 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Label Variation in Implicit Discourse Relation Recognition
Feb 26, 2026There is growing recognition that many NLP tasks lack a single ground truth, as human judgments reflect diverse perspectives. To capture this variation, models have been developed to predict full annotation distributions rather than majority labels, while perspectivist models aim to reproduce the interpretations of individual annotators. In this work, we compare these approaches on Implicit Discourse Relation Recognition (IDRR), a highly ambiguous task where disagreement often arises from cognitive complexity rather than ideological bias. Our experiments show that existing annotator-specific models perform poorly in IDRR unless ambiguity is reduced, whereas models trained on label distributions yield more stable predictions. Further analysis indicates that frequent cognitively demanding cases drive inconsistency in human interpretation, posing challenges for perspectivist modeling in IDRR.
Synthetic Data Augmentation for Cross-domain Implicit Discourse Relation Recognition
Mar 26, 2025

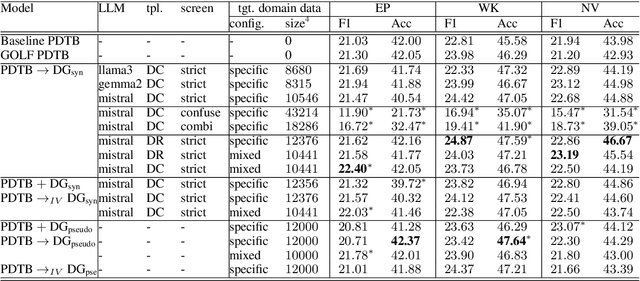

Implicit discourse relation recognition (IDRR) -- the task of identifying the implicit coherence relation between two text spans -- requires deep semantic understanding. Recent studies have shown that zero- or few-shot approaches significantly lag behind supervised models, but LLMs may be useful for synthetic data augmentation, where LLMs generate a second argument following a specified coherence relation. We applied this approach in a cross-domain setting, generating discourse continuations using unlabelled target-domain data to adapt a base model which was trained on source-domain labelled data. Evaluations conducted on a large-scale test set revealed that different variations of the approach did not result in any significant improvements. We conclude that LLMs often fail to generate useful samples for IDRR, and emphasize the importance of considering both statistical significance and comparability when evaluating IDRR models.
On Crowdsourcing Task Design for Discourse Relation Annotation
Dec 16, 2024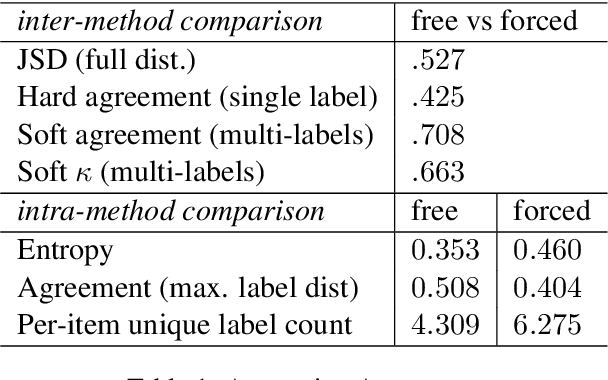
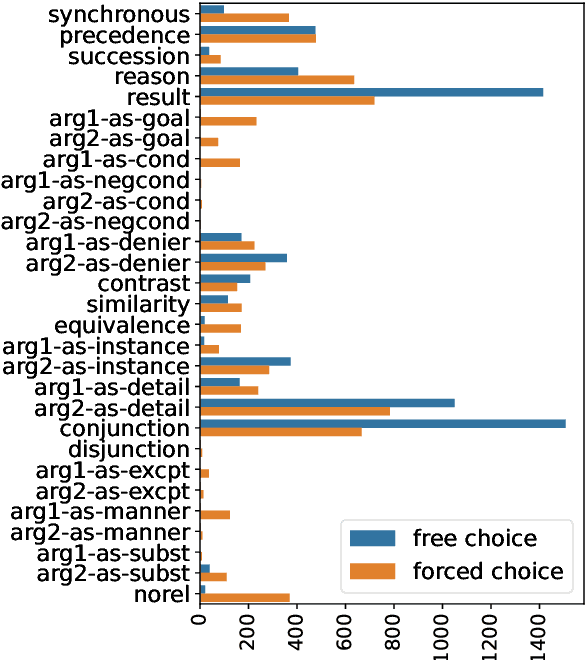
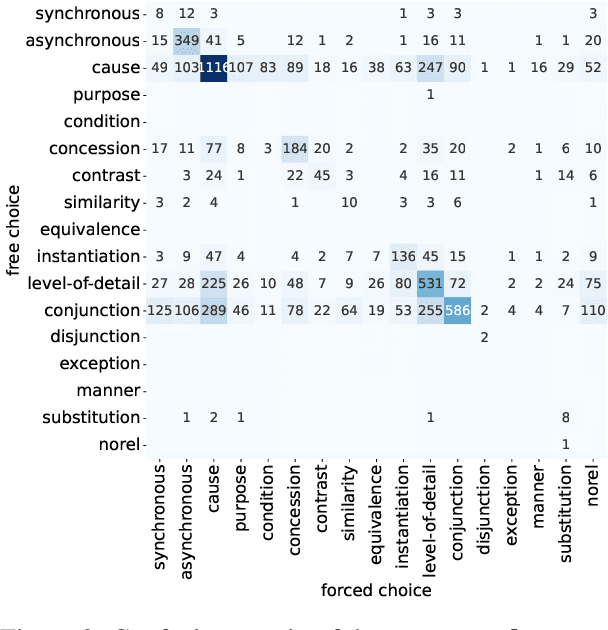

Interpreting implicit discourse relations involves complex reasoning, requiring the integration of semantic cues with background knowledge, as overt connectives like because or then are absent. These relations often allow multiple interpretations, best represented as distributions. In this study, we compare two established methods that crowdsource English implicit discourse relation annotation by connective insertion: a free-choice approach, which allows annotators to select any suitable connective, and a forced-choice