 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Implementation of a Zero-Prior-Knowledge Approach to Lifelong Learning in Kinematic Control of Tendon-Driven Quadrupeds
Aug 21, 2025Like mammals, robots must rapidly learn to control their bodies and interact with their environment despite incomplete knowledge of their body structure and surroundings. They must also adapt to continuous changes in both. This work presents a bio-inspired learning algorithm, General-to-Particular (G2P), applied to a tendon-driven quadruped robotic system developed and fabricated in-house. Our quadruped robot undergoes an initial five-minute phase of generalized motor babbling, followed by 15 refinement trials (each lasting 20 seconds) to achieve specific cyclical movements. This process mirrors the exploration-exploitation paradigm observed in mammals. With each refinement, the robot progressively improves upon its initial "good enough" solution. Our results serve as a proof-of-concept, demonstrating the hardware-in-the-loop system's ability to learn the control of a tendon-driven quadruped with redundancies in just a few minutes to achieve functional and adaptive cyclical non-convex movements. By advancing autonomous control in robotic locomotion, our approach paves the way for robots capable of dynamically adjusting to new environments, ensuring sustained adaptability and performance.
Brain-Body-Task Co-Adaptation can Improve Autonomous Learning and Speed of Bipedal Walking
Feb 04, 2024Inspired by animals that co-adapt their brain and body to interact with the environment, we present a tendon-driven and over-actuated (i.e., n joint, n+1 actuators) bipedal robot that (i) exploits its backdrivable mechanical properties to manage body-environment interactions without explicit control, and (ii) uses a simple 3-layer neural network to learn to walk after only 2 minutes of 'natural' motor babbling (i.e., an exploration strategy that is compatible with leg and task dynamics; akin to childsplay). This brain-body collaboration first learns to produce feet cyclical movements 'in air' and, without further tuning, can produce locomotion when the biped is lowered to be in slight contact with the ground. In contrast, training with 2 minutes of 'naive' motor babbling (i.e., an exploration strategy that ignores leg task dynamics), does not produce consistent cyclical movements 'in air', and produces erratic movements and no locomotion when in slight contact with the ground. When further lowering the biped and making the desired leg trajectories reach 