 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegaLMFiT: Efficient Short Legal Text Classification with LSTM Language Model Pre-Training
Sep 15, 2021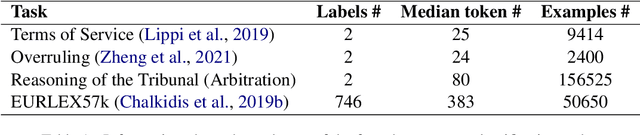
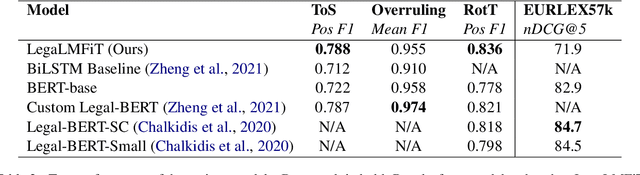
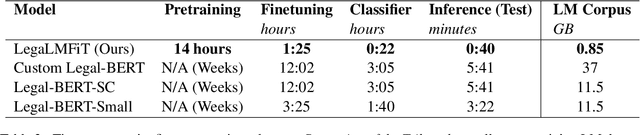
Large Transformer-based language models such as BERT have led to broad performance improvements on many NLP tasks. Domain-specific variants of these models have demonstrated excellent performance on a variety of specialised tasks. In legal NLP, BERT-based models have led to new state-of-the-art results on multiple tasks. The exploration of these models has demonstrated the importance of capturing the specificity of the legal language and its vocabulary. However, such approaches suffer from high computational costs, leading to a higher ecological impact and lower accessibility. Our findings, focusing on English language legal text, show that lightweight LSTM-based Language Models are able to capture enough information from a small legal text pretraining corpus and achieve excellent performance on short legal text classification tasks. This is achieved with a significantly reduced computational overhead compared to BERT-based models. However, our method also shows degraded performance on a more complex task, multi-label classification of longer documents, highlighting the limitations of this lightweight approach.