approach, which asks them to select among a set of predefined options. Specifically, we re-annotate the whole DiscoGeM 1.0 corpus -- initially annotated with the free-choice method -- using the forced-choice approach. The free-choice approach allows for flexible and intuitive insertion of various connectives, which are context-dependent. Comparison among over 130,000 annotations, however, shows that the free-choice strategy produces less diverse annotations, often converging on common labels. Analysis of the results reveals the interplay between task design and the annotators' abilities to interpret and produce discourse relations.
Prompting Implicit Discourse Relation Annotation
Feb 07, 2024Pre-trained large language models, such as ChatGPT, archive outstanding performance in various reasoning tasks without supervised training and were found to have outperformed crowdsourcing workers. Nonetheless, ChatGPT's performance in the task of implicit discourse relation classification, prompted by a standard multiple-choice question, is still far from satisfactory and considerably inferior to state-of-the-art supervised approaches. This work investigates several proven prompting techniques to improve ChatGPT's recognition of discourse relations. In particular, we experimented with breaking down the classification task that involves numerous abstract labels into smaller subtasks. Nonetheless, experiment results show that the inference accuracy hardly changes even with sophisticated prompt engineering, suggesting that implicit discourse relation classification is not yet resolvable under zero-shot or few-shot settings.
Design Choices for Crowdsourcing Implicit Discourse Relations: Revealing the Biases Introduced by Task Design
Apr 03, 2023Disagreement in natural language annotation has mostly been studied from a perspective of biases introduced by the annotators and the annotation frameworks. Here, we propose to analyze another source of bias: task design bias, which has a particularly strong impact on crowdsourced linguistic annotations where natural language is used to elicit the interpretation of laymen annotators. For this purpose we look at implicit discourse relation annotation, a task that has repeatedly been shown to be difficult due to the relations' ambiguity. We compare the annotations of 1,200 discourse relations obtained using two distinct annotation tasks and quantify the biases of both methods across four different domains. Both methods are natural language annotation tasks designed for crowdsourcing. We show that the task design can push annotators towards certain relations and that some discourse relations senses can be better elicited with one or the other annotation approach. We also conclude that this type of bias should be taken into account when training and testing models.
