 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNToP: NeRF-Powered Large-scale Dataset Generation for 2D and 3D Human Pose Estimation in Top-View Fisheye Images
Feb 28, 2024

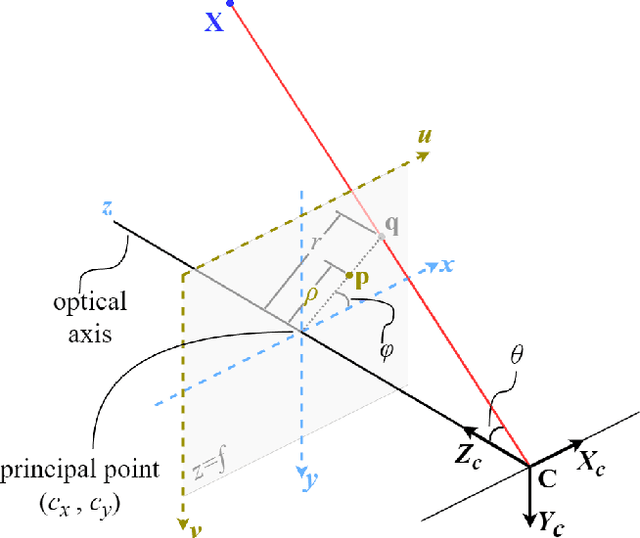
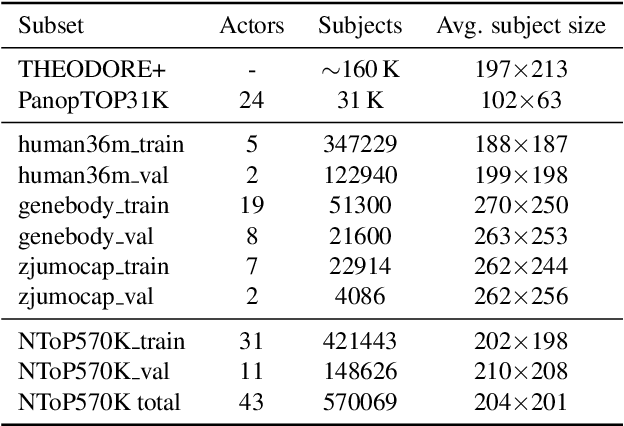
Human pose estimation (HPE) in the top-view using fisheye cameras presents a promising and innovative application domain. However, the availability of datasets capturing this viewpoint is extremely limited, especially those with high-quality 2D and 3D keypoint annotations. Addressing this gap, we leverage the capabilities of Neural Radiance Fields (NeRF) technique to establish a comprehensive pipeline for generating human pose datasets from existing 2D and 3D datasets, specifically tailored for the top-view fisheye perspective. Through this pipeline, we create a novel dataset NToP570K (NeRF-powered Top-view human Pose dataset for fisheye cameras with over 570 thousand images), and conduct an extensive evaluation of its efficacy in enhancing neural networks for 2D and 3D top-view human pose estimation. A pretrained ViTPose-B model achieves an improvement in AP of 33.3 % on our validation set for 2D HPE after finetuning on our training set. A similarly finetuned HybrIK-Transformer model gains 53.7 mm reduction in PA-MPJPE for 3D HPE on the validation set.
Human Pose Estimation in Monocular Omnidirectional Top-View Images
Apr 17, 2023Human pose estimation (HPE) with convolutional neural networks (CNNs) for indoor monitoring is one of the major challenges in computer vision. In contrast to HPE in perspective views, an indoor monitoring system can consist of an omnidirectional camera with a field of view of 180{\deg} to detect the pose of a person with only one sensor per room. To recognize human pose, the detection of keypoints is an essential upstream step. In our work we propose a new dataset for training and evaluation of CNNs for the task of keypoint detection in omnidirectional images. The training dataset, THEODORE+, consists of 50,000 images and is created by a 3D rendering engine, where humans are randomly walking through an indoor environment. In a dynamically created 3D scene, persons move randomly with simultaneously moving omnidirectional camera to generate synthetic RGB images and 2D and 3D ground truth. For evaluation purposes, the real-world PoseFES dataset with two scenarios and 701 frames with up to eight persons per scene was captured and annotated. We propose four training paradigms to finetune or re-train two top-down models in MMPose and two bottom-up models in CenterNet on THEODORE+. Beside a qualitative evaluation we report quantitative results. Compared to a COCO pretrained baseline, we achieve significant improvements especially for top-view scenes on the PoseFES dataset. Our datasets can be found at https://www.tu-chemnitz.de/etit/dst/forschung/comp_vision/datasets/index.php.en.