1cm below ground (causing the desired-vs-obtained trajectories error to be unavoidable), cyclical movements based on either natural or naive babbling presented almost equally persistent trends, and locomotion emerged with naive babbling. Therefore, we show how continual learning of walking in unforeseen circumstances can be driven by continual physical adaptation rooted in the backdrivable properties of the plant and enhanced by exploration strategies that exploit plant dynamics. Our studies also demonstrate that the bio-inspired codesign and co-adaptations of limbs and control strategies can produce locomotion without explicit control of trajectory errors.
The utility of tactile force to autonomous learning of in-hand manipulation is task-dependent
Feb 05, 2020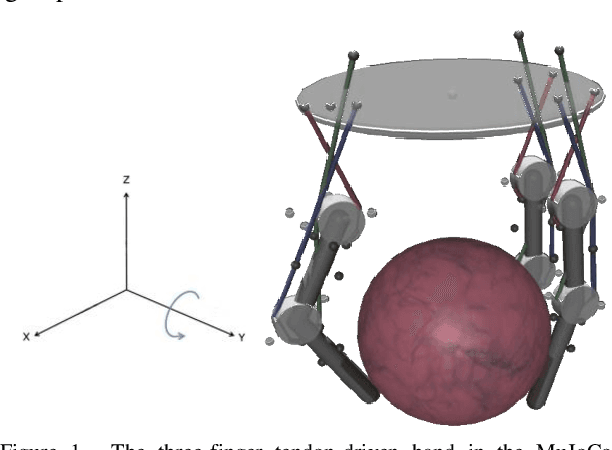

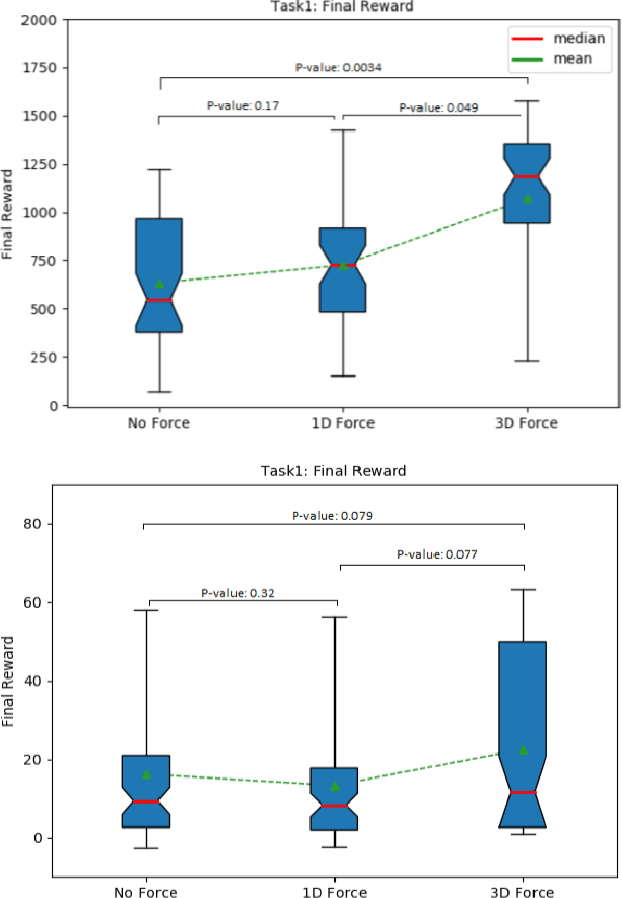
Tactile sensors provide information that can be used to learn and execute manipulation tasks. Different tasks, however, might require different levels of sensory information; which in turn likely affect learning rates and performance. This paper evaluates the role of tactile information on autonomous learning of manipulation with a simulated 3-finger tendon-driven hand. We compare the ability of the same learning algorithm (Proximal Policy Optimization, PPO) to learn two manipulation tasks (rolling a ball about the horizontal axis with and without rotational stiffness) with three levels of tactile sensing: no sensing, 1D normal force, and 3D force vector. Surprisingly, and contrary to recent work on manipulation, adding 1D force-sensing did not always improve learning rates compared to no sensing---likely due to whether or not normal force is relevant to the task. Nonetheless, even though 3D force-sensing increases the dimensionality of the sensory input---which would in general hamper algorithm convergence---it resulted in faster learning rates and better performance. We conclude that, in general, sensory input is useful to learning only when it is relevant to the task---as is the case of 3D force-sensing for in-hand manipulation against gravity. Moreover, the utility of 3D force-sensing can even offset the added computational cost of learning with higher-dimensional sensory input.
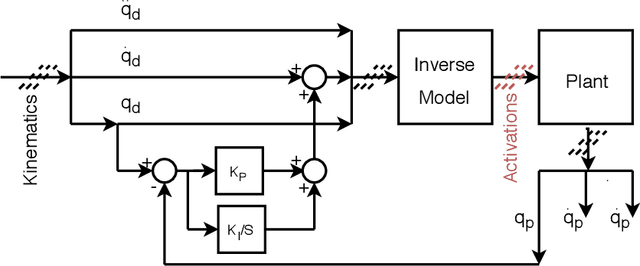
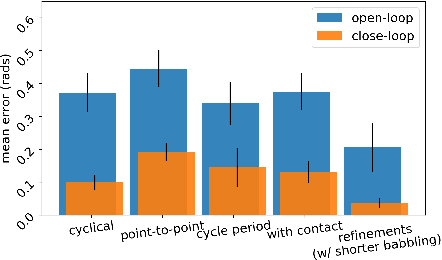
Autonomous Control of a Tendon-driven Robotic Limb with Elastic Elements Reveals that Added Elasticity can Enhance Learning
Sep 26, 2019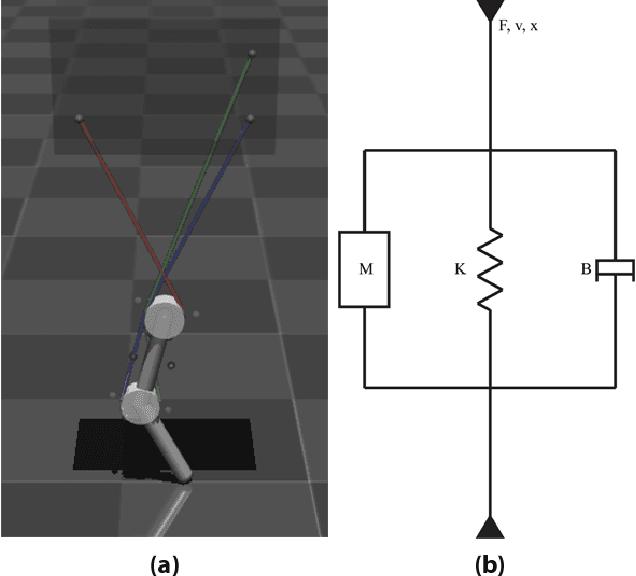
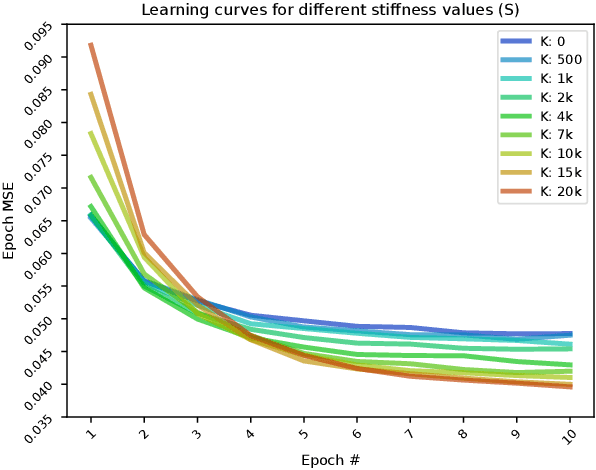
