 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanorama: Fast-Track Nearest Neighbors
Oct 01, 2025Approximate Nearest-Neighbor Search (ANNS) efficiently finds data items whose embeddings are close to that of a given query in a high-dimensional space, aiming to balance accuracy with speed. Used in recommendation systems, image and video retrieval, natural language processing, and retrieval-augmented generation (RAG), ANNS algorithms such as IVFPQ, HNSW graphs, Annoy, and MRPT utilize graph, tree, clustering, and quantization techniques to navigate large vector spaces. Despite this progress, ANNS systems spend up to 99\% of query time to compute distances in their final refinement phase. In this paper, we present PANORAMA, a machine learning-driven approach that tackles the ANNS verification bottleneck through data-adaptive learned orthogonal transforms that facilitate the accretive refinement of distance bounds. Such transforms compact over 90\% of signal energy into the first half of dimensions, enabling early candidate pruning with partial distance computations. We integrate PANORAMA into state-of-the-art ANNS methods, namely IVFPQ/Flat, HNSW, MRPT, and Annoy, without index modification, using level-major memory layouts, SIMD-vectorized partial distance computations, and cache-aware access patterns. Experiments across diverse datasets -- from image-based CIFAR-10 and GIST to modern embedding spaces including OpenAI's Ada 2 and Large 3 -- demonstrate that PANORAMA affords a 2--30$\times$ end-to-end speedup with no recall loss.
When Lempel-Ziv-Welch Meets Machine Learning: A Case Study of Accelerating Machine Learning using Coding
Mar 01, 2017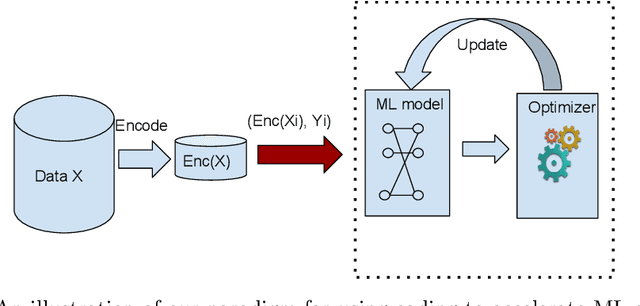
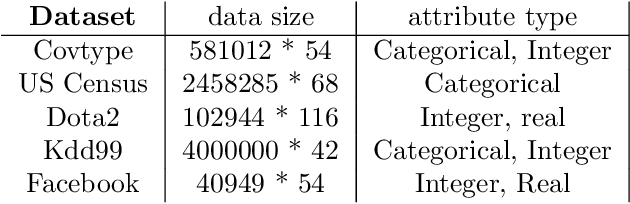
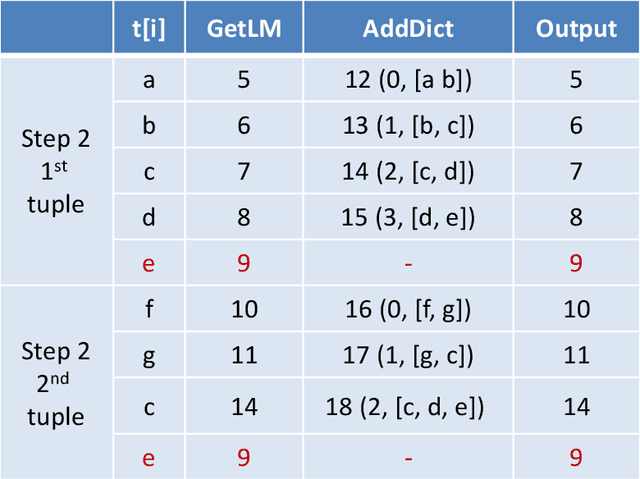

In this paper we study the use of coding techniques to accelerate machine learning (ML). Coding techniques, such as prefix codes, have been extensively studied and used to accelerate low-level data processing primitives such as scans in a relational database system. However, there is little work on how to exploit them to accelerate ML algorithms. In fact, applying coding techniques for faster ML faces a unique challenge: one needs to consider both how the codes fit into the optimization algorithm used to train a model, and the interplay between the model structure and the coding scheme. Surprisingly and intriguingly, our study demonstrates that a slight variant of the classical Lempel-Ziv-Welch (LZW) coding scheme is a good fit for several popular ML algorithms, resulting in substantial runtime savings. Comprehensive experiments on several real-world datasets show that our LZW-based ML algorithms exhibit speedups of up to 31x compared to a popular and state-of-the-art ML library, with no changes to ML accuracy, even though the implementations of our LZW variants are not heavily tuned. Thus, our study reveals a new avenue for accelerating ML algorithms using coding techniques and we hope this opens up a new direction for more research.