Acquiring Annotated Data with Cross-lingual Explicitation for Implicit Discourse Relation Classification
Aug 30, 2018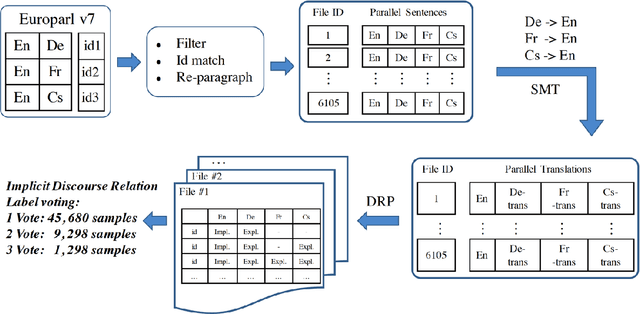
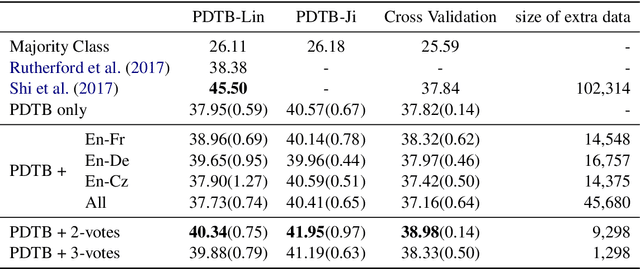
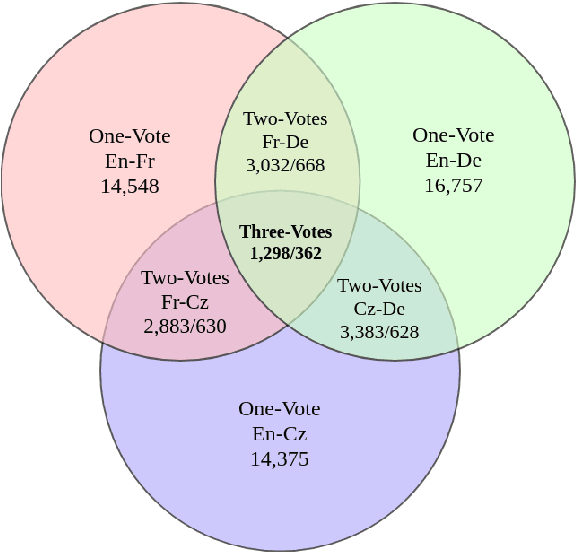
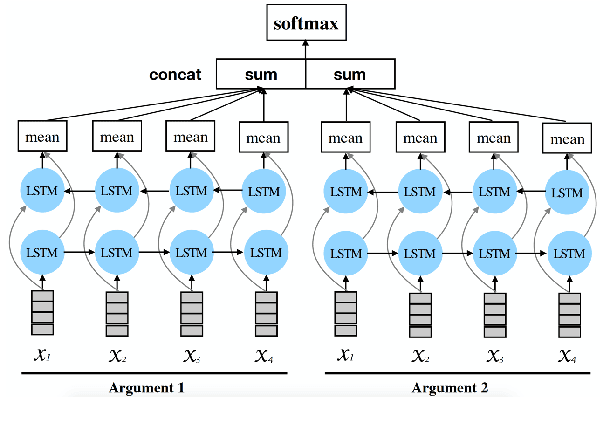
Implicit discourse relation classification is one of the most challenging and important tasks in discourse parsing, due to the lack of connective as strong linguistic cues. A principle bottleneck to further improvement is the shortage of training data (ca.~16k instances in the PDTB). Shi et al. (2017) proposed to acquire additional data by exploiting connectives in translation: human translators mark discourse relations which are implicit in the source language explicitly in the translation. Using back-translations of such explicitated connectives improves discourse relation parsing performance. This paper addresses the open question of whether the choice of the translation language matters, and whether multiple translations into different languages can be effectively used to improve the quality of the additional data.