 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Augmentation for Cross-domain Implicit Discourse Relation Recognition
Paper and Code
Mar 26, 2025

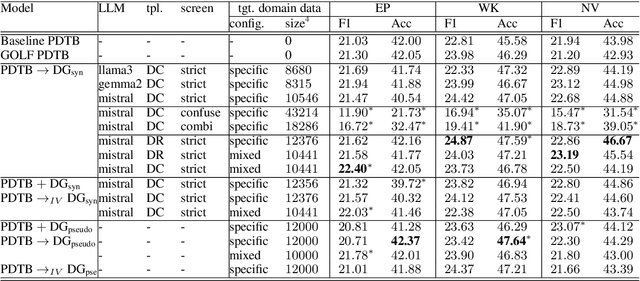

Implicit discourse relation recognition (IDRR) -- the task of identifying the implicit coherence relation between two text spans -- requires deep semantic understanding. Recent studies have shown that zero- or few-shot approaches significantly lag behind supervised models, but LLMs may be useful for synthetic data augmentation, where LLMs generate a second argument following a specified coherence relation. We applied this approach in a cross-domain setting, generating discourse continuations using unlabelled target-domain data to adapt a base model which was trained on source-domain labelled data. Evaluations conducted on a large-scale test set revealed that different variations of the approach did not result in any significant improvements. We conclude that LLMs often fail to generate useful samples for IDRR, and emphasize the importance of considering both statistical significance and comparability when evaluating IDRR models.