Applications of Deep Learning for Top-View Omnidirectional Imaging: A Survey
Apr 17, 2023
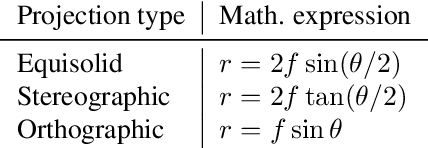
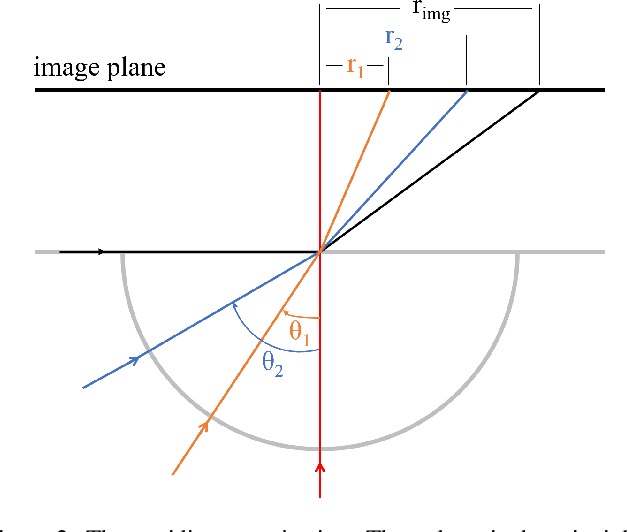
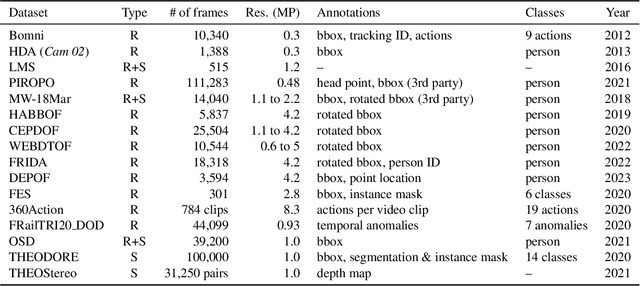
A large field-of-view fisheye camera allows for capturing a large area with minimal numbers of cameras when they are mounted on a high position facing downwards. This top-view omnidirectional setup greatly reduces the work and cost for deployment compared to traditional solutions with multiple perspective cameras. In recent years, deep learning has been widely employed for vision related tasks, including for such omnidirectional settings. In this survey, we look at the application of deep learning in combination with omnidirectional top-view cameras, including the available datasets, human and object detection, human pose estimation, activity recognition and other miscellaneous applications.
OmniPD: One-Step Person Detection in Top-View Omnidirectional Indoor Scenes
Apr 14, 2022
We propose a one-step person detector for topview omnidirectional indoor scenes based on convolutional neural networks (CNNs). While state of the art person detectors reach competitive results on perspective images, missing CNN architectures as well as training data that follows the distortion of omnidirectional images makes current approaches not applicable to our data. The method predicts bounding boxes of multiple persons directly in omnidirectional images without perspective transformation, which reduces overhead of pre- and post-processing and enables real-time performance. The basic idea is to utilize transfer learning to fine-tune CNNs trained on perspective images with data augmentation techniques for detection in omnidirectional images. We fine-tune two variants of Single Shot MultiBox detectors (SSDs). The first one uses Mobilenet v1 FPN as feature extractor (moSSD). The second one uses ResNet50 v1 FPN (resSSD). Both models are pre-trained on Microsoft Common Objects in Context (COCO) dataset. We fine-tune both models on PASCAL VOC07 and VOC12 datasets, specifically on class person. Random 90-degree rotation and random vertical flipping are used for data augmentation in addition to the methods proposed by original SSD. We reach an average precision (AP) of 67.3 % with moSSD and 74.9 % with resSSD onthe evaluation dataset. To enhance the fine-tuning process, we add a subset of HDA Person dataset and a subset of PIROPOdatabase and reduce the number of perspective images to PASCAL VOC07. The AP rises to 83.2 % for moSSD and 86.3 % for resSSD, respectively. The average inference speed is 28 ms per image for moSSD and 38 ms per image for resSSD using Nvidia Quadro P6000. Our method is applicable to other CNN-based object detectors and can potentially generalize for detecting other objects in omnidirectional images.
