 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegaLMFiT: Efficient Short Legal Text Classification with LSTM Language Model Pre-Training
Sep 15, 2021
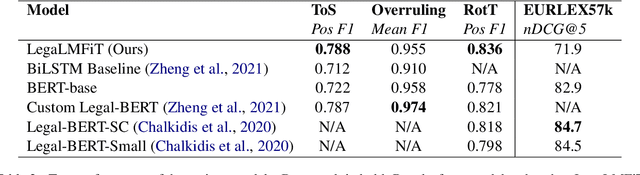
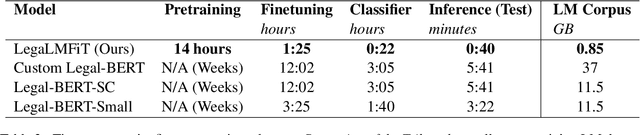
Large Transformer-based language models such as BERT have led to broad performance improvements on many NLP tasks. Domain-specific variants of these models have demonstrated excellent performance on a variety of specialised tasks. In legal NLP, BERT-based models have led to new state-of-the-art results on multiple tasks. The exploration of these models has demonstrated the importance of capturing the specificity of the legal language and its vocabulary. However, such approaches suffer from high computational costs, leading to a higher ecological impact and lower accessibility. Our findings, focusing on English language legal text, show that lightweight LSTM-based Language Models are able to capture enough information from a small legal text pretraining corpus and achieve excellent performance on short legal text classification tasks. This is achieved with a significantly reduced computational overhead compared to BERT-based models. However, our method also shows degraded performance on a more complex task, multi-label classification of longer documents, highlighting the limitations of this lightweight approach.
FuSSI-Net: Fusion of Spatio-temporal Skeletons for Intention Prediction Network
May 15, 2020



Pedestrian intention recognition is very important to develop robust and safe autonomous driving (AD) and advanced driver assistance systems (ADAS) functionalities for urban driving. In this work, we develop an end-to-end pedestrian intention framework that performs well on day- and night- time scenarios. Our framework relies on objection detection bounding boxes combined with skeletal features of human pose. We study early, late, and combined (early and late) fusion mechanisms to exploit the skeletal features and reduce false positives as well to improve the intention prediction performance. The early fusion mechanism results in AP of 0.89 and precision/recall of 0.79/0.89 for pedestrian intention classification. Furthermore, we propose three new metrics to properly evaluate the pedestrian intention systems. Under these new evaluation metrics for the intention prediction, the proposed end-to-end network offers accurate pedestrian intention up to half a second ahead of the actual risky maneuver.
Music Mood Detection Based On Audio And Lyrics With Deep Neural Net
Sep 19, 2018

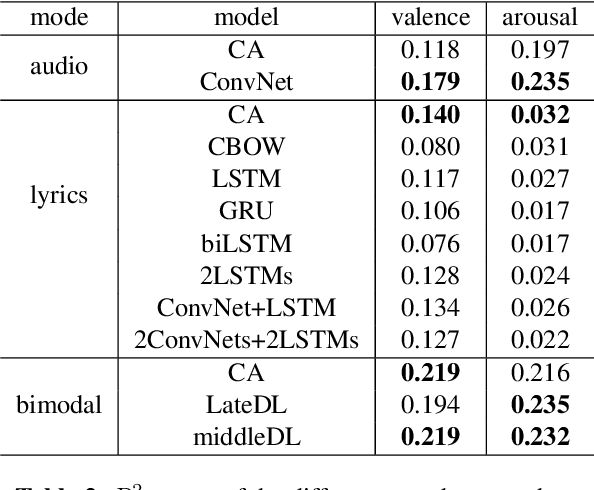

We consider the task of multimodal music mood prediction based on the audio signal and the lyrics of a track. We reproduce the implementation of traditional feature engineering based approaches and propose a new model based on deep learning. We compare the performance of both approaches on a database containing 18,000 tracks with associated valence and arousal values and show that our approach outperforms classical models on the arousal detection task, and that both approaches perform equally on the valence prediction task. We also compare the a posteriori fusion with fusion of modalities optimized simultaneously with each unimodal model, and observe a significant improvement of valence prediction. We release part of our database for comparison purposes.