 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Unlearn while Retaining: Combating Gradient Conflicts in Machine Unlearning
Mar 08, 2025Machine Unlearning has recently garnered significant attention, aiming to selectively remove knowledge associated with specific data while preserving the model's performance on the remaining data. A fundamental challenge in this process is balancing effective unlearning with knowledge retention, as naive optimization of these competing objectives can lead to conflicting gradients, hindering convergence and degrading overall performance. To address this issue, we propose Learning to Unlearn while Retaining, aimed to mitigate gradient conflicts between unlearning and retention objectives. Our approach strategically avoids conflicts through an implicit gradient regularization mechanism that emerges naturally within the proposed framework. This prevents conflicting gradients between unlearning and retention, leading to effective unlearning while preserving the model's utility. We validate our approach across both discriminative and generative tasks, demonstrating its effectiveness in achieving unlearning without compromising performance on remaining data. Our results highlight the advantages of avoiding such gradient conflicts, outperforming existing methods that fail to account for these interactions.
Efficient Source-Free Time-Series Adaptation via Parameter Subspace Disentanglement
Oct 03, 2024In this paper, we propose a framework for efficient Source-Free Domain Adaptation (SFDA) in the context of time-series, focusing on enhancing both parameter efficiency and data-sample utilization. Our approach introduces an improved paradigm for source-model preparation and target-side adaptation, aiming to enhance training efficiency during target adaptation. Specifically, we reparameterize the source model's weights in a Tucker-style decomposed manner, factorizing the model into a compact form during the source model preparation phase. During target-side adaptation, only a subset of these decomposed factors is fine-tuned, leading to significant improvements in training efficiency. We demonstrate using PAC Bayesian analysis that this selective fine-tuning strategy implicitly regularizes the adaptation process by constraining the model's learning capacity. Furthermore, this re-parameterization reduces the overall model size and enhances inference efficiency, making the approach particularly well suited for resource-constrained devices. Additionally, we demonstrate that our framework is compatible with various SFDA methods and achieves significant computational efficiency, reducing the number of fine-tuned parameters and inference overhead in terms of MACs by over 90% while maintaining model performance.
Learning to Retain while Acquiring: Combating Distribution-Shift in Adversarial Data-Free Knowledge Distillation
Feb 28, 2023Data-free Knowledge Distillation (DFKD) has gained popularity recently, with the fundamental idea of carrying out knowledge transfer from a Teacher neural network to a Student neural network in the absence of training data. However, in the Adversarial DFKD framework, the student network's accuracy, suffers due to the non-stationary distribution of the pseudo-samples under multiple generator updates. To this end, at every generator update, we aim to maintain the student's performance on previously encountered examples while acquiring knowledge from samples of the current distribution. Thus, we propose a meta-learning inspired framework by treating the task of Knowledge-Acquisition (learning from newly generated samples) and Knowledge-Retention (retaining knowledge on previously met samples) as meta-train and meta-test, respectively. Hence, we dub our method as Learning to Retain while Acquiring. Moreover, we identify an implicit aligning factor between the Knowledge-Retention and Knowledge-Acquisition tasks indicating that the proposed student update strategy enforces a common gradient direction for both tasks, alleviating interference between the two objectives. Finally, we support our hypothesis by exhibiting extensive evaluation and comparison of our method with prior arts on multiple datasets.