OmniFlow: Human Omnidirectional Optical Flow
Apr 16, 2021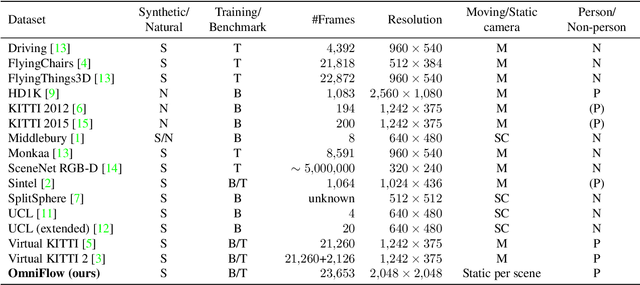
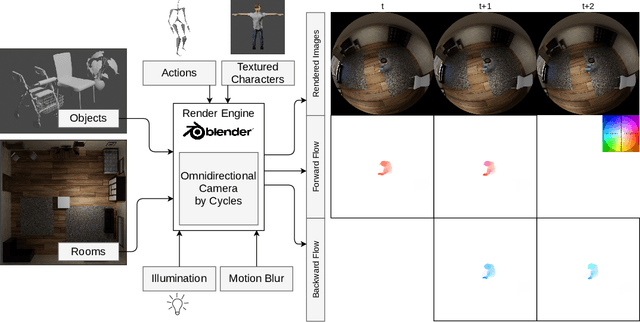
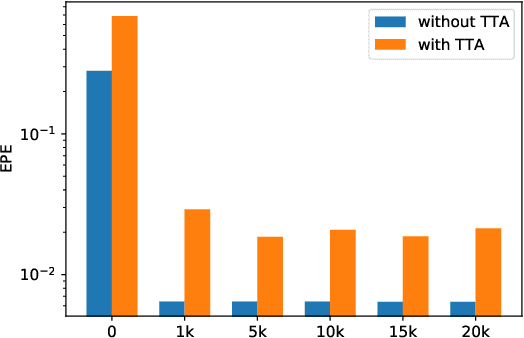
Optical flow is the motion of a pixel between at least two consecutive video frames and can be estimated through an end-to-end trainable convolutional neural network. To this end, large training datasets are required to improve the accuracy of optical flow estimation. Our paper presents OmniFlow: a new synthetic omnidirectional human optical flow dataset. Based on a rendering engine we create a naturalistic 3D indoor environment with textured rooms, characters, actions, objects, illumination and motion blur where all components of the environment are shuffled during the data capturing process. The simulation has as output rendered images of household activities and the corresponding forward and backward optical flow. To verify the data for training volumetric correspondence networks for optical flow estimation we train different subsets of the data and test on OmniFlow with and without Test-Time-Augmentation. As a result we have generated 23,653 image pairs and corresponding forward and backward optical flow. Our dataset can be downloaded from: https://mytuc.org/byfs
Unsupervised Domain Adaptation from Synthetic to Real Images for Anchorless Object Detection
Dec 15, 2020

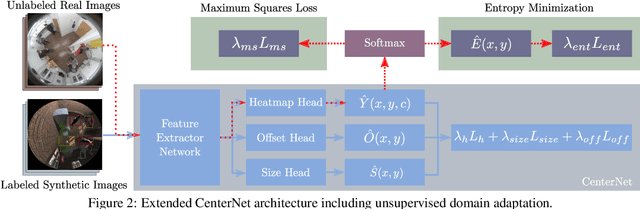

Synthetic images are one of the most promising solutions to avoid high costs associated with generating annotated datasets to train supervised convolutional neural networks (CNN). However, to allow networks to generalize knowledge from synthetic to real images, domain adaptation methods are necessary. This paper implements unsupervised domain adaptation (UDA) methods on an anchorless object detector. Given their good performance, anchorless detectors are increasingly attracting attention in the field of object detection. While their results are comparable to the well-established anchor-based methods, anchorless detectors are considerably faster. In our work, we use CenterNet, one of the most recent anchorless architectures, for a domain adaptation problem involving synthetic images. Taking advantage of the architecture of anchorless detectors, we propose to adjust two UDA methods, viz., entropy minimization and maximum squares loss, originally developed for segmentation, to object detection. Our results show that the proposed UDA methods can increase the mAPfrom61 %to69 %with respect to direct transfer on the considered anchorless detector. The code is available: https://github.com/scheckmedia/centernet-uda.
