 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaST-VLA: Thinking in Latent Spatio-Temporal Space for Vision-Language-Action in Autonomous Driving
Mar 02, 2026While Vision-Language-Action (VLA) models have revolutionized autonomous driving by unifying perception and planning, their reliance on explicit textual Chain-of-Thought (CoT) leads to semantic-perceptual decoupling and perceptual-symbolic conflicts. Recent shifts toward latent reasoning attempt to bypass these bottlenecks by thinking in continuous hidden space. However, without explicit intermediate constraints, standard latent CoT often operates as a physics-agnostic representation. To address this, we propose the Latent Spatio-Temporal VLA (LaST-VLA), a framework shifting the reasoning paradigm from discrete symbolic processing into a physically grounded Latent Spatio-Temporal CoT. By implementing a dual-feature alignment mechanism, we distill geometric constraints from 3D foundation models and dynamic foresight from world models directly into the latent space. Coupled with a progressive SFT training strategy that transitions from feature alignment to trajectory generation, and refined via Reinforcement Learning with Group Relative Policy Optimization (GRPO) to ensure safety and rule compliance. \method~setting a new record on NAVSIM v1 (91.3 PDMS) and NAVSIM v2 (87.1 EPDMS), while excelling in spatial-temporal reasoning on SURDS and NuDynamics benchmarks.
Unleashing VLA Potentials in Autonomous Driving via Explicit Learning from Failures
Mar 01, 2026Vision-Language-Action (VLA) models for autonomous driving often hit a performance plateau during Reinforcement Learning (RL) optimization. This stagnation arises from exploration capabilities constrained by previous Supervised Fine-Tuning (SFT), leading to persistent failures in long-tail scenarios. In these critical situations, all explored actions yield a zero-value driving score. This information-sparse reward signals a failure, yet fails to identify its root cause -- whether it is due to incorrect planning, flawed reasoning, or poor trajectory execution. To address this limitation, we propose VLA with Explicit Learning from Failures (ELF-VLA), a framework that augments RL with structured diagnostic feedback. Instead of relying on a vague scalar reward, our method produces detailed, interpretable reports that identify the specific failure mode. The VLA policy then leverages this explicit feedback to generate a Feedback-Guided Refinement. By injecting these corrected, high-reward samples back into the RL training batch, our approach provides a targeted gradient, which enables the policy to solve critical scenarios that unguided exploration cannot. Extensive experiments demonstrate that our method unlocks the latent capabilities of VLA models, achieving state-of-the-art (SOTA) performance on the public NAVSIM benchmark for overall PDMS, EPDMS score and high-level planning accuracy.
An Empirical Analysis of Cooperative Perception for Occlusion Risk Mitigation
Feb 26, 2026Occlusions present a significant challenge for connected and automated vehicles, as they can obscure critical road users from perception systems. Traditional risk metrics often fail to capture the cumulative nature of these threats over time adequately. In this paper, we propose a novel and universal risk assessment metric, the Risk of Tracking Loss (RTL), which aggregates instantaneous risk intensity throughout occluded periods. This provides a holistic risk profile that encompasses both high-intensity, short-term threats and prolonged exposure. Utilizing diverse and high-fidelity real-world datasets, a large-scale statistical analysis is conducted to characterize occlusion risk and validate the effectiveness of the proposed metric. The metric is applied to evaluate different vehicle-to-everything (V2X) deployment strategies. Our study shows that full V2X penetration theoretically eliminates this risk, the reduction is highly nonlinear; a substantial statistical benefit requires a high penetration threshold of 75-90%. To overcome this limitation, we propose a novel asymmetric communication framework that allows even non-connected vehicles to receive warnings. Experimental results demonstrate that this paradigm achieves better risk mitigation performance. We found that our approach at 25% penetration outperforms the traditional symmetric model at 75%, and benefits saturate at only 50% penetration. This work provides a crucial risk assessment metric and a cost-effective, strategic roadmap for accelerating the safety benefits of V2X deployment.
