 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
Nov 30, 2023As pretrained text-to-image diffusion models become increasingly powerful, recent efforts have been made to distill knowledge from these text-to-image pretrained models for optimizing a text-guided 3D model. Most of the existing methods generate a holistic 3D model from a plain text input. This can be problematic when the text describes a complex scene with multiple objects, because the vectorized text embeddings are inherently unable to capture a complex description with multiple entities and relationships. Holistic 3D modeling of the entire scene further prevents accurate grounding of text entities and concepts. To address this limitation, we propose GraphDreamer, a novel framework to generate compositional 3D scenes from scene graphs, where objects are represented as nodes and their interactions as edges. By exploiting node and edge information in scene graphs, our method makes better use of the pretrained text-to-image diffusion model and is able to fully disentangle different objects without image-level supervision. To facilitate modeling of object-wise relationships, we use signed distance fields as representation and impose a constraint to avoid inter-penetration of objects. To avoid manual scene graph creation, we design a text prompt for ChatGPT to generate scene graphs based on text inputs. We conduct both qualitative and quantitative experiments to validate the effectiveness of GraphDreamer in generating high-fidelity compositional 3D scenes with disentangled object entities.
Learning Causal Representation for Face Transfer across Large Appearance Gap
Oct 17, 2021
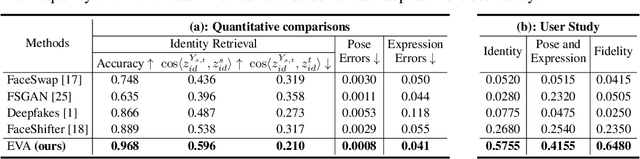
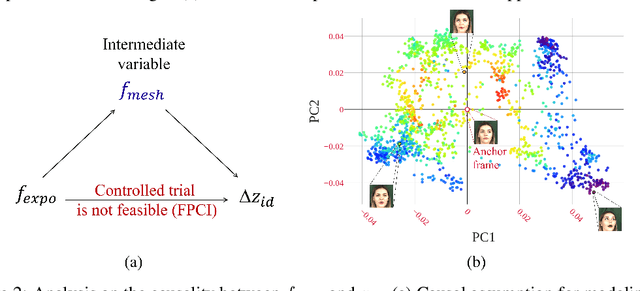
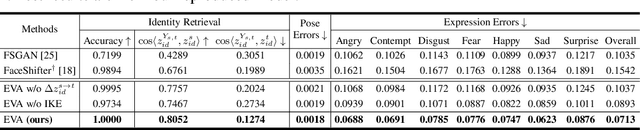
Identity transfer often faces the challenge of generalizing to new situations where large pose and expression or background gaps exist between source and target face images. To improve generalization in such situations, biases take a key role~\cite{mitchell_1980_bias}. This paper proposes an Errors-in-Variables Adapter (EVA) model to induce learning of proper generalizations by explicitly employing biases to identity estimation based on prior knowledge about the target situation. To better match the source face with the target situation in terms of pose, expression, and background factors, we model the bias as a causal effect of the target situation on source identity and estimate this effect through a controlled intervention trial. To achieve smoother transfer for the target face across the identity gap, we eliminate the target face specificity through multiple kernel regressions. The kernels are used to constrain the regressions to operate only on identity information in the internal representations of the target image, while leaving other perceptual information invariant. Combining these post-regression representations with the biased estimation for identity, EVA shows impressive performance even in the presence of large gaps, providing empirical evidence supporting the utility of the inductive biases in identity estimation.