 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking like Piping and Instrumentation Diagrams (P&IDs)
Feb 26, 2025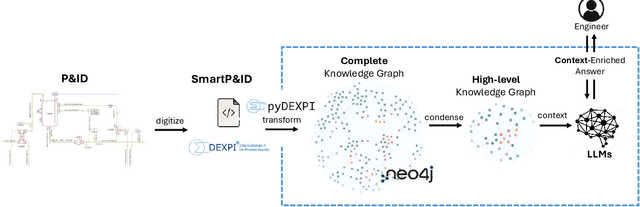
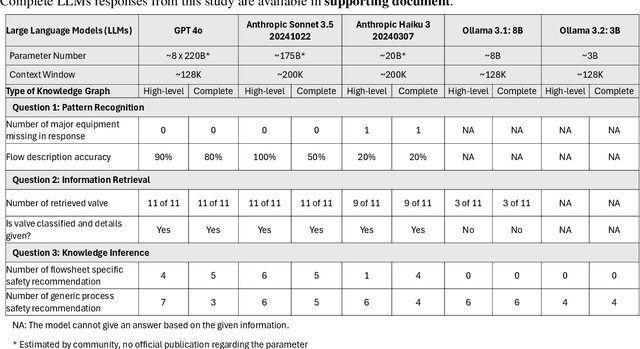
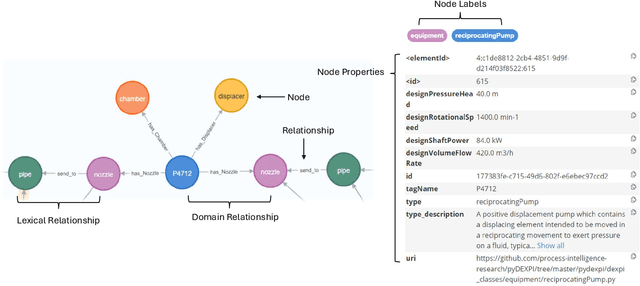
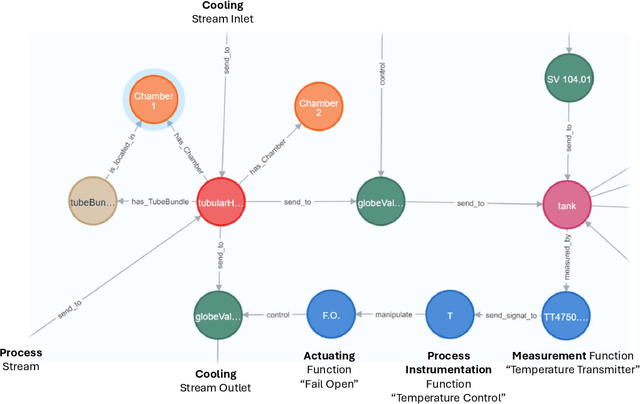
We propose a methodology that allows communication with Piping and Instrumentation Diagrams (P&IDs) using natural language. In particular, we represent P&IDs through the DEXPI data model as labeled property graphs and integrate them with Large Language Models (LLMs). The approach consists of three main parts: 1) P&IDs are cast into a graph representation from the DEXPI format using our pyDEXPI Python package. 2) A tool for generating P&ID knowledge graphs from pyDEXPI. 3) Integration of the P&ID knowledge graph to LLMs using graph-based retrieval augmented generation (graph-RAG). This approach allows users to communicate with P&IDs using natural language. It extends LLM's ability to retrieve contextual data from P&IDs and mitigate hallucinations. Leveraging the LLM's large corpus, the model is also able to interpret process information in PIDs, which could help engineers in their daily tasks. In the future, this work will also open up opportunities in the context of other generative Artificial Intelligence (genAI) solutions on P&IDs, and AI-assisted HAZOP studies.
Rule-based autocorrection of Piping and Instrumentation Diagrams (P&IDs) on graphs
Feb 18, 2025A piping and instrumentation diagram (P&ID) is a central reference document in chemical process engineering. Currently, chemical engineers manually review P&IDs through visual inspection to find and rectify errors. However, engineering projects can involve hundreds to thousands of P&ID pages, creating a significant revision workload. This study proposes a rule-based method to support engineers with error detection and correction in P&IDs. The method is based on a graph representation of P&IDs, enabling automated error detection and correction, i.e., autocorrection, through rule graphs. We use our pyDEXPI Python package to generate P&ID graphs from DEXPI-standard P&IDs. In this study, we developed 33 rules based on chemical engineering knowledge and heuristics, with five selected rules demonstrated as examples. A case study on an illustrative P&ID validates the reliability and effectiveness of the rule-based autocorrection method in revising P&IDs.
