 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNToP: NeRF-Powered Large-scale Dataset Generation for 2D and 3D Human Pose Estimation in Top-View Fisheye Images
Feb 28, 2024

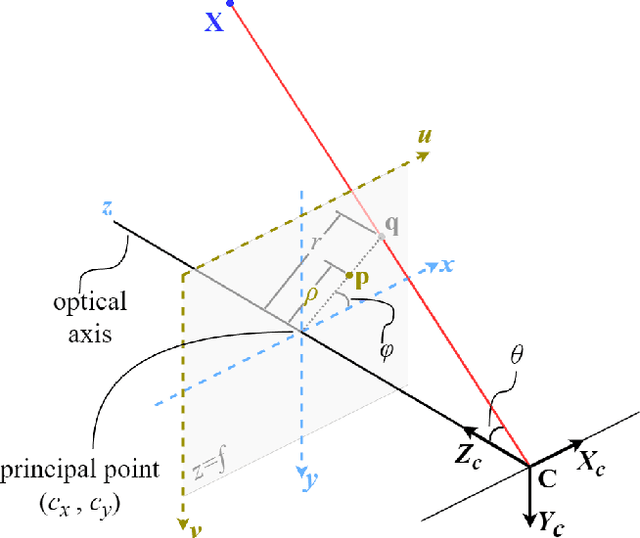
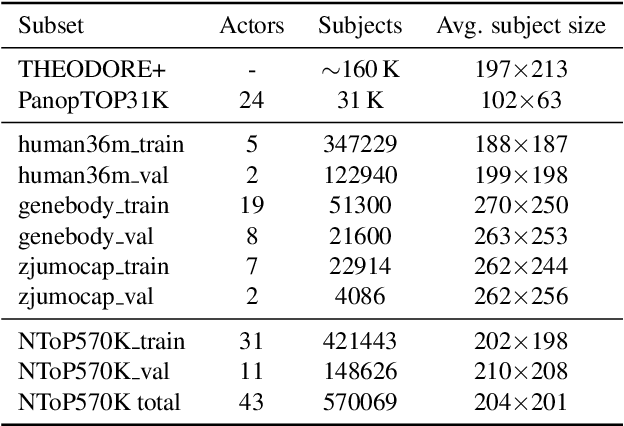
Human pose estimation (HPE) in the top-view using fisheye cameras presents a promising and innovative application domain. However, the availability of datasets capturing this viewpoint is extremely limited, especially those with high-quality 2D and 3D keypoint annotations. Addressing this gap, we leverage the capabilities of Neural Radiance Fields (NeRF) technique to establish a comprehensive pipeline for generating human pose datasets from existing 2D and 3D datasets, specifically tailored for the top-view fisheye perspective. Through this pipeline, we create a novel dataset NToP570K (NeRF-powered Top-view human Pose dataset for fisheye cameras with over 570 thousand images), and conduct an extensive evaluation of its efficacy in enhancing neural networks for 2D and 3D top-view human pose estimation. A pretrained ViTPose-B model achieves an improvement in AP of 33.3 % on our validation set for 2D HPE after finetuning on our training set. A similarly finetuned HybrIK-Transformer model gains 53.7 mm reduction in PA-MPJPE for 3D HPE on the validation set.
Human Pose Estimation in Monocular Omnidirectional Top-View Images
Apr 17, 2023Human pose estimation (HPE) with convolutional neural networks (CNNs) for indoor monitoring is one of the major challenges in computer vision. In contrast to HPE in perspective views, an indoor monitoring system can consist of an omnidirectional camera with a field of view of 180{\deg} to detect the pose of a person with only one sensor per room. To recognize human pose, the detection of keypoints is an essential upstream step. In our work we propose a new dataset for training and evaluation of CNNs for the task of keypoint detection in omnidirectional images. The training dataset, THEODORE+, consists of 50,000 images and is created by a 3D rendering engine, where humans are randomly walking through an indoor environment. In a dynamically created 3D scene, persons move randomly with simultaneously moving omnidirectional camera to generate synthetic RGB images and 2D and 3D ground truth. For evaluation purposes, the real-world PoseFES dataset with two scenarios and 701 frames with up to eight persons per scene was captured and annotated. We propose four training paradigms to finetune or re-train two top-down models in MMPose and two bottom-up models in CenterNet on THEODORE+. Beside a qualitative evaluation we report quantitative results. Compared to a COCO pretrained baseline, we achieve significant improvements especially for top-view scenes on the PoseFES dataset. Our datasets can be found at https://www.tu-chemnitz.de/etit/dst/forschung/comp_vision/datasets/index.php.en.