 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Layer-wise Relevance Propagation for Autoencoders
Mar 21, 2023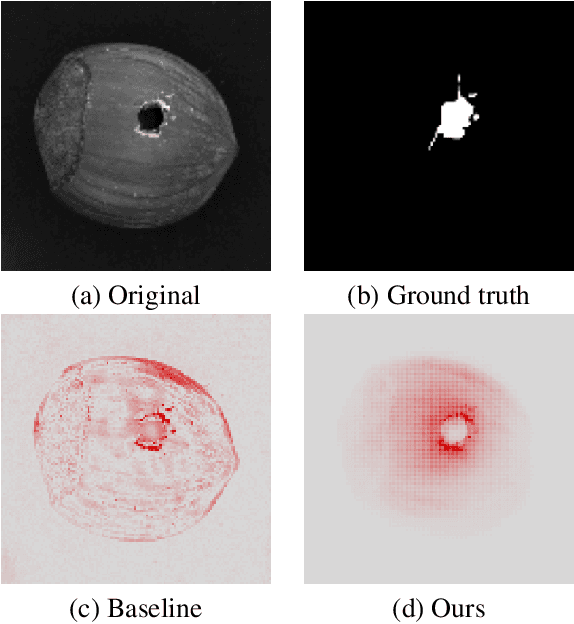
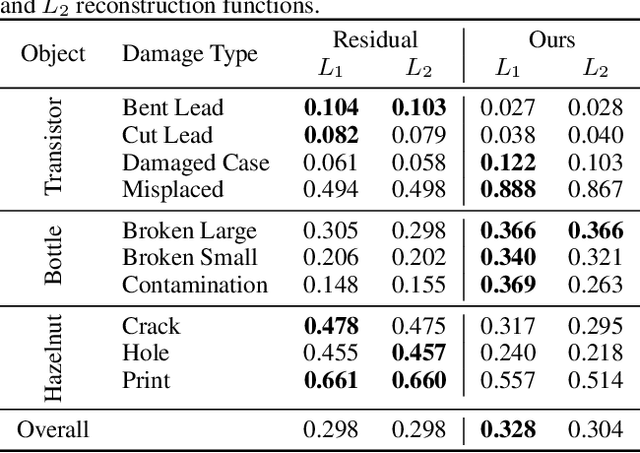
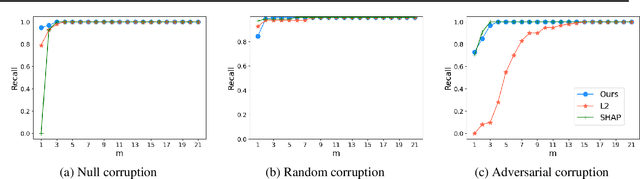
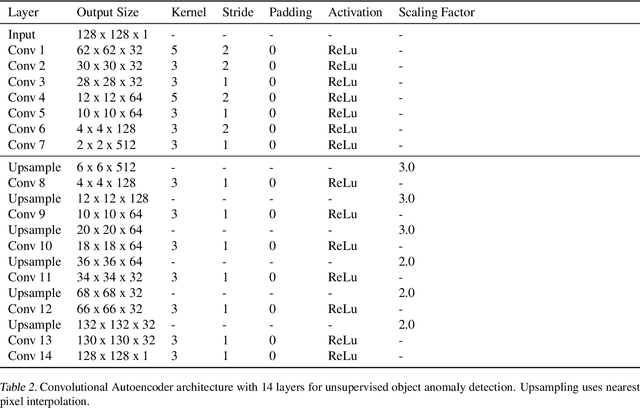
Autoencoders are a powerful and versatile tool often used for various problems such as anomaly detection, image processing and machine translation. However, their reconstructions are not always trivial to explain. Therefore, we propose a fast explainability solution by extending the Layer-wise Relevance Propagation method with the help of Deep Taylor Decomposition framework. Furthermore, we introduce a novel validation technique for comparing our explainability approach with baseline methods in the case of missing ground-truth data. Our results highlight computational as well as qualitative advantages of the proposed explainability solution with respect to existing methods.
