 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolt-on Differential Privacy for Scalable Stochastic Gradient Descent-based Analytics
Mar 23, 2017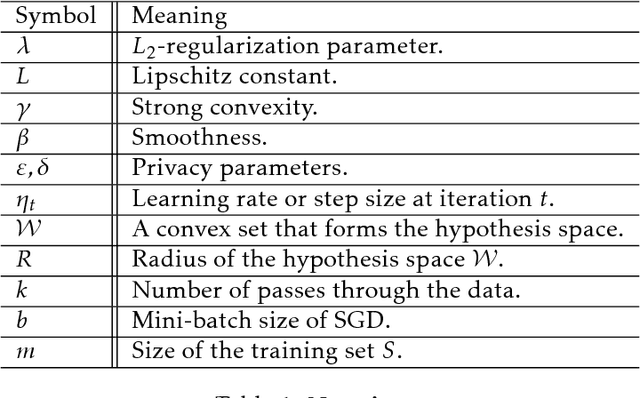
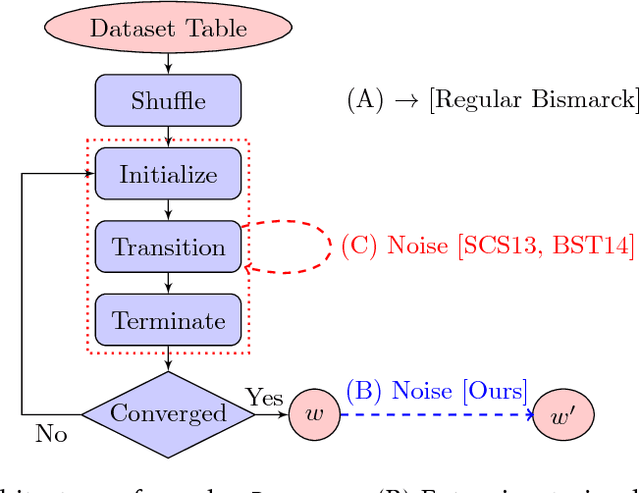
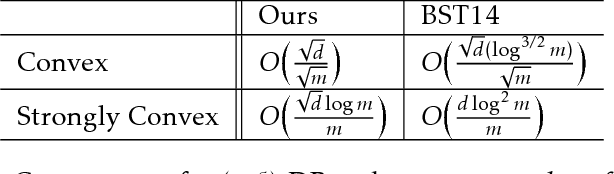

While significant progress has been made separately on analytics systems for scalable stochastic gradient descent (SGD) and private SGD, none of the major scalable analytics frameworks have incorporated differentially private SGD. There are two inter-related issues for this disconnect between research and practice: (1) low model accuracy due to added noise to guarantee privacy, and (2) high development and runtime overhead of the private algorithms. This paper takes a first step to remedy this disconnect and proposes a private SGD algorithm to address \emph{both} issues in an integrated manner. In contrast to the white-box approach adopted by previous work, we revisit and use the classical technique of {\em output perturbation} to devise a novel "bolt-on" approach to private SGD. While our approach trivially addresses (2), it makes (1) even more challenging. We address this challenge by providing a novel analysis of the $L_2$-sensitivity of SGD, which allows, under the same privacy guarantees, better convergence of SGD when only a constant number of passes can be made over the data. We integrate our algorithm, as well as other state-of-the-art differentially private SGD, into Bismarck, a popular scalable SGD-based analytics system on top of an RDBMS. Extensive experiments show that our algorithm can be easily integrated, incurs virtually no overhead, scales well, and most importantly, yields substantially better (up to 4X) test accuracy than the state-of-the-art algorithms on many real datasets.
When Lempel-Ziv-Welch Meets Machine Learning: A Case Study of Accelerating Machine Learning using Coding
Mar 01, 2017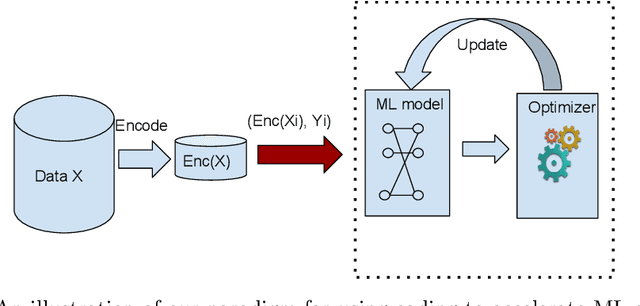
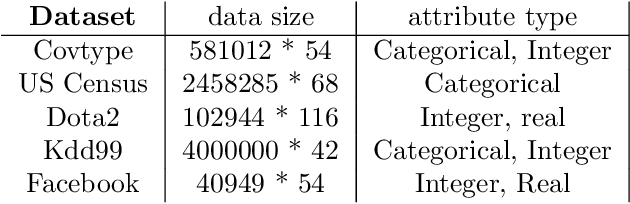
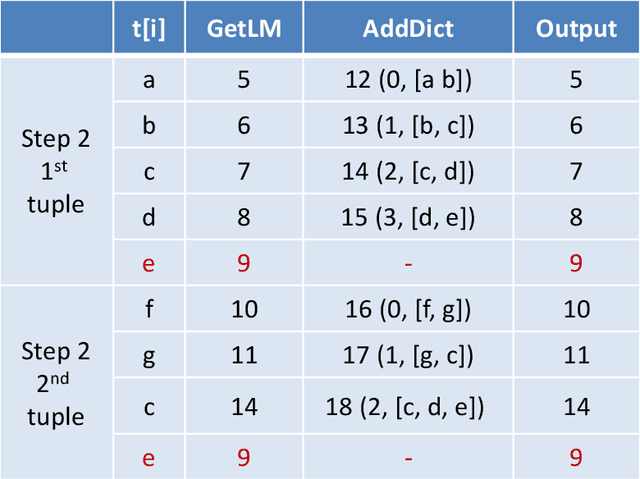

In this paper we study the use of coding techniques to accelerate machine learning (ML). Coding techniques, such as prefix codes, have been extensively studied and used to accelerate low-level data processing primitives such as scans in a relational database system. However, there is little work on how to exploit them to accelerate ML algorithms. In fact, applying coding techniques for faster ML faces a unique challenge: one needs to consider both how the codes fit into the optimization algorithm used to train a model, and the interplay between the model structure and the coding scheme. Surprisingly and intriguingly, our study demonstrates that a slight variant of the classical Lempel-Ziv-Welch (LZW) coding scheme is a good fit for several popular ML algorithms, resulting in substantial runtime savings. Comprehensive experiments on several real-world datasets show that our LZW-based ML algorithms exhibit speedups of up to 31x compared to a popular and state-of-the-art ML library, with no changes to ML accuracy, even though the implementations of our LZW variants are not heavily tuned. Thus, our study reveals a new avenue for accelerating ML algorithms using coding techniques and we hope this opens up a new direction for more research.