 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Learning from flowsheets: A generative transformer model for autocompletion of flowsheets
Aug 01, 2022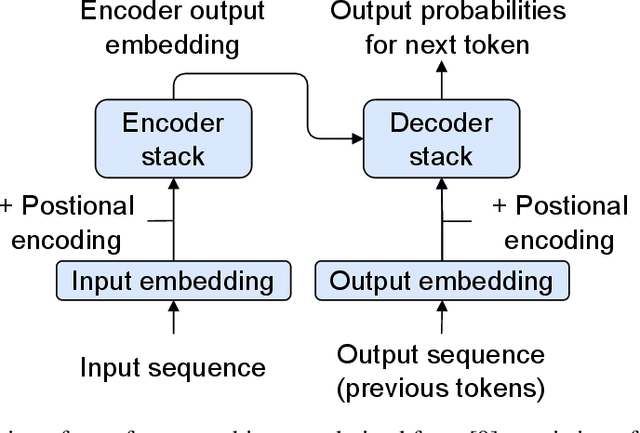


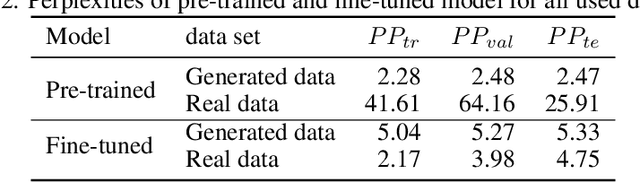
We propose a novel method enabling autocompletion of chemical flowsheets. This idea is inspired by the autocompletion of text. We represent flowsheets as strings using the text-based SFILES 2.0 notation and learn the grammatical structure of the SFILES 2.0 language and common patterns in flowsheets using a transformer-based language model. We pre-train our model on synthetically generated flowsheets to learn the flowsheet language grammar. Then, we fine-tune our model in a transfer learning step on real flowsheet topologies. Finally, we use the trained model for causal language modeling to autocomplete flowsheets. Eventually, the proposed method can provide chemical engineers with recommendations during interactive flowsheet synthesis. The results demonstrate a high potential of this approach for future AI-assisted process synthesis.
SFILES 2.0: An extended text-based flowsheet representation
Jul 25, 2022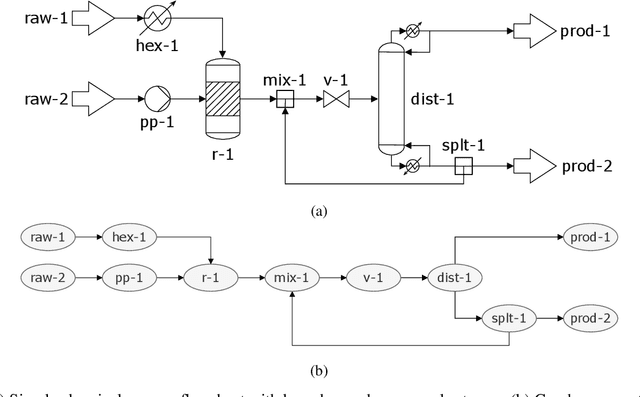

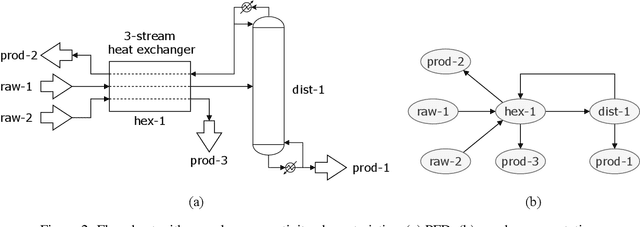
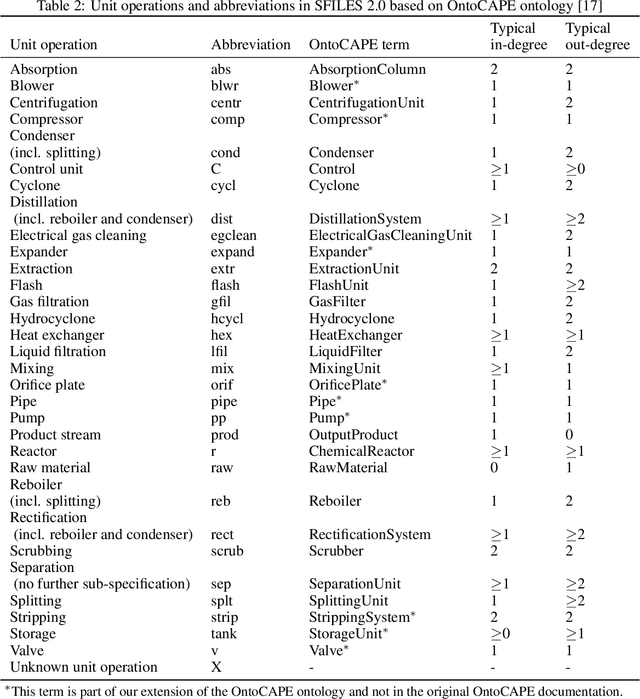
SFILES is a text-based notation for chemical process flowsheets. It was originally proposed by d'Anterroches (2006) who was inspired by the text-based SMILES notation for molecules. The text-based format has several advantages compared to flowsheet images regarding the storage format, computational accessibility, and eventually for data analysis and processing. However, the original SFILES version cannot describe essential flowsheet configurations unambiguously, such as the distinction between top and bottom products. Neither is it capable of describing the control structure required for the safe and reliable operation of chemical processes. Also, there is no publicly available software for decoding or encoding chemical process topologies to SFILES. We propose the SFILES 2.0 with a complete description of the extended notation and naming conventions. Additionally, we provide open-source software for the automated conversion between flowsheet graphs and SFILES 2.0 strings. This way, we hope to encourage researchers and engineers to publish their flowsheet topologies as SFILES 2.0 strings. The ultimate goal is to set the standards for creating a FAIR database of chemical process flowsheets, which would be of great value for future data analysis and processing.