Graph-to-SFILES: Control structure prediction from process topologies using generative artificial intelligence
Nov 30, 2024



Control structure design is an important but tedious step in P&ID development. Generative artificial intelligence (AI) promises to reduce P&ID development time by supporting engineers. Previous research on generative AI in chemical process design mainly represented processes by sequences. However, graphs offer a promising alternative because of their permutation invariance. We propose the Graph-to-SFILES model, a generative AI method to predict control structures from flowsheet topologies. The Graph-to-SFILES model takes the flowsheet topology as a graph input and returns a control-extended flowsheet as a sequence in the SFILES 2.0 notation. We compare four different graph encoder architectures, one of them being a graph neural network (GNN) proposed in this work. The Graph-to-SFILES model achieves a top-5 accuracy of 73.2% when trained on 10,000 flowsheet topologies. In addition, the proposed GNN performs best among the encoder architectures. Compared to a purely sequence-based approach, the Graph-to-SFILES model improves the top-5 accuracy for a relatively small training dataset of 1,000 flowsheets from 0.9% to 28.4%. However, the sequence-based approach performs better on a large-scale dataset of 100,000 flowsheets. These results highlight the potential of graph-based AI models to accelerate P&ID development in small-data regimes but their effectiveness on industry relevant case studies still needs to be investigated.
Toward autocorrection of chemical process flowsheets using large language models
Dec 05, 2023The process engineering domain widely uses Process Flow Diagrams (PFDs) and Process and Instrumentation Diagrams (P&IDs) to represent process flows and equipment configurations. However, the P&IDs and PFDs, hereafter called flowsheets, can contain errors causing safety hazards, inefficient operation, and unnecessary expenses. Correcting and verifying flowsheets is a tedious, manual process. We propose a novel generative AI methodology for automatically identifying errors in flowsheets and suggesting corrections to the user, i.e., autocorrecting flowsheets. Inspired by the breakthrough of Large Language Models (LLMs) for grammatical autocorrection of human language, we investigate LLMs for the autocorrection of flowsheets. The input to the model is a potentially erroneous flowsheet and the output of the model are suggestions for a corrected flowsheet. We train our autocorrection model on a synthetic dataset in a supervised manner. The model achieves a top-1 accuracy of 80% and a top-5 accuracy of 84% on an independent test dataset of synthetically generated flowsheets. The results suggest that the model can learn to autocorrect the synthetic flowsheets. We envision that flowsheet autocorrection will become a useful tool for chemical engineers.
Data augmentation for machine learning of chemical process flowsheets
Feb 07, 2023Artificial intelligence has great potential for accelerating the design and engineering of chemical processes. Recently, we have shown that transformer-based language models can learn to auto-complete chemical process flowsheets using the SFILES 2.0 string notation. Also, we showed that language translation models can be used to translate Process Flow Diagrams (PFDs) into Process and Instrumentation Diagrams (P&IDs). However, artificial intelligence methods require big data and flowsheet data is currently limited. To mitigate this challenge of limited data, we propose a new data augmentation methodology for flowsheet data that is represented in the SFILES 2.0 notation. We show that the proposed data augmentation improves the performance of artificial intelligence-based process design models. In our case study flowsheet data augmentation improved the prediction uncertainty of the flowsheet autocompletion model by 14.7%. In the future, our flowsheet data augmentation can be used for other machine learning algorithms on chemical process flowsheets that are based on SFILES notation.
Learning from flowsheets: A generative transformer model for autocompletion of flowsheets
Aug 01, 2022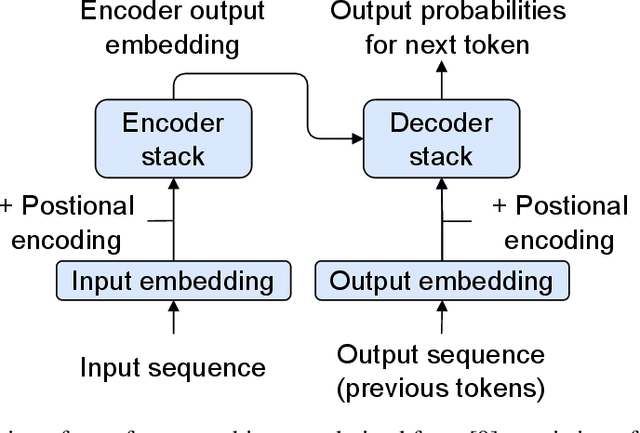


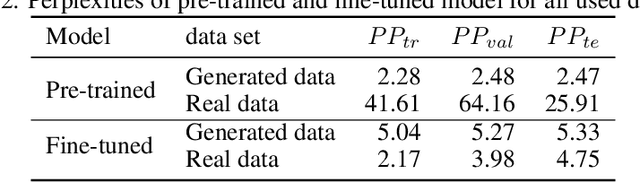
We propose a novel method enabling autocompletion of chemical flowsheets. This idea is inspired by the autocompletion of text. We represent flowsheets as strings using the text-based SFILES 2.0 notation and learn the grammatical structure of the SFILES 2.0 language and common patterns in flowsheets using a transformer-based language model. We pre-train our model on synthetically generated flowsheets to learn the flowsheet language grammar. Then, we fine-tune our model in a transfer learning step on real flowsheet topologies. Finally, we use the trained model for causal language modeling to autocomplete flowsheets. Eventually, the proposed method can provide chemical engineers with recommendations during interactive flowsheet synthesis. The results demonstrate a high potential of this approach for future AI-assisted process synthesis.
