 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICE: Intrinsic Concept Extraction from a Single Image via Diffusion Models
Mar 25, 2025The inherent ambiguity in defining visual concepts poses significant challenges for modern generative models, such as the diffusion-based Text-to-Image (T2I) models, in accurately learning concepts from a single image. Existing methods lack a systematic way to reliably extract the interpretable underlying intrinsic concepts. To address this challenge, we present ICE, short for Intrinsic Concept Extraction, a novel framework that exclusively utilizes a T2I model to automatically and systematically extract intrinsic concepts from a single image. ICE consists of two pivotal stages. In the first stage, ICE devises an automatic concept localization module to pinpoint relevant text-based concepts and their corresponding masks within the image. This critical stage streamlines concept initialization and provides precise guidance for subsequent analysis. The second stage delves deeper into each identified mask, decomposing the object-level concepts into intrinsic concepts and general concepts. This decomposition allows for a more granular and interpretable breakdown of visual elements. Our framework demonstrates superior performance on intrinsic concept extraction from a single image in an unsupervised manner. Project page: https://visual-ai.github.io/ice
PromptCCD: Learning Gaussian Mixture Prompt Pool for Continual Category Discovery
Jul 26, 2024We tackle the problem of Continual Category Discovery (CCD), which aims to automatically discover novel categories in a continuous stream of unlabeled data while mitigating the challenge of catastrophic forgetting -- an open problem that persists even in conventional, fully supervised continual learning. To address this challenge, we propose PromptCCD, a simple yet effective framework that utilizes a Gaussian Mixture Model (GMM) as a prompting method for CCD. At the core of PromptCCD lies the Gaussian Mixture Prompting (GMP) module, which acts as a dynamic pool that updates over time to facilitate representation learning and prevent forgetting during category discovery. Moreover, GMP enables on-the-fly estimation of category numbers, allowing PromptCCD to discover categories in unlabeled data without prior knowledge of the category numbers. We extend the standard evaluation metric for Generalized Category Discovery (GCD) to CCD and benchmark state-of-the-art methods on diverse public datasets. PromptCCD significantly outperforms existing methods, demonstrating its effectiveness. Project page: https://visual-ai.github.io/promptccd .
Histopathology Whole Slide Image Analysis with Heterogeneous Graph Representation Learning
Jul 09, 2023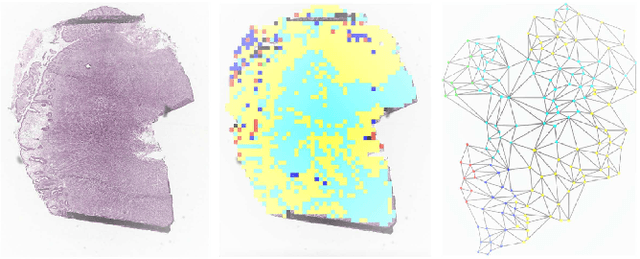
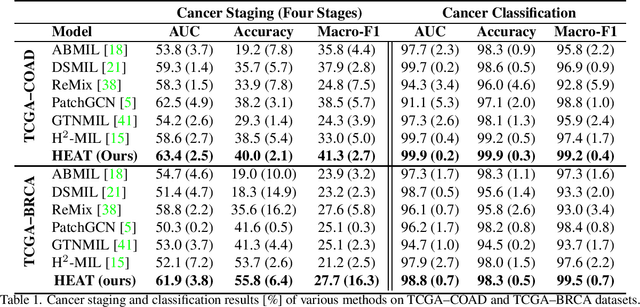
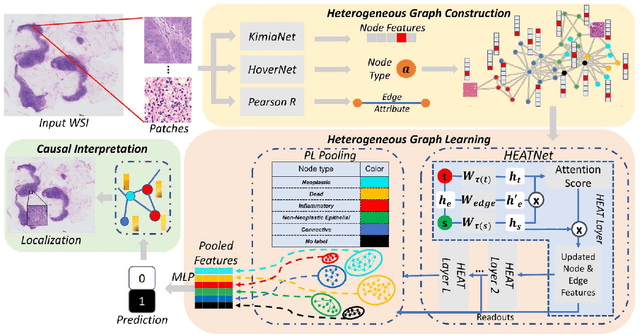
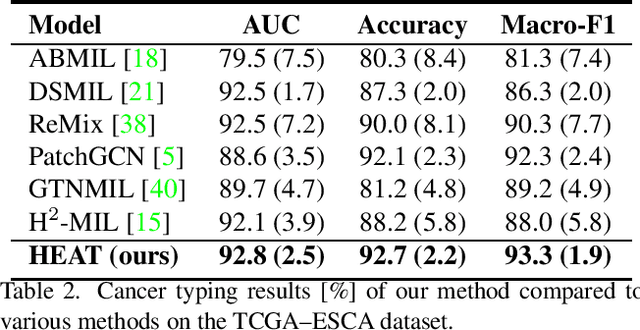
Graph-based methods have been extensively applied to whole-slide histopathology image (WSI) analysis due to the advantage of modeling the spatial relationships among different entities. However, most of the existing methods focus on modeling WSIs with homogeneous graphs (e.g., with homogeneous node type). Despite their successes, these works are incapable of mining the complex structural relations between biological entities (e.g., the diverse interaction among different cell types) in the WSI. We propose a novel heterogeneous graph-based framework to leverage the inter-relationships among different types of nuclei for WSI analysis. Specifically, we formulate the WSI as a heterogeneous graph with "nucleus-type" attribute to each node and a semantic similarity attribute to each edge. We then present a new heterogeneous-graph edge attribute transformer (HEAT) to take advantage of the edge and node heterogeneity during massage aggregating. Further, we design a new pseudo-label-based semantic-consistent pooling mechanism to obtain graph-level features, which can mitigate the over-parameterization issue of conventional cluster-based pooling. Additionally, observing the limitations of existing association-based localization methods, we propose a causal-driven approach attributing the contribution of each node to improve the interpretability of our framework. Extensive experiments on three public TCGA benchmark datasets demonstrate that our framework outperforms the state-of-the-art methods with considerable margins on various tasks. Our codes are available at https://github.com/HKU-MedAI/WSI-HGNN.
SL3D: Self-supervised-Self-labeled 3D Recognition
Nov 03, 2022



There are a lot of promising results in 3D recognition, including classification, object detection, and semantic segmentation. However, many of these results rely on manually collecting densely annotated real-world 3D data, which is highly time-consuming and expensive to obtain, limiting the scalability of 3D recognition tasks. Thus in this paper, we study unsupervised 3D recognition and propose a Self-supervised-Self-Labeled 3D Recognition (SL3D) framework. SL3D simultaneously solves two coupled objectives, i.e., clustering and learning feature representation to generate pseudo labeled data for unsupervised 3D recognition. SL3D is a generic framework and can be applied to solve different 3D recognition tasks, including classification, object detection, and semantic segmentation. Extensive experiments demonstrate its effectiveness. Code is available at https://github.com/fcendra/sl3d.