Where to drive: free space detection with one fisheye camera
Nov 11, 2020The development in the field of autonomous driving goes hand in hand with ever new developments in the field of image processing and machine learning methods. In order to fully exploit the advantages of deep learning, it is necessary to have sufficient labeled training data available. This is especially not the case for omnidirectional fisheye cameras. As a solution, we propose in this paper to use synthetic training data based on Unity3D. A five-pass algorithm is used to create a virtual fisheye camera. This synthetic training data is evaluated for the application of free space detection for different deep learning network architectures. The results indicate that synthetic fisheye images can be used in deep learning context.
* Accepted at International Conference on Machine Vision 2019 (ICMV 2019)
A CNN-based Feature Space for Semi-supervised Incremental Learning in Assisted Living Applications
Nov 11, 2020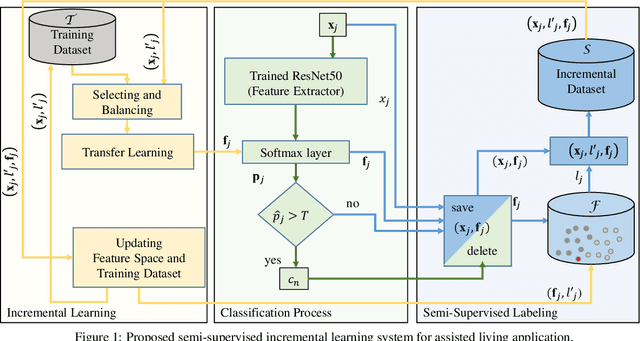
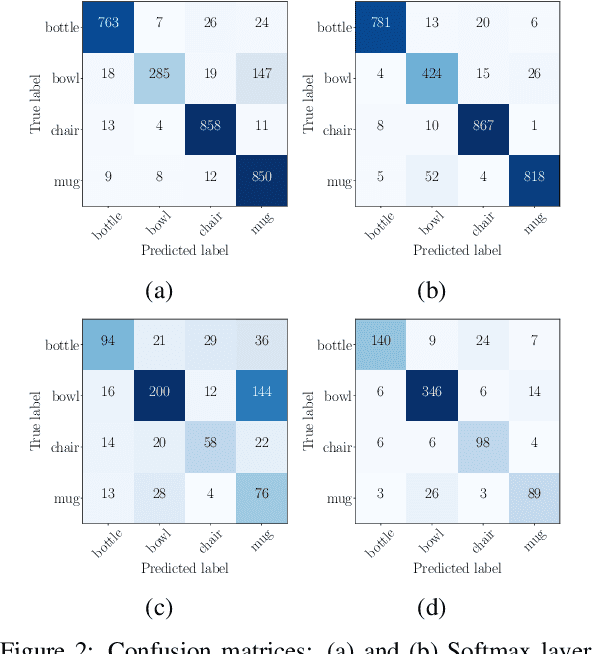

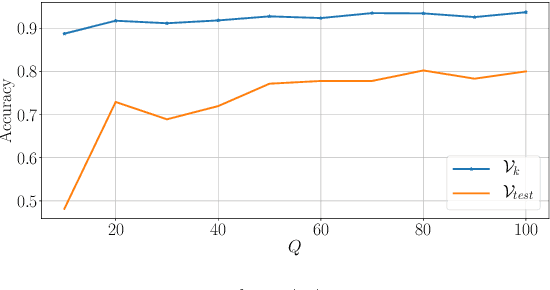
A Convolutional Neural Network (CNN) is sometimes confronted with objects of changing appearance ( new instances) that exceed its generalization capability. This requires the CNN to incorporate new knowledge, i.e., to learn incrementally. In this paper, we are concerned with this problem in the context of assisted living. We propose using the feature space that results from the training dataset to automatically label problematic images that could not be properly recognized by the CNN. The idea is to exploit the extra information in the feature space for a semi-supervised labeling and to employ problematic images to improve the CNN's classification model. Among other benefits, the resulting semi-supervised incremental learning process allows improving the classification accuracy of new instances by 40% as illustrated by extensive experiments.
