 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spoofing Benchmark for the 2018 Voice Conversion Challenge: Leveraging from Spoofing Countermeasures for Speech Artifact Assessment
Sep 04, 2018
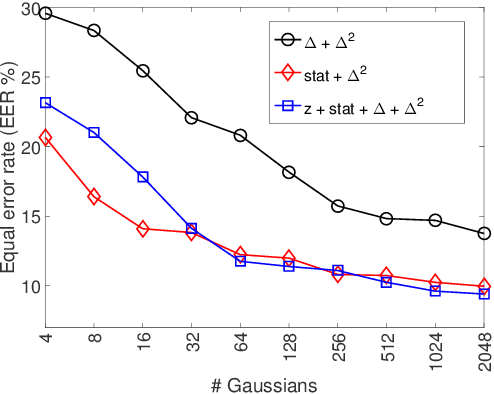
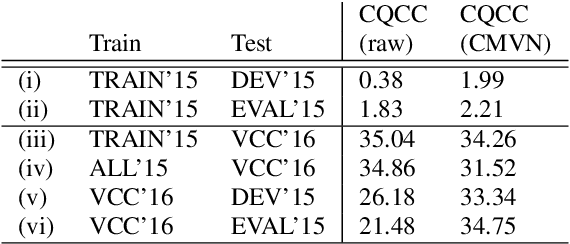
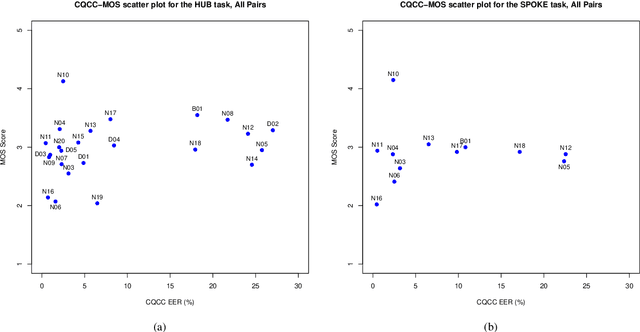
Voice conversion (VC) aims at conversion of speaker characteristic without altering content. Due to training data limitations and modeling imperfections, it is difficult to achieve believable speaker mimicry without introducing processing artifacts; performance assessment of VC, therefore, usually involves both speaker similarity and quality evaluation by a human panel. As a time-consuming, expensive, and non-reproducible process, it hinders rapid prototyping of new VC technology. We address artifact assessment using an alternative, objective approach leveraging from prior work on spoofing countermeasures (CMs) for automatic speaker verification. Therein, CMs are used for rejecting `fake' inputs such as replayed, synthetic or converted speech but their potential for automatic speech artifact assessment remains unknown. This study serves to fill that gap. As a supplement to subjective results for the 2018 Voice Conversion Challenge (VCC'18) data, we configure a standard constant-Q cepstral coefficient CM to quantify the extent of processing artifacts. Equal error rate (EER) of the CM, a confusability index of VC samples with real human speech, serves as our artifact measure. Two clusters of VCC'18 entries are identified: low-quality ones with detectable artifacts (low EERs), and higher quality ones with less artifacts. None of the VCC'18 systems, however, is perfect: all EERs are < 30 % (the `ideal' value would be 50 %). Our preliminary findings suggest potential of CMs outside of their original application, as a supplemental optimization and benchmarking tool to enhance VC technology.
The Voice Conversion Challenge 2018: Promoting Development of Parallel and Nonparallel Methods
Apr 12, 2018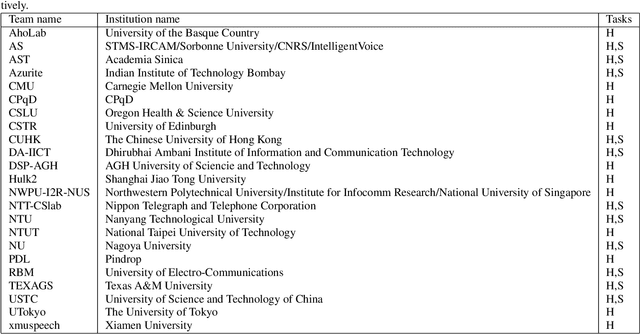
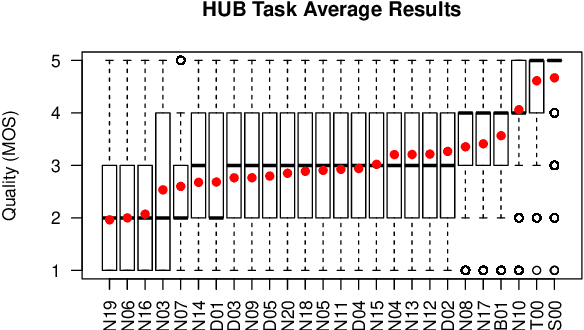
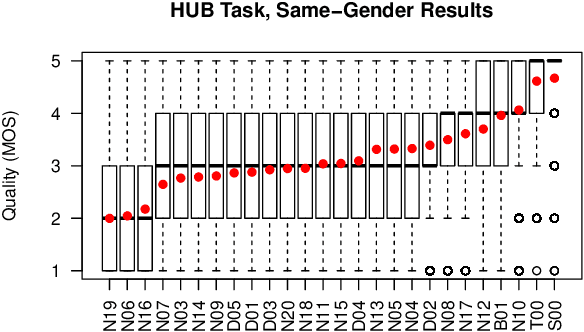
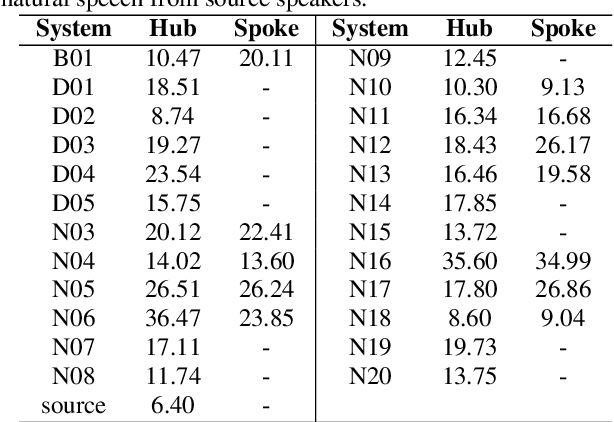
We present the Voice Conversion Challenge 2018, designed as a follow up to the 2016 edition with the aim of providing a common framework for evaluating and comparing different state-of-the-art voice conversion (VC) systems. The objective of the challenge was to perform speaker conversion (i.e. transform the vocal identity) of a source speaker to a target speaker while maintaining linguistic information. As an update to the previous challenge, we considered both parallel and non-parallel data to form the Hub and Spoke tasks, respectively. A total of 23 teams from around the world submitted their systems, 11 of them additionally participated in the optional Spoke task. A large-scale crowdsourced perceptual evaluation was then carried out to rate the submitted converted speech in terms of naturalness and similarity to the target speaker identity. In this paper, we present a brief summary of the state-of-the-art techniques for VC, followed by a detailed explanation of the challenge tasks and the results that were obtained.