SFILES 2.0: An extended text-based flowsheet representation
Jul 25, 2022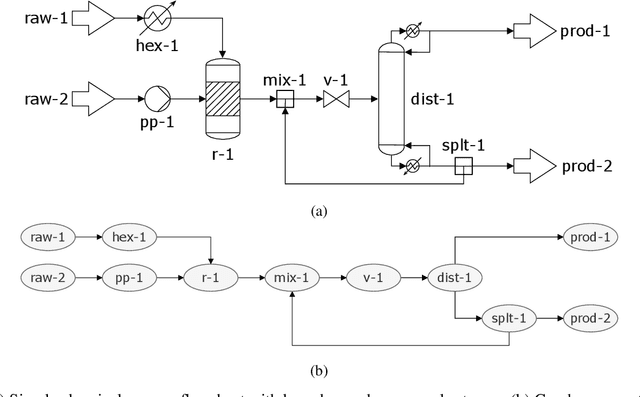

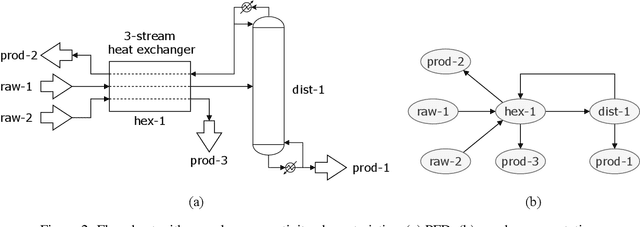
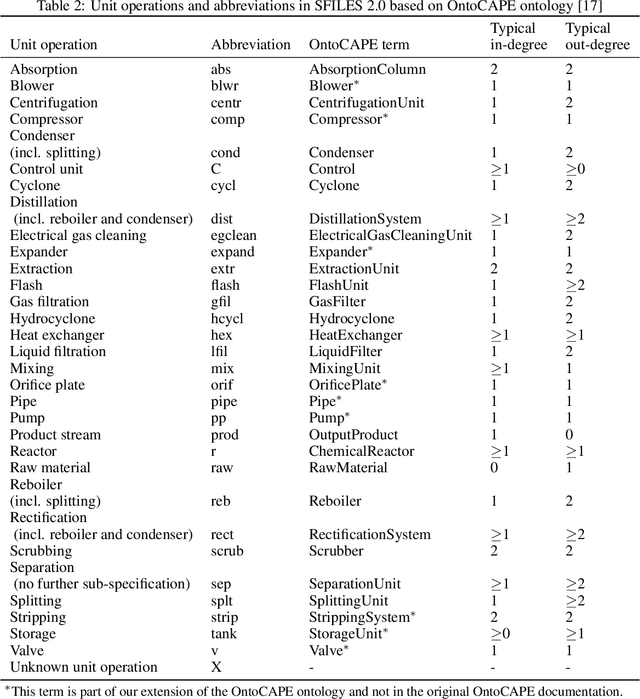
SFILES is a text-based notation for chemical process flowsheets. It was originally proposed by d'Anterroches (2006) who was inspired by the text-based SMILES notation for molecules. The text-based format has several advantages compared to flowsheet images regarding the storage format, computational accessibility, and eventually for data analysis and processing. However, the original SFILES version cannot describe essential flowsheet configurations unambiguously, such as the distinction between top and bottom products. Neither is it capable of describing the control structure required for the safe and reliable operation of chemical processes. Also, there is no publicly available software for decoding or encoding chemical process topologies to SFILES. We propose the SFILES 2.0 with a complete description of the extended notation and naming conventions. Additionally, we provide open-source software for the automated conversion between flowsheet graphs and SFILES 2.0 strings. This way, we hope to encourage researchers and engineers to publish their flowsheet topologies as SFILES 2.0 strings. The ultimate goal is to set the standards for creating a FAIR database of chemical process flowsheets, which would be of great value for future data analysis and processing.