 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNToP: NeRF-Powered Large-scale Dataset Generation for 2D and 3D Human Pose Estimation in Top-View Fisheye Images
Feb 28, 2024

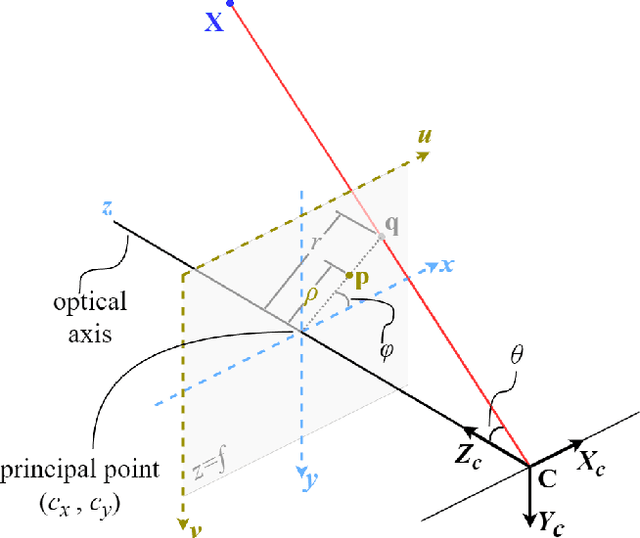
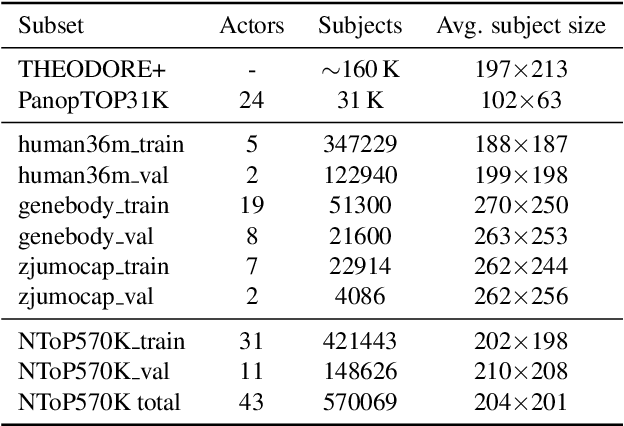
Human pose estimation (HPE) in the top-view using fisheye cameras presents a promising and innovative application domain. However, the availability of datasets capturing this viewpoint is extremely limited, especially those with high-quality 2D and 3D keypoint annotations. Addressing this gap, we leverage the capabilities of Neural Radiance Fields (NeRF) technique to establish a comprehensive pipeline for generating human pose datasets from existing 2D and 3D datasets, specifically tailored for the top-view fisheye perspective. Through this pipeline, we create a novel dataset NToP570K (NeRF-powered Top-view human Pose dataset for fisheye cameras with over 570 thousand images), and conduct an extensive evaluation of its efficacy in enhancing neural networks for 2D and 3D top-view human pose estimation. A pretrained ViTPose-B model achieves an improvement in AP of 33.3 % on our validation set for 2D HPE after finetuning on our training set. A similarly finetuned HybrIK-Transformer model gains 53.7 mm reduction in PA-MPJPE for 3D HPE on the validation set.
Human Pose Estimation in Monocular Omnidirectional Top-View Images
Apr 17, 2023Human pose estimation (HPE) with convolutional neural networks (CNNs) for indoor monitoring is one of the major challenges in computer vision. In contrast to HPE in perspective views, an indoor monitoring system can consist of an omnidirectional camera with a field of view of 180{\deg} to detect the pose of a person with only one sensor per room. To recognize human pose, the detection of keypoints is an essential upstream step. In our work we propose a new dataset for training and evaluation of CNNs for the task of keypoint detection in omnidirectional images. The training dataset, THEODORE+, consists of 50,000 images and is created by a 3D rendering engine, where humans are randomly walking through an indoor environment. In a dynamically created 3D scene, persons move randomly with simultaneously moving omnidirectional camera to generate synthetic RGB images and 2D and 3D ground truth. For evaluation purposes, the real-world PoseFES dataset with two scenarios and 701 frames with up to eight persons per scene was captured and annotated. We propose four training paradigms to finetune or re-train two top-down models in MMPose and two bottom-up models in CenterNet on THEODORE+. Beside a qualitative evaluation we report quantitative results. Compared to a COCO pretrained baseline, we achieve significant improvements especially for top-view scenes on the PoseFES dataset. Our datasets can be found at https://www.tu-chemnitz.de/etit/dst/forschung/comp_vision/datasets/index.php.en.