Isometric Transformation Invariant Graph-based Deep Neural Network
Aug 21, 2018



Learning transformation invariant representations of visual data is an important problem in computer vision. Deep convolutional networks have demonstrated remarkable results for image and video classification tasks. However, they have achieved only limited success in the classification of images that undergo geometric transformations. In this work we present a novel Transformation Invariant Graph-based Network (TIGraNet), which learns graph-based features that are inherently invariant to isometric transformations such as rotation and translation of input images. In particular, images are represented as signals on graphs, which permits to replace classical convolution and pooling layers in deep networks with graph spectral convolution and dynamic graph pooling layers that together contribute to invariance to isometric transformation. Our experiments show high performance on rotated and translated images from the test set compared to classical architectures that are very sensitive to transformations in the data. The inherent invariance properties of our framework provide key advantages, such as increased resiliency to data variability and sustained performance with limited training sets. Our code is available online.
Noise generation for compression algorithms
Mar 24, 2018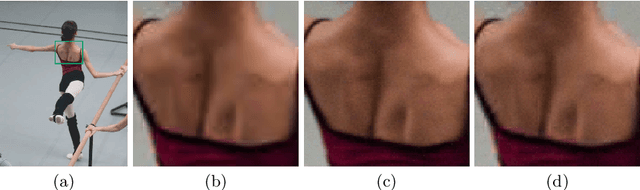
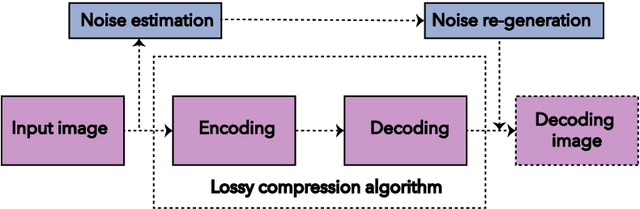
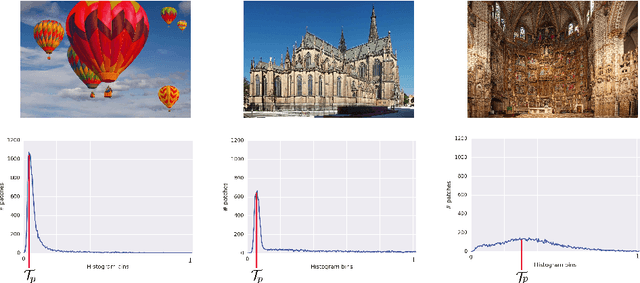
In various Computer Vision and Signal Processing applications, noise is typically perceived as a drawback of the image capturing system that ought to be removed. We, on the other hand, claim that image noise, just as texture, is important for visual perception and, therefore, critical for lossy compression algorithms that tend to make decompressed images look less realistic by removing small image details. In this paper we propose a physically and biologically inspired technique that learns a noise model at the encoding step of the compression algorithm and then generates the appropriate amount of additive noise at the decoding step. Our method can significantly increase the realism of the decompressed image at the cost of few bytes of additional memory space regardless of the original image size. The implementation of our method is open-sourced and available at https://github.com/google/pik.