Passive elastic elements can contribute to stability, energetic efficiency, and impact absorption in both biological and robotic systems. They also add dynamical complexity which makes them more challenging to model and control. The impact of this added complexity to autonomous learning has not been thoroughly explored. This is especially relevant to tendon-driven limbs whose cables and tendons are inevitably elastic. Here, we explored the efficacy of autonomous learning and control on a simulated bio-plausible tendon-driven leg across different tendon stiffness values. We demonstrate that increasing stiffness of the simulated muscles can require more iterations for the inverse map to converge but can then perform more accurately, especially in discrete tasks. Moreover, the system is robust to subsequent changes in muscle stiffnesses and can adapt on-the-go within 5 attempts. Lastly, we test the system for the functional task of locomotion, and found similar effects of muscle stiffness to learning and performance. Given that a range of stiffness values led to improved learning and maximized performance, we conclude the robot bodies and autonomous controllers---at least for tendon-driven systems---can be co-developed to take advantage of elastic elements. Importantly, this opens also the door to development efforts that recapitulate the beneficial aspects of the co-evolution of brains and bodies in vertebrates.
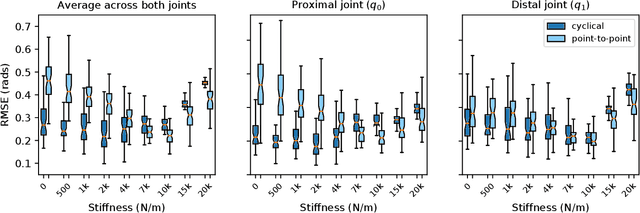
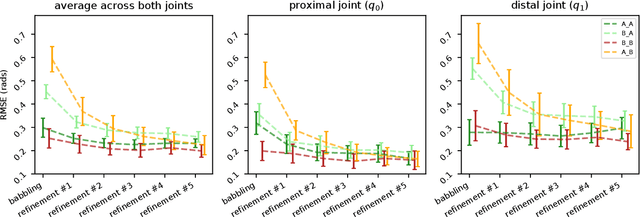
Simple Kinematic Feedback Enhances Autonomous Learning in Bio-Inspired Tendon-Driven Systems
Jul 10, 2019
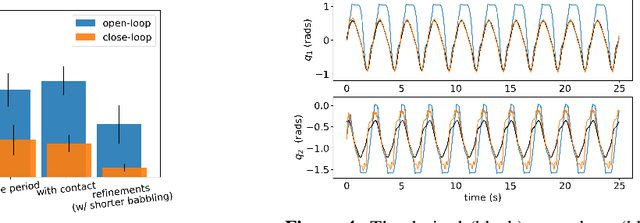
Error feedback is known to improve performance by correcting control signals in response to perturbations. Here we show how adding simple error feedback can also accelerate and robustify autonomous learning in robots. We implemented two versions of the General-to-Particular (G2P) autonomous learning algorithm to produce multiple movement tasks using a tendon-driven leg with two joints and three tendons: one with and one without kinematic feedback. As expected, feedback improved performance in simulation and hardware. However, we see these improvements even in the presence of sensory delays of up to 100 ms and when experiencing substantial contact collisions. Importantly, feedback accelerates learning by enhancing G2P's continual refinement of the initial inverse map because every experience counts. This allows the system to perform well even after only 60 seconds of initial motor babbling.