Applications of Deep Learning for Top-View Omnidirectional Imaging: A Survey
Apr 17, 2023
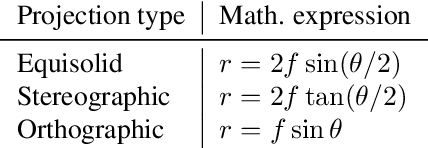
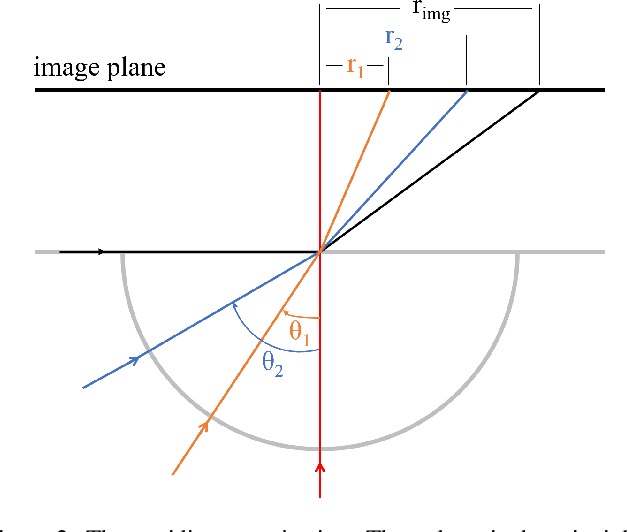
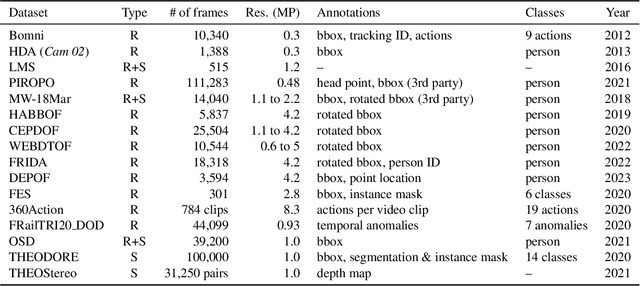
A large field-of-view fisheye camera allows for capturing a large area with minimal numbers of cameras when they are mounted on a high position facing downwards. This top-view omnidirectional setup greatly reduces the work and cost for deployment compared to traditional solutions with multiple perspective cameras. In recent years, deep learning has been widely employed for vision related tasks, including for such omnidirectional settings. In this survey, we look at the application of deep learning in combination with omnidirectional top-view cameras, including the available datasets, human and object detection, human pose estimation, activity recognition and other miscellaneous applications.
OmniPD: One-Step Person Detection in Top-View Omnidirectional Indoor Scenes
Apr 14, 2022
We propose a one-step person detector for topview omnidirectional indoor scenes based on convolutional neural networks (CNNs). While state of the art person detectors reach competitive results on perspective images, missing CNN architectures as well as training data that follows the distortion of omnidirectional images makes current approaches not applicable to our data. The method predicts bounding boxes of multiple persons directly in omnidirectional images without perspective transformation, which reduces overhead of pre- and post-processing and enables real-time performance. The basic idea is to utilize transfer learning to fine-tune CNNs trained on perspective images with data augmentation techniques for detection in omnidirectional images. We fine-tune two variants of Single Shot MultiBox detectors (SSDs). The first one uses Mobilenet v1 FPN as feature extractor (moSSD). The second one uses ResNet50 v1 FPN (resSSD). Both models are pre-trained on Microsoft Common Objects in Context (COCO) dataset. We fine-tune both models on PASCAL VOC07 and VOC12 datasets, specifically on class person. Random 90-degree rotation and random vertical flipping are used for data augmentation in addition to the methods proposed by original SSD. We reach an average precision (AP) of 67.3 % with moSSD and 74.9 % with resSSD onthe evaluation dataset. To enhance the fine-tuning process, we add a subset of HDA Person dataset and a subset of PIROPOdatabase and reduce the number of perspective images to PASCAL VOC07. The AP rises to 83.2 % for moSSD and 86.3 % for resSSD, respectively. The average inference speed is 28 ms per image for moSSD and 38 ms per image for resSSD using Nvidia Quadro P6000. Our method is applicable to other CNN-based object detectors and can potentially generalize for detecting other objects in omnidirectional images.