Graph-Based Classification of Omnidirectional Images
Jul 26, 2017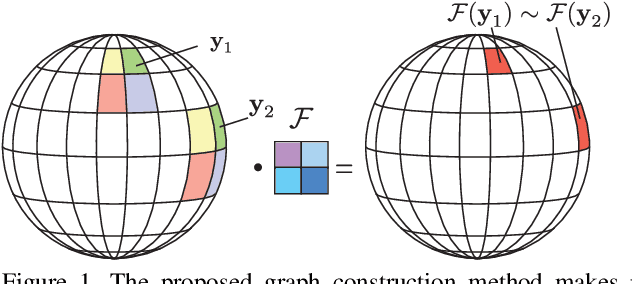

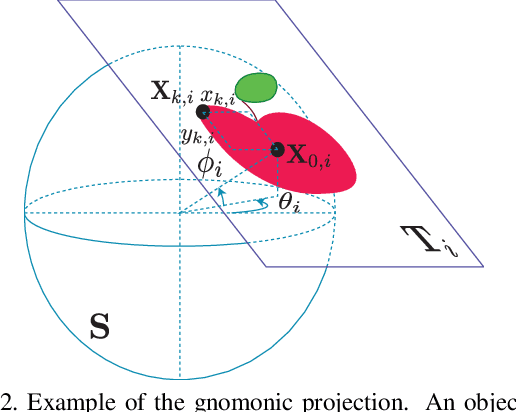
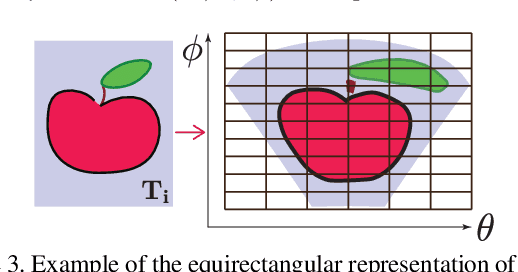
Omnidirectional cameras are widely used in such areas as robotics and virtual reality as they provide a wide field of view. Their images are often processed with classical methods, which might unfortunately lead to non-optimal solutions as these methods are designed for planar images that have different geometrical properties than omnidirectional ones. In this paper we study image classification task by taking into account the specific geometry of omnidirectional cameras with graph-based representations. In particular, we extend deep learning architectures to data on graphs; we propose a principled way of graph construction such that convolutional filters respond similarly for the same pattern on different positions of the image regardless of lens distortions. Our experiments show that the proposed method outperforms current techniques for the omnidirectional image classification problem.
Graph-based Isometry Invariant Representation Learning
Mar 01, 2017



Learning transformation invariant representations of visual data is an important problem in computer vision. Deep convolutional networks have demonstrated remarkable results for image and video classification tasks. However, they have achieved only limited success in the classification of images that undergo geometric transformations. In this work we present a novel Transformation Invariant Graph-based Network (TIGraNet), which learns graph-based features that are inherently invariant to isometric transformations such as rotation and translation of input images. In particular, images are represented as signals on graphs, which permits to replace classical convolution and pooling layers in deep networks with graph spectral convolution and dynamic graph pooling layers that together contribute to invariance to isometric transformations. Our experiments show high performance on rotated and translated images from the test set compared to classical architectures that are very sensitive to transformations in the data. The inherent invariance properties of our framework provide key advantages, such as increased resiliency to data variability and sustained performance with limited training sets.
Multi-modal image retrieval with random walk on multi-layer graphs
Jul 12, 2016
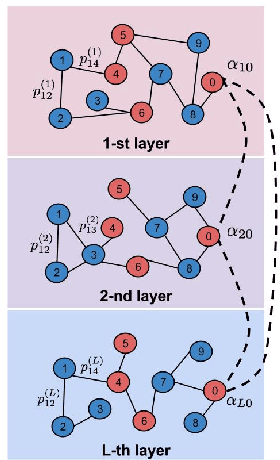

The analysis of large collections of image data is still a challenging problem due to the difficulty of capturing the true concepts in visual data. The similarity between images could be computed using different and possibly multimodal features such as color or edge information or even text labels. This motivates the design of image analysis solutions that are able to effectively integrate the multi-view information provided by different feature sets. We therefore propose a new image retrieval solution that is able to sort images through a random walk on a multi-layer graph, where each layer corresponds to a different type of information about the image data. We study in depth the design of the image graph and propose in particular an effective method to select the edge weights for the multi-layer graph, such that the image ranking scores are optimised. We then provide extensive experiments in different real-world photo collections, which confirm the high performance of our new image retrieval algorithm that generally surpasses state-of-the-art solutions due to a more meaningful image similarity computation.