Autonomous Functional Locomotion in a Tendon-Driven Limb via Limited Experience
Oct 19, 2018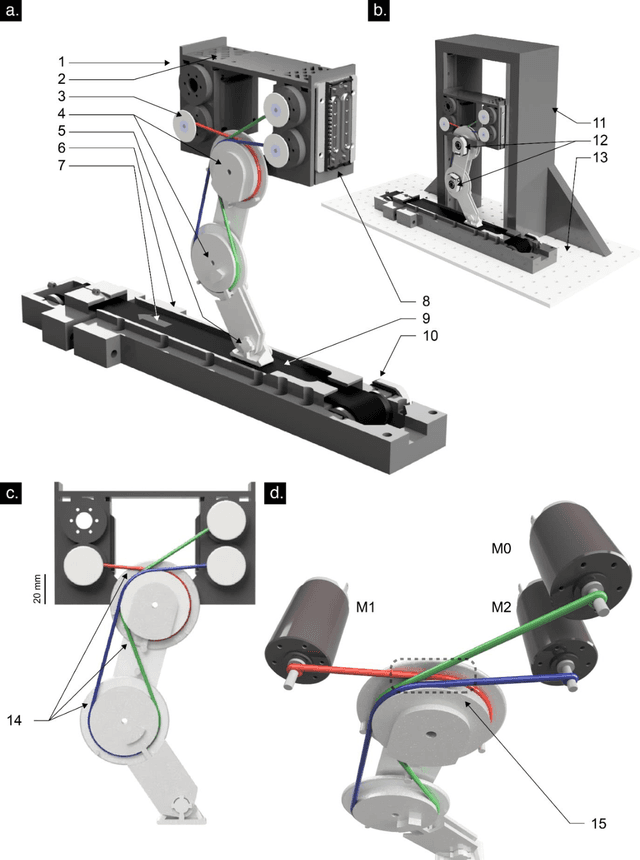
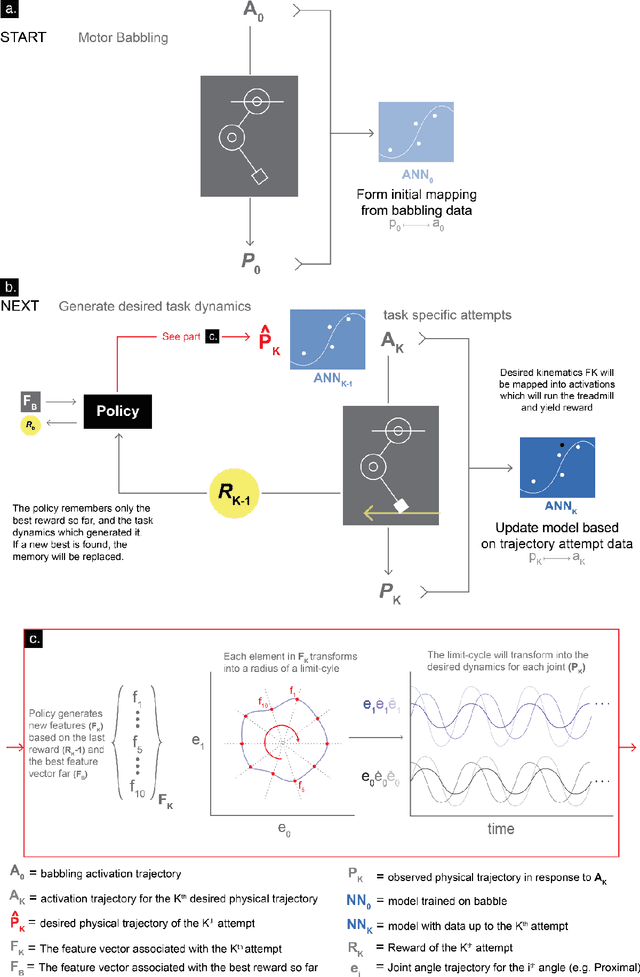
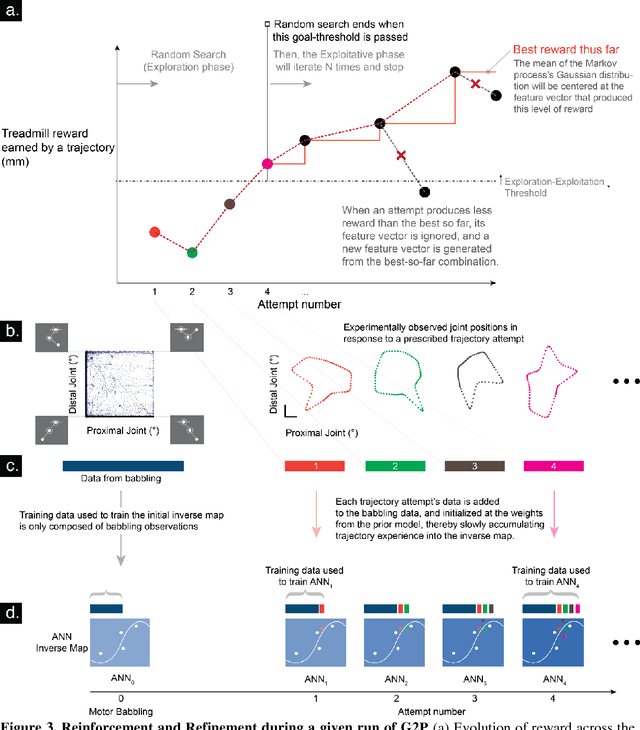
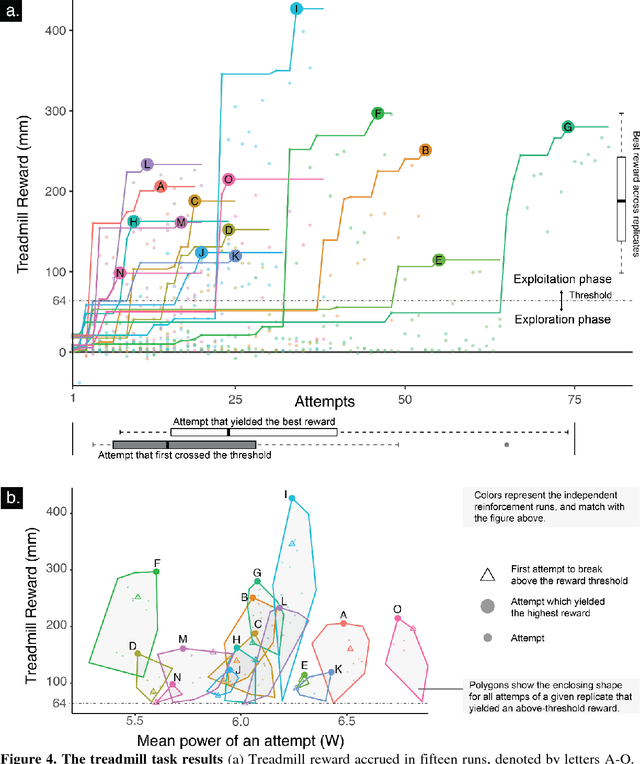
Robots will become ubiquitously useful only when they can use few attempts to teach themselves to perform different tasks, even with complex bodies and in dynamical environments. Vertebrates, in fact, successfully use trial-and-error to learn multiple tasks in spite of their intricate tendon-driven anatomies. Roboticists find such tendon-driven systems particularly hard to control because they are simultaneously nonlinear, under-determined (many tendon tensions combine to produce few net joint torques), and over-determined (few joint rotations define how many tendons need to be reeled-in/payed-out). We demonstrate---for the first time in simulation and in hardware---how a model-free approach allows few-shot autonomous learning to produce effective locomotion in a 3-tendon/2-joint tendon-driven leg. Initially, an artificial neural network fed by sparsely sampled data collected using motor babbling creates an inverse map from limb kinematics to motor activations, which is analogous to juvenile vertebrates playing during development. Thereafter, iterative reward-driven exploration of candidate motor activations simultaneously refines the inverse map and finds a functional locomotor limit-cycle autonomously. This biologically-inspired algorithm, which we call G2P (General to Particular), enables versatile adaptation of robots to changes in the target task, mechanics of their bodies, and environment. Moreover, this work empowers future studies of few-shot autonomous learning in biological systems, which is the foundation of their enviable functional versatility.
Shapechanger: Environments for Transfer Learning
Sep 15, 2017


We present Shapechanger, a library for transfer reinforcement learning specifically designed for robotic tasks. We consider three types of knowledge transfer---from simulation to simulation, from simulation to real, and from real to real---and a wide range of tasks with continuous states and actions. Shapechanger is under active development and open-sourced at: https://github.com/seba-1511/shapechanger/.