ViLiVO: Virtual LiDAR-Visual Odometry for an Autonomous Vehicle with a Multi-Camera System
Sep 30, 2019
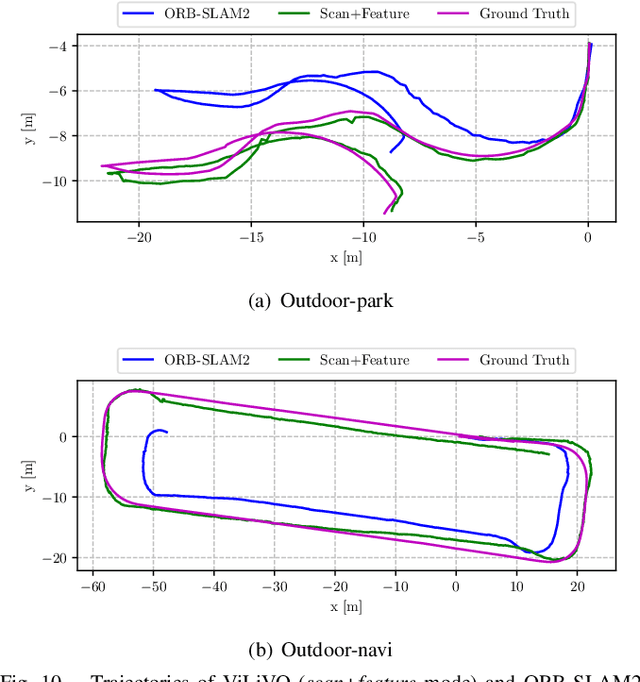
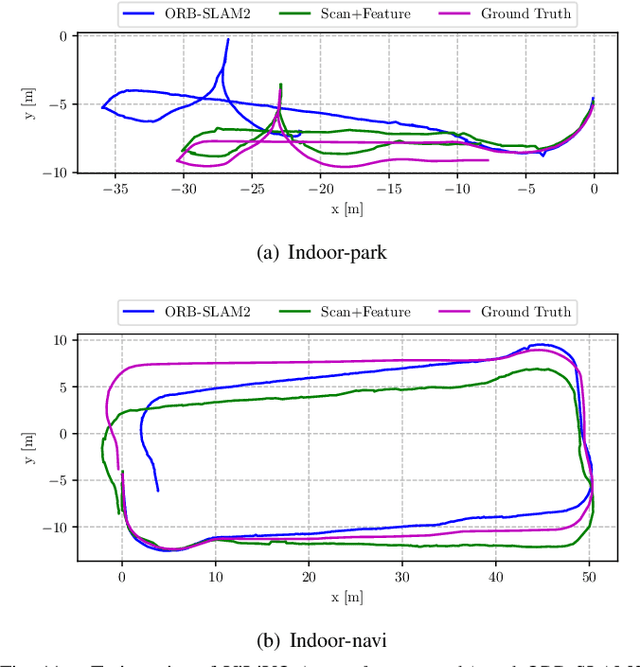
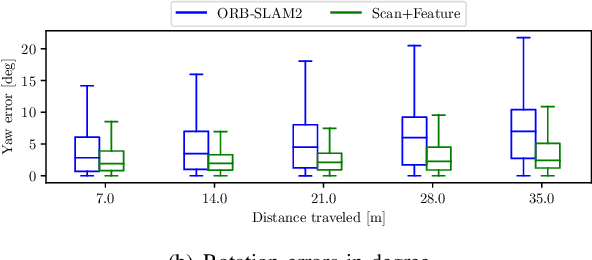
In this paper, we present a multi-camera visual odometry (VO) system for an autonomous vehicle. Our system mainly consists of a virtual LiDAR and a pose tracker. We use a perspective transformation method to synthesize a surround-view image from undistorted fisheye camera images. With a semantic segmentation model, the free space can be extracted. The scans of the virtual LiDAR are generated by discretizing the contours of the free space. As for the pose tracker, we propose a visual odometry system fusing both the feature matching and the virtual LiDAR scan matching results. Only those feature points located in the free space area are utilized to ensure the 2D-2D matching for pose estimation. Furthermore, bundle adjustment (BA) is performed to minimize the feature points reprojection error and scan matching error. We apply our system to an autonomous vehicle equipped with four fisheye cameras. The testing scenarios include an outdoor parking lot as well as an indoor garage. Experimental results demonstrate that our system achieves a more robust and accurate performance comparing with a fisheye camera based monocular visual odometry system.