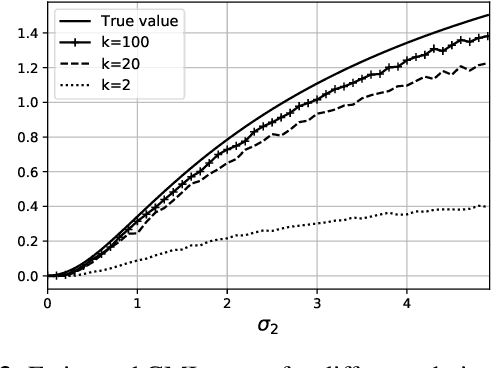
The estimation of mutual information (MI) or conditional mutual information (CMI) from a set of samples is a long-standing problem. A recent line of work in this area has leveraged the approximation power of artificial neural networks and has shown improvements over conventional methods. One important challenge in this new approach is the need to obtain, given the original dataset, a different set where the samples are distributed according to a specific product density function. This is particularly challenging when estimating CMI. In this paper, we introduce a new technique, based on k nearest neighbors (k-NN), to perform the resampling and derive high-confidence concentration bounds for the sample average. Then the technique is employed to train a neural network classifier and the CMI is estimated accordingly. We propose three estimators using this technique and prove their consistency, make a comparison between them and similar approaches in the literature, and experimentally show improvements in estimating the CMI in terms of accuracy and variance of the estimators.
Upper Bounds on the Generalization Error of Private Algorithms
May 12, 2020
In this work, we study the generalization capability of algorithms from an information-theoretic perspective. It has been shown that the generalization error of an algorithm is bounded from above in terms of the mutual information between the algorithm's output hypothesis and the dataset with which it was trained. We build upon this fact and introduce a mathematical formulation to obtain upper bounds on this mutual information. We then develop a strategy using this formulation, based on the method of types and typicality, to find explicit upper bounds on the generalization error of smooth algorithms, i.e., algorithms that produce similar output hypotheses given similar input datasets. In particular, we show the bounds obtained with this strategy for the case of $\epsilon$-DP and $\mu$-GDP algorithms.
Conditional Mutual Information Neural Estimator
Nov 06, 2019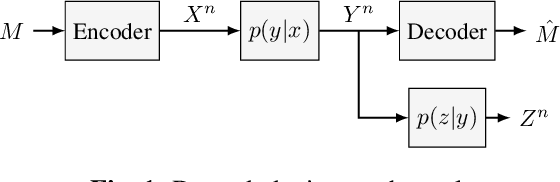

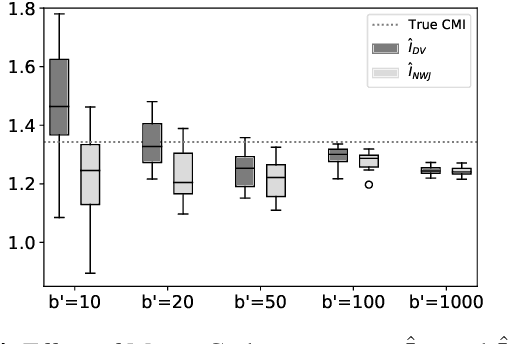
Several recent works in communication systems have proposed to leverage the power of neural networks in the design of encoders and decoders. In this approach, these blocks can be tailored to maximize the transmission rate based on aggregated samples from the channel. Motivated by the fact that, in many communication schemes, the achievable transmission rate is determined by a conditional mutual information, this paper focuses on neural-based estimators for this information-theoretic quantity. Our results are based on variational bounds for the KL-divergence and, in contrast to some previous works, we provide a mathematically rigorous lower bound. However, additional challenges with respect to the unconditional mutual information emerge due to the presence of a conditional density function; this is also addressed here.