Learning from THEODORE: A Synthetic Omnidirectional Top-View Indoor Dataset for Deep Transfer Learning
Nov 11, 2020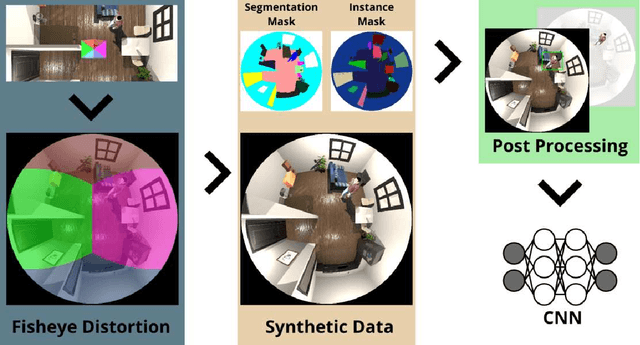
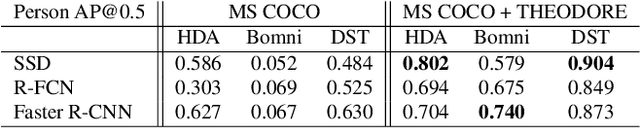


Recent work about synthetic indoor datasets from perspective views has shown significant improvements of object detection results with Convolutional Neural Networks(CNNs). In this paper, we introduce THEODORE: a novel, large-scale indoor dataset containing 100,000 high-resolution diversified fisheye images with 14 classes. To this end, we create 3D virtual environments of living rooms, different human characters and interior textures. Beside capturing fisheye images from virtual environments we create annotations for semantic segmentation, instance masks and bounding boxes for object detection tasks. We compare our synthetic dataset to state of the art real-world datasets for omnidirectional images. Based on MS COCO weights, we show that our dataset is well suited for fine-tuning CNNs for object detection. Through a high generalization of our models by means of image synthesis and domain randomization, we reach an AP up to 0.84 for class person on High-Definition Analytics dataset.
OmniDetector: With Neural Networks to Bounding Boxes
May 22, 2018
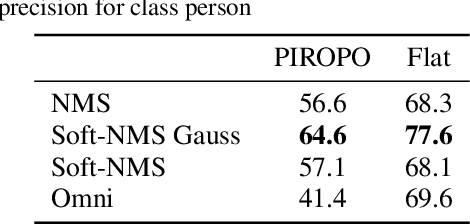
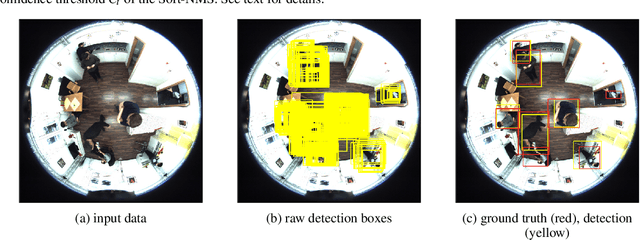
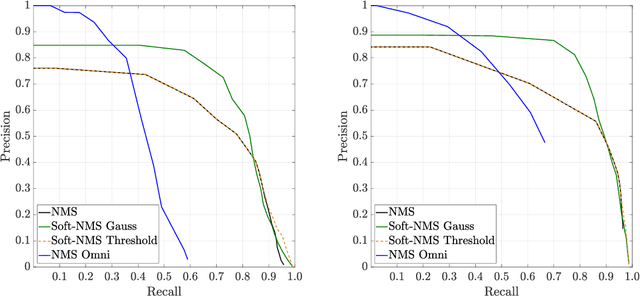
We propose a person detector on omnidirectional images, an accurate method to generate minimal enclosing rectangles of persons. The basic idea is to adapt the qualitative detection performance of a convolutional neural network based method, namely YOLOv2 to fish-eye images. The design of our approach picks up the idea of a state-of-the-art object detector and highly overlapping areas of images with their regions of interests. This overlap reduces the number of false negatives. Based on the raw bounding boxes of the detector we fine-tuned overlapping bounding boxes by three approaches. The non-maximum suppression, the soft non-maximum suppression and the soft non-maximum suppression with Gaussian smoothing. The evaluation was done on the PIROPO database, supplemented with bounding boxes on omnidirectional images. We achieve an average precision of 64.4 % with YOLOv2 for the class person. For this purpose we fine-tuned the soft non-maximum suppression with Gaussian smoothing.