 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Linear Recurrent Models: How Different Gating Strategies Drive Selectivity and Generalization
Jan 18, 2026Linear recurrent neural networks have emerged as efficient alternatives to the original Transformer's softmax attention mechanism, thanks to their highly parallelizable training and constant memory and computation requirements at inference. Iterative refinements of these models have introduced an increasing number of architectural mechanisms, leading to increased complexity and computational costs. Nevertheless, systematic direct comparisons among these models remain limited. Existing benchmark tasks are either too simplistic to reveal substantial differences or excessively resource-intensive for experimentation. In this work, we propose a refined taxonomy of linear recurrent models and introduce SelectivBench, a set of lightweight and customizable synthetic benchmark tasks for systematically evaluating sequence models. SelectivBench specifically evaluates selectivity in sequence models at small to medium scale, such as the capacity to focus on relevant inputs while ignoring context-based distractors. It employs rule-based grammars to generate sequences with adjustable complexity, incorporating irregular gaps that intentionally violate transition rules. Evaluations of linear recurrent models on SelectivBench reveal performance patterns consistent with results from large-scale language tasks. Our analysis clarifies the roles of essential architectural features: gating and rapid forgetting mechanisms facilitate recall, in-state channel mixing is unnecessary for selectivity, but critical for generalization, and softmax attention remains dominant due to its memory capacity scaling with sequence length. Our benchmark enables targeted, efficient exploration of linear recurrent models and provides a controlled setting for studying behaviors observed in large-scale evaluations. Code is available at https://github.com/symseqbench/selectivbench
SymSeqBench: a unified framework for the generation and analysis of rule-based symbolic sequences and datasets
Dec 31, 2025Sequential structure is a key feature of multiple domains of natural cognition and behavior, such as language, movement and decision-making. Likewise, it is also a central property of tasks to which we would like to apply artificial intelligence. It is therefore of great importance to develop frameworks that allow us to evaluate sequence learning and processing in a domain agnostic fashion, whilst simultaneously providing a link to formal theories of computation and computability. To address this need, we introduce two complementary software tools: SymSeq, designed to rigorously generate and analyze structured symbolic sequences, and SeqBench, a comprehensive benchmark suite of rule-based sequence processing tasks to evaluate the performance of artificial learning systems in cognitively relevant domains. In combination, SymSeqBench offers versatility in investigating sequential structure across diverse knowledge domains, including experimental psycholinguistics, cognitive psychology, behavioral analysis, neuromorphic computing and artificial intelligence. Due to its basis in Formal Language Theory (FLT), SymSeqBench provides researchers in multiple domains with a convenient and practical way to apply the concepts of FLT to conceptualize and standardize their experiments, thus advancing our understanding of cognition and behavior through shared computational frameworks and formalisms. The tool is modular, openly available and accessible to the research community.
Unlocking Layer-wise Relevance Propagation for Autoencoders
Mar 21, 2023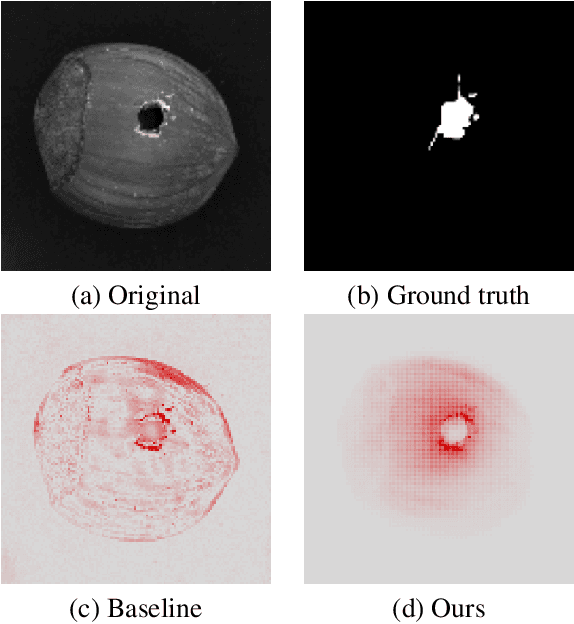
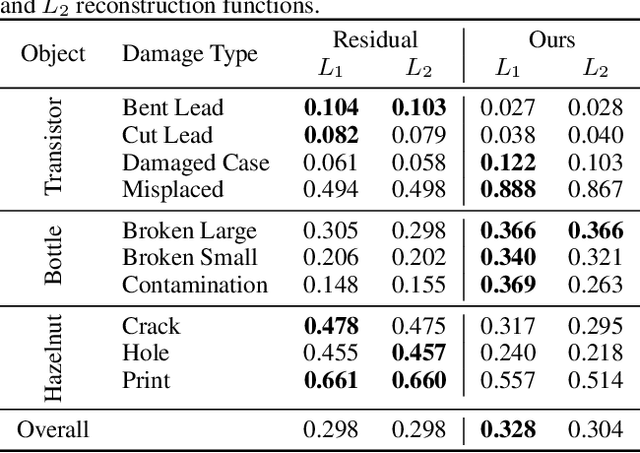
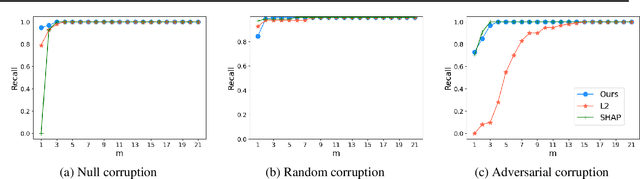
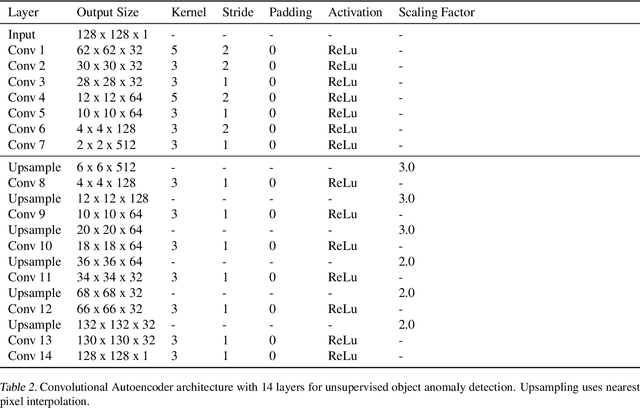
Autoencoders are a powerful and versatile tool often used for various problems such as anomaly detection, image processing and machine translation. However, their reconstructions are not always trivial to explain. Therefore, we propose a fast explainability solution by extending the Layer-wise Relevance Propagation method with the help of Deep Taylor Decomposition framework. Furthermore, we introduce a novel validation technique for comparing our explainability approach with baseline methods in the case of missing ground-truth data. Our results highlight computational as well as qualitative advantages of the proposed explainability solution with respect to existing methods.