Weakly supervised segmentation with cross-modality equivariant constraints
Apr 06, 2021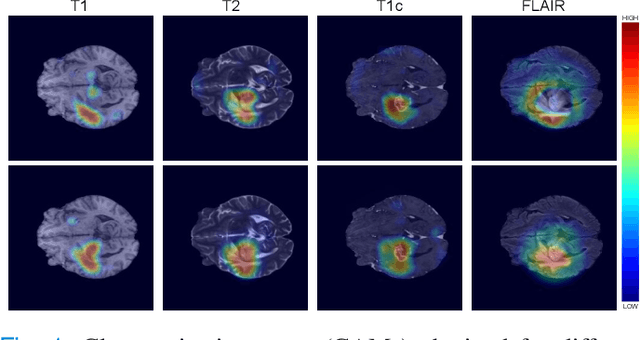
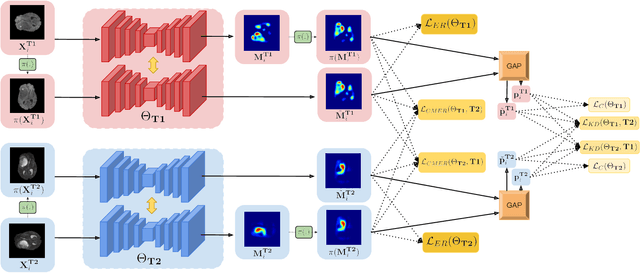
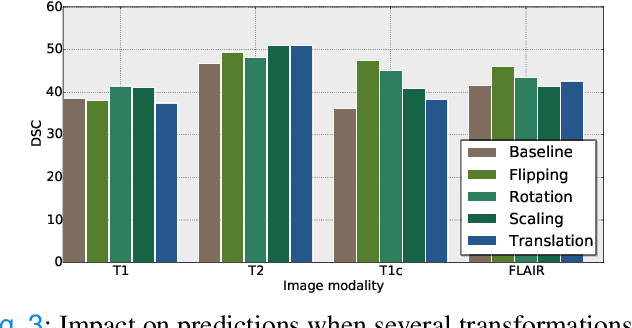
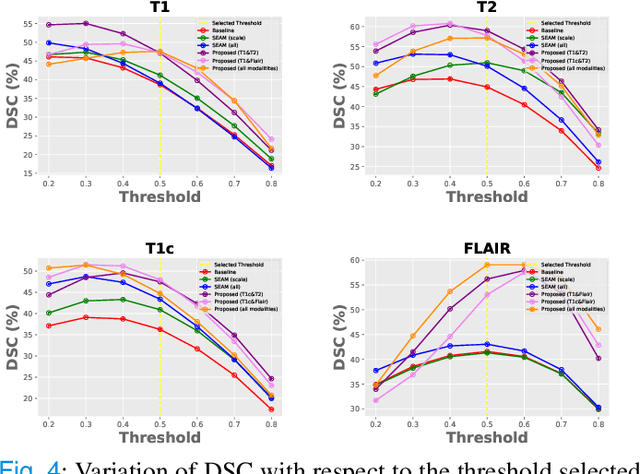
Weakly supervised learning has emerged as an appealing alternative to alleviate the need for large labeled datasets in semantic segmentation. Most current approaches exploit class activation maps (CAMs), which can be generated from image-level annotations. Nevertheless, resulting maps have been demonstrated to be highly discriminant, failing to serve as optimal proxy pixel-level labels. We present a novel learning strategy that leverages self-supervision in a multi-modal image scenario to significantly enhance original CAMs. In particular, the proposed method is based on two observations. First, the learning of fully-supervised segmentation networks implicitly imposes equivariance by means of data augmentation, whereas this implicit constraint disappears on CAMs generated with image tags. And second, the commonalities between image modalities can be employed as an efficient self-supervisory signal, correcting the inconsistency shown by CAMs obtained across multiple modalities. To effectively train our model, we integrate a novel loss function that includes a within-modality and a cross-modality equivariant term to explicitly impose these constraints during training. In addition, we add a KL-divergence on the class prediction distributions to facilitate the information exchange between modalities, which, combined with the equivariant regularizers further improves the performance of our model. Exhaustive experiments on the popular multi-modal BRATS dataset demonstrate that our approach outperforms relevant recent literature under the same learning conditions.
Switching Loss for Generalized Nucleus Detection in Histopathology
Aug 09, 2020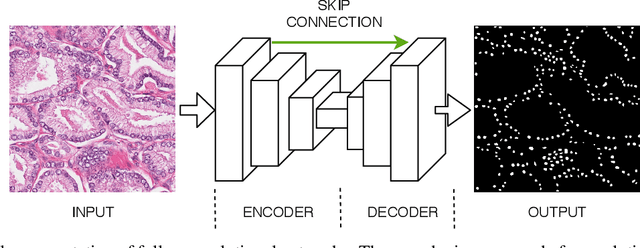

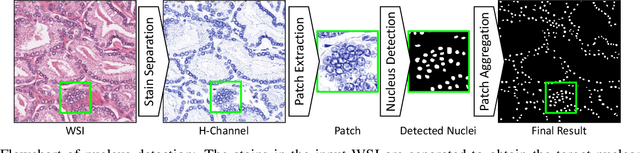
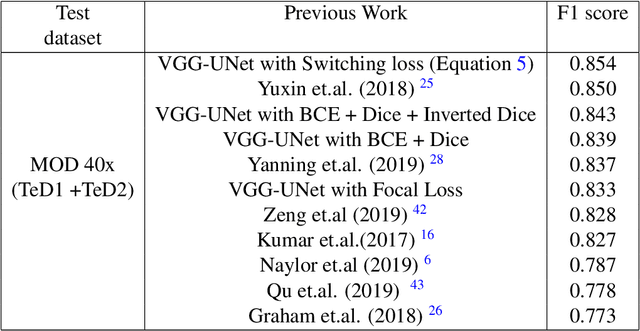
The accuracy of deep learning methods for two foundational tasks in medical image analysis -- detection and segmentation -- can suffer from class imbalance. We propose a `switching loss' function that adaptively shifts the emphasis between foreground and background classes. While the existing loss functions to address this problem were motivated by the classification task, the switching loss is based on Dice loss, which is better suited for segmentation and detection. Furthermore, to get the most out the training samples, we adapt the loss with each mini-batch, unlike previous proposals that adapt once for the entire training set. A nucleus detector trained using the proposed loss function on a source dataset outperformed those trained using cross-entropy, Dice, or focal losses. Remarkably, without retraining on target datasets, our pre-trained nucleus detector also outperformed existing nucleus detectors that were trained on at least some of the images from the target datasets. To establish a broad utility of the proposed loss, we also confirmed that it led to more accurate ventricle segmentation in MRI as compared to the other loss functions. Our GPU-enabled pre-trained nucleus detection software is also ready to process whole slide images right out-of-the-box and is usably fast.