Wireless Communication as an Information Sensor for Multi-agent Cooperative Perception: A Survey
Apr 30, 2025Cooperative perception extends the perception capabilities of autonomous vehicles by enabling multi-agent information sharing via Vehicle-to-Everything (V2X) communication. Unlike traditional onboard sensors, V2X acts as a dynamic "information sensor" characterized by limited communication, heterogeneity, mobility, and scalability. This survey provides a comprehensive review of recent advancements from the perspective of information-centric cooperative perception, focusing on three key dimensions: information representation, information fusion, and large-scale deployment. We categorize information representation into data-level, feature-level, and object-level schemes, and highlight emerging methods for reducing data volume and compressing messages under communication constraints. In information fusion, we explore techniques under both ideal and non-ideal conditions, including those addressing heterogeneity, localization errors, latency, and packet loss. Finally, we summarize system-level approaches to support scalability in dense traffic scenarios. Compared with existing surveys, this paper introduces a new perspective by treating V2X communication as an information sensor and emphasizing the challenges of deploying cooperative perception in real-world intelligent transportation systems.
TraF-Align: Trajectory-aware Feature Alignment for Asynchronous Multi-agent Perception
Mar 25, 2025



Cooperative perception presents significant potential for enhancing the sensing capabilities of individual vehicles, however, inter-agent latency remains a critical challenge. Latencies cause misalignments in both spatial and semantic features, complicating the fusion of real-time observations from the ego vehicle with delayed data from others. To address these issues, we propose TraF-Align, a novel framework that learns the flow path of features by predicting the feature-level trajectory of objects from past observations up to the ego vehicle's current time. By generating temporally ordered sampling points along these paths, TraF-Align directs attention from the current-time query to relevant historical features along each trajectory, supporting the reconstruction of current-time features and promoting semantic interaction across multiple frames. This approach corrects spatial misalignment and ensures semantic consistency across agents, effectively compensating for motion and achieving coherent feature fusion. Experiments on two real-world datasets, V2V4Real and DAIR-V2X-Seq, show that TraF-Align sets a new benchmark for asynchronous cooperative perception.
Integrated Sensing and Channel Estimation by Exploiting Dual Timescales for Delay-Doppler Alignment Modulation
Oct 17, 2023



For integrated sensing and communication (ISAC) systems, the channel information essential for communication and sensing tasks fluctuates across different timescales. Specifically, wireless sensing primarily focuses on acquiring path state information (PSI) (e.g., delay, angle, and Doppler) of individual multi-path components to sense the environment, which usually evolves much more slowly than the composite channel state information (CSI) required for communications. Typically, the CSI is approximately unchanged during the channel coherence time, which characterizes the statistical properties of wireless communication channels. However, this concept is less appropriate for describing that for wireless sensing. To this end, in this paper, we introduce a new timescale to study the variation of the PSI from a channel geometric perspective, termed path invariant time, during which the PSI largely remains constant. Our analysis indicates that the path invariant time considerably exceeds the channel coherence time. Thus, capitalizing on these dual timescales of the wireless channel, in this paper, we propose a novel ISAC framework exploiting the recently proposed delay-Doppler alignment modulation (DDAM) technique. Different from most existing studies on DDAM that assume the availability of perfect PSI, in this work, we propose a novel algorithm, termed as adaptive simultaneously orthogonal matching pursuit with support refinement (ASOMP-SR), for joint environment sensing and PSI estimation. We also analyze the performance of DDAM with imperfectly sensed PSI.Simulation results unveil that the proposed DDAM-based ISAC can achieve superior spectral efficiency and a reduced peak-to-average power ratio (PAPR) compared to standard orthogonal frequency division multiplexing (OFDM).
A Spatial Calibration Method for Robust Cooperative Perception
Apr 25, 2023

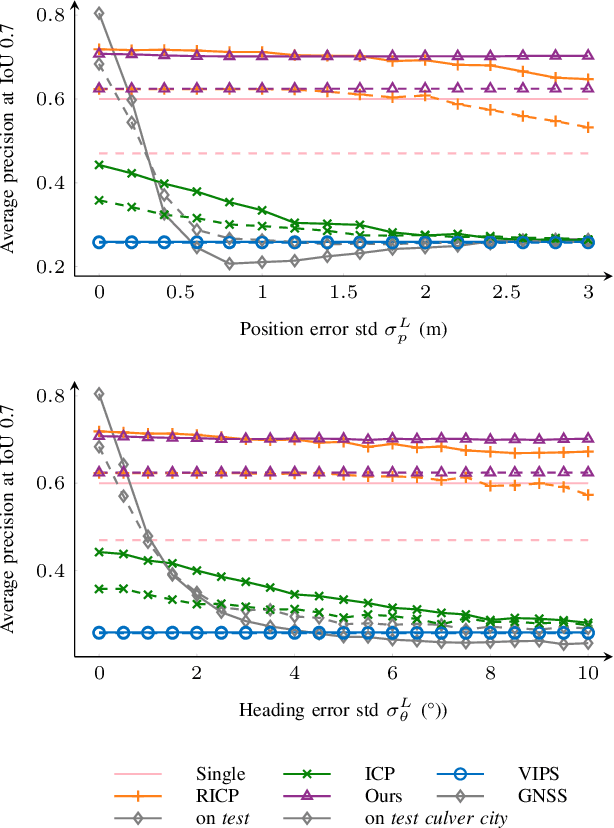

Cooperative perception is a promising technique for enhancing the perception capabilities of automated vehicles through vehicle-to-everything (V2X) cooperation, provided that accurate relative pose transforms are available. Nevertheless, obtaining precise positioning information often entails high costs associated with navigation systems. Moreover, signal drift resulting from factors such as occlusion and multipath effects can compromise the stability of the positioning information. Hence, a low-cost and robust method is required to calibrate relative pose information for multi-agent cooperative perception. In this paper, we propose a simple but effective inter-agent object association approach (CBM), which constructs contexts using the detected bounding boxes, followed by local context matching and global consensus maximization. Based on the matched correspondences, optimal relative pose transform is estimated, followed by cooperative perception fusion. Extensive experimental studies are conducted on both the simulated and real-world datasets, high object association precision and decimeter level relative pose calibration accuracy is achieved among the cooperating agents even with larger inter-agent localization errors. Furthermore, the proposed approach outperforms the state-of-the-art methods in terms of object association and relative pose estimation accuracy, as well as the robustness of cooperative perception against the pose errors of the connected agents. The code will be available at https://github.com/zhyingS/CBM.
An Efficient and Robust Object-Level Cooperative Perception Framework for Connected and Automated Driving
Oct 12, 2022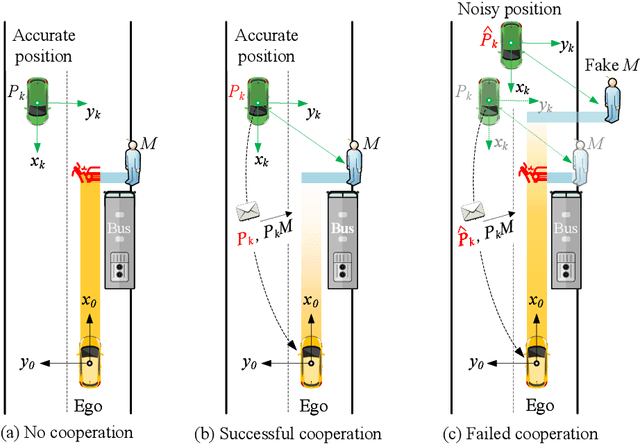

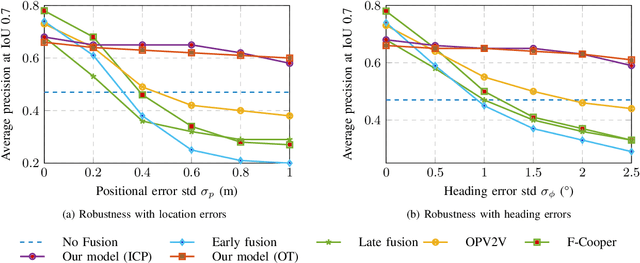
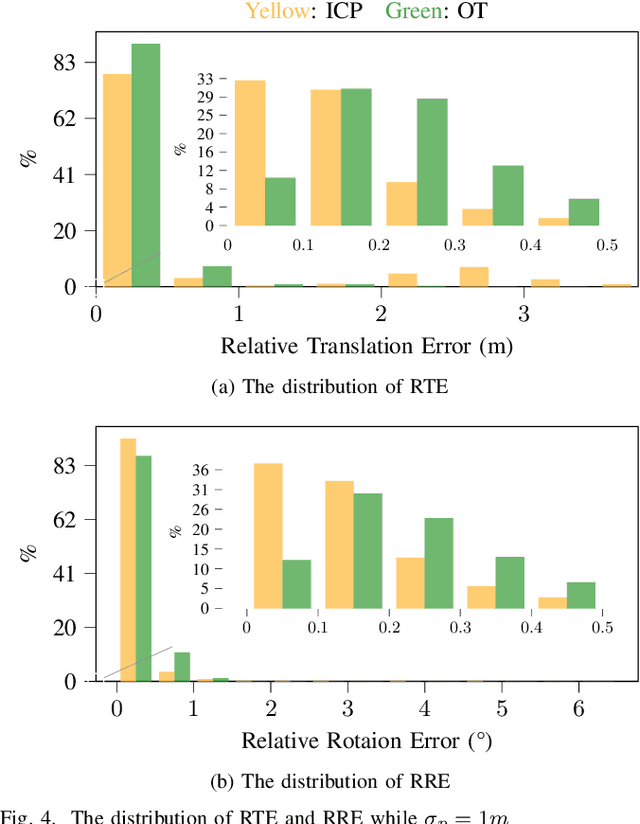
Cooperative perception is challenging for connected and automated driving because of the real-time requirements and bandwidth limitation, especially when the vehicle location and pose information are inaccurate. We propose an efficient object-level cooperative perception framework, in which data of the 3D bounding boxes, location, and pose are broadcast and received between the connected vehicles, then fused at the object level. Two Iterative Closest Point (ICP) and Optimal Transport theory-based matching algorithms are developed to maximize the total correlations between the 3D bounding boxes jointly detected by the vehicles. Experiment results show that it only takes 5ms to associate objects from different vehicles for each frame, and robust performance is achieved for different levels of location and heading errors. Meanwhile, the proposed framework outperforms the state-of-the-art benchmark methods when location or pose errors occur.
An Iterative 5G Positioning and Synchronization Algorithm in NLOS Environments with Multi-Bounce Paths
Sep 04, 2022
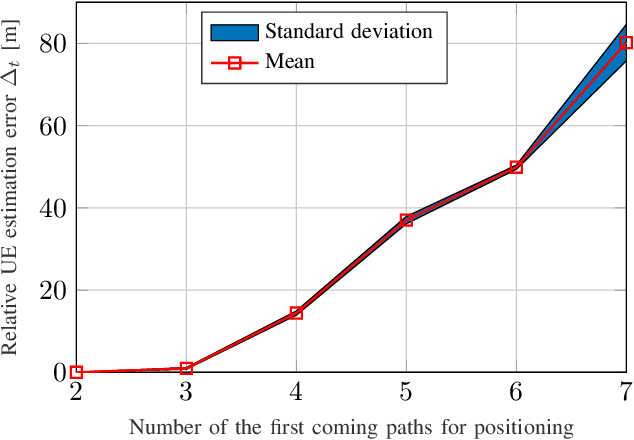
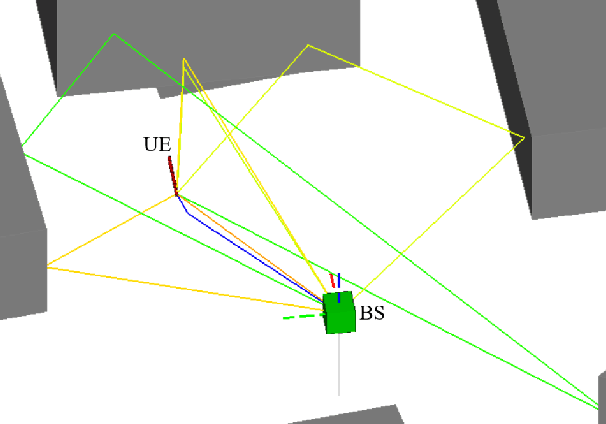
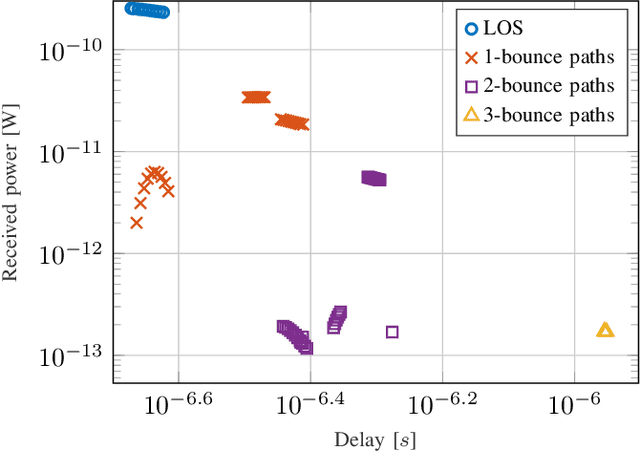
5G positioning is a very promising area that presents many opportunities and challenges. Many existing techniques rely on multiple anchor nodes and line-of-sight (LOS) paths, or single reference node and single-bounce non-LOS (NLOS) paths. However, in dense multipath environments, identifying the LOS or single-bounce assumptions is challenging. The multi-bounce paths will make the positioning accuracy deteriorate significantly. We propose a robust 5G positioning algorithm in NLOS multipath environments. The corresponding positioning problem is formulated as an iterative and weighted least squares problem, and different weights are utilized to mitigate the effects of multi-bounce paths. Numerical simulations are carried out to evaluate the performance of the proposed algorithm. Compared with the benchmark positioning algorithms only using the single-bounce paths, similar positioning accuracy is achieved for the proposed algorithm.
Beamspace Multidimensional ESPRIT Approaches for Simultaneous Localization and Communications
Nov 14, 2021
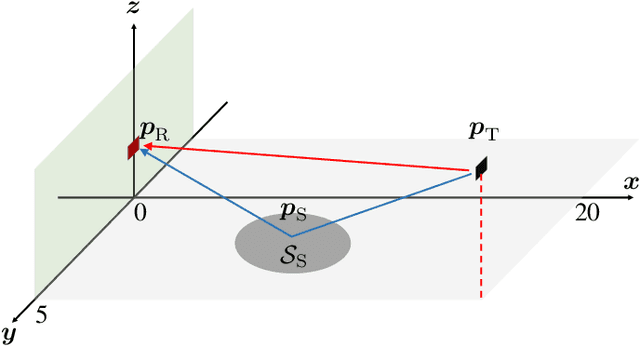

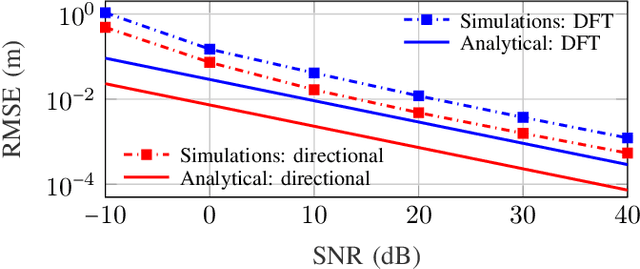
Modern wireless communication systems operating at high carrier frequencies are characterized by a high dimensionality of the underlying parameter space (including channel gains, angles, delays, and possibly Doppler shifts). Estimating these parameters is valuable for communication purposes, but also for localization and sensing, making channel estimation a critical component in any joint communication and localization or sensing application. The high dimensionality make it difficult to use search-based methods such as maximum likelihood. Search-free methods such as ESPRIT provide an attractive alternative, but require a complex decomposition step in both the tensor and matrix version of ESPRIT. To mitigate this, we propose, develop, and analyze a reduced complexity beamspace ESPRIT method. Complexity is reduced both by beampace processing as well as low-complex implementation of the singular value decomposition. A novel perturbation analysis provides important insights for both channel estimation and localization performance. The proposed method is compared to the tensor ESPRIT method, in terms of channel estimation, communication, localization, and sensing performance, further